这一周来,要说 AI 界最为热闹的莫过于 ChatGPT 了。刚推出一周的时间,注册用户竟然达到了 100 万。自 ChatGPT 推出后,不过短短几天,用户如蜂拥般地去注册,把玩这个能在一周左右吸粉 百来万的现下5网红。
前提准备
由于种种原因,访问 openAI 需要使用科学上网。
- 具备
科学上网的工具,注意:香港 ip 是 100% 无效的,当然最好是 美国 ip。 - 有一个能接受验证码的国外手机号码,这一点,并不是所有都有的,我就没有,那该怎么办呢?关于这一点,可接着往下看
注册虚拟号码,您也就慢慢清楚标题中的1块5是花在这里了。
注册虚拟号码
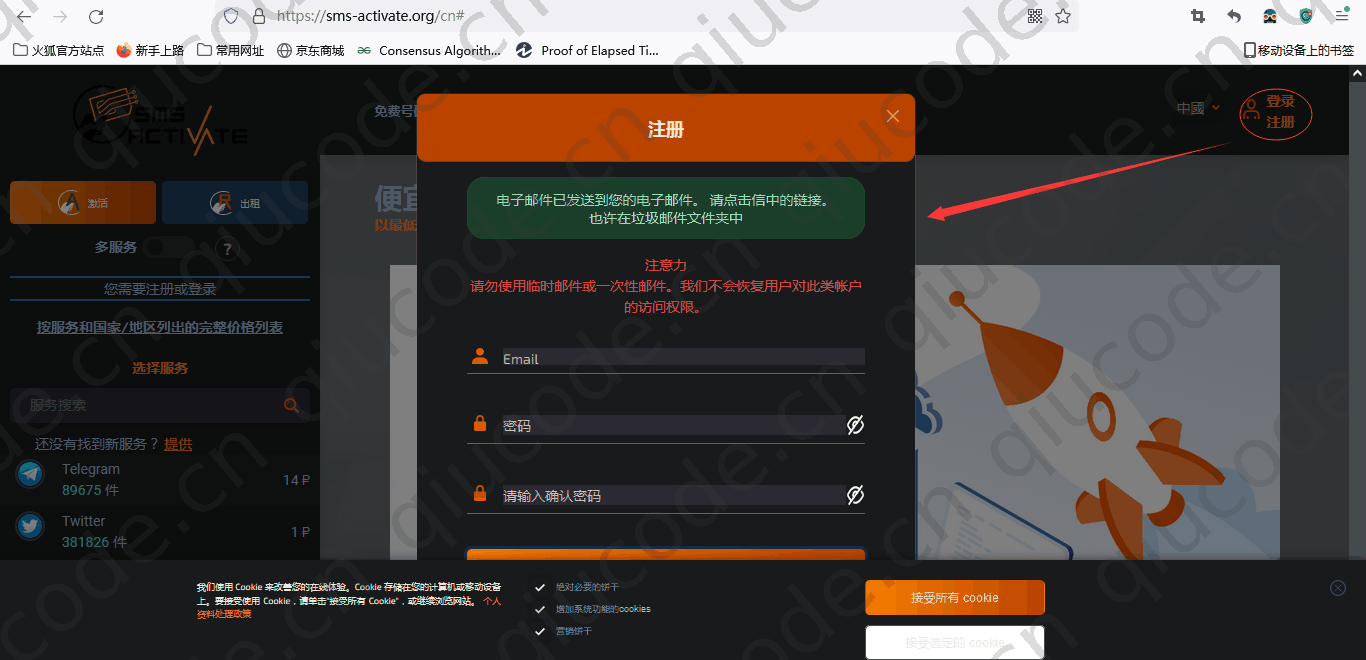
首先打开 https://sms-activate.org/ 进行注册虚拟号码。
我们先注册个账号,需通过填写的邮箱进行验证账号。
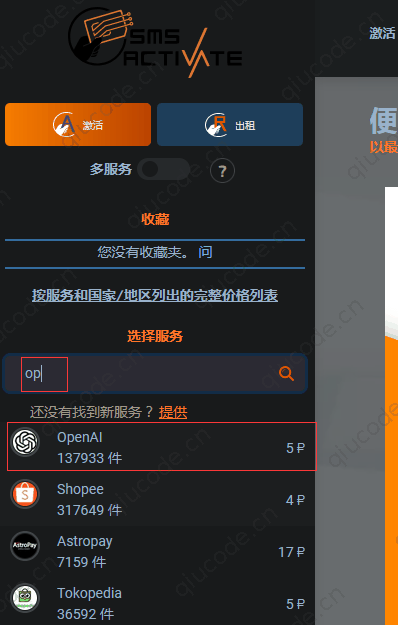
这时,我们在该页面左侧选择服务下的输入框,输入op,即会出现自动补全下拉框,毫无疑问,我们选择第一个OpenAI。
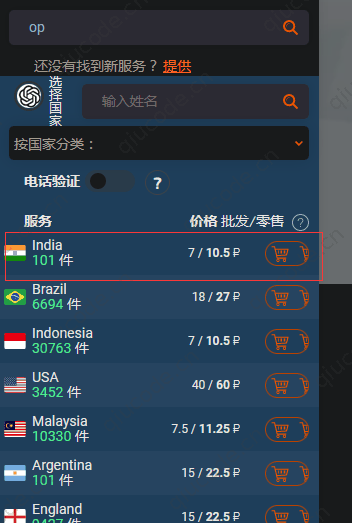
在我们选择了OpenAI后,也就是点选了OpenAI,下面出现所有国家的,当然,我们还是选择第一个,原因嘛,那就是它便宜啊,只需10.5P(10.5卢布)。
而在我们点击了那个 购物车 图标时,出现错误提醒,那便是,你的 余额是 0,需要充值,才能购买。

点击 左上角 人头图标,再列出的下拉框,再次点击充值。

在点击 充值 选项时,这时,页面列出很多 支付方式,往下滚动直找到 支付宝。
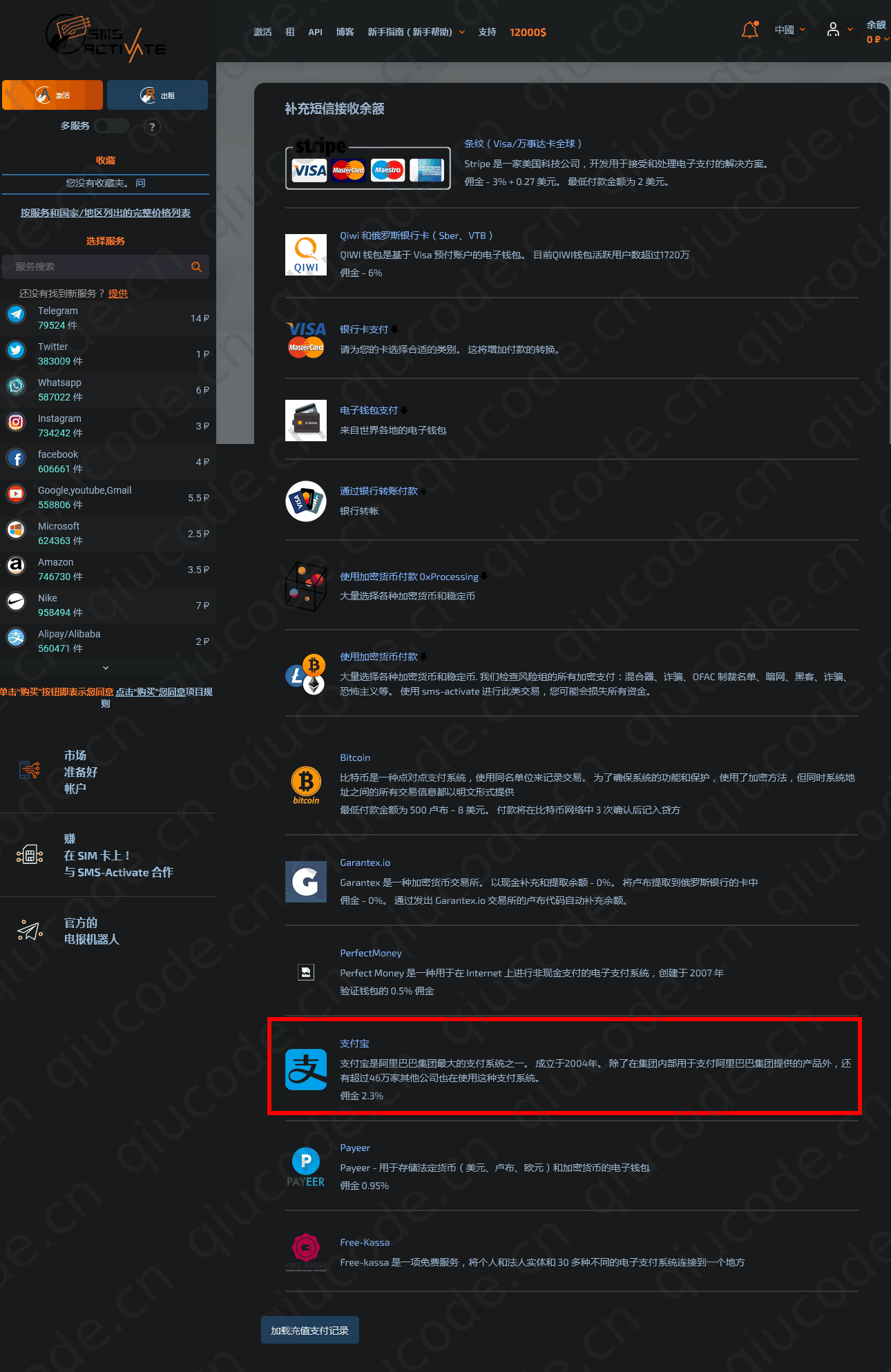
这里是使用 美元 做为单位,我们充0.2美元足够了,而 0.2 美元在当下当时兑换成人民币是 1.47 元,1块5还不到。
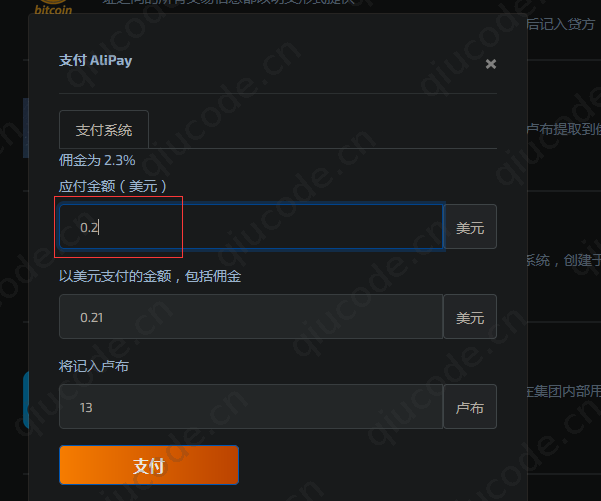
支付宝 扫码支付。
注册 OpenAI 账号
如果在注册OpenAI 账号时,出现了以下提示,那么说明科学上网是局部,需 全局 科学上网。
注册OpenAI一部分是通过 邮箱 进行验证,另一部分则是通过 手机号码 接受验证 再次验证。
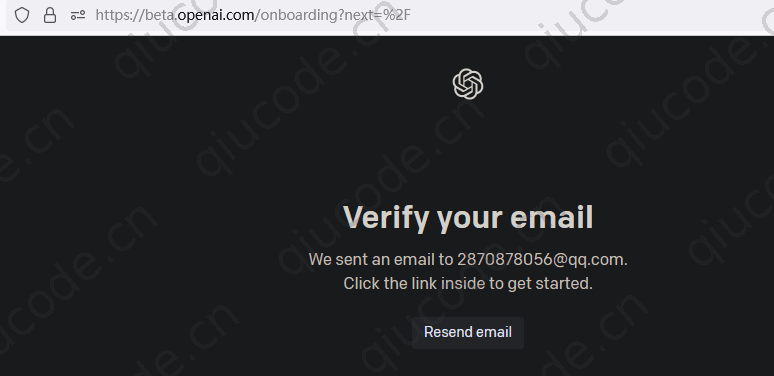
填写接收的邮箱验证,进入下一步 手机号码 验证。
我们拷贝刚刚购买的虚拟手机号码。
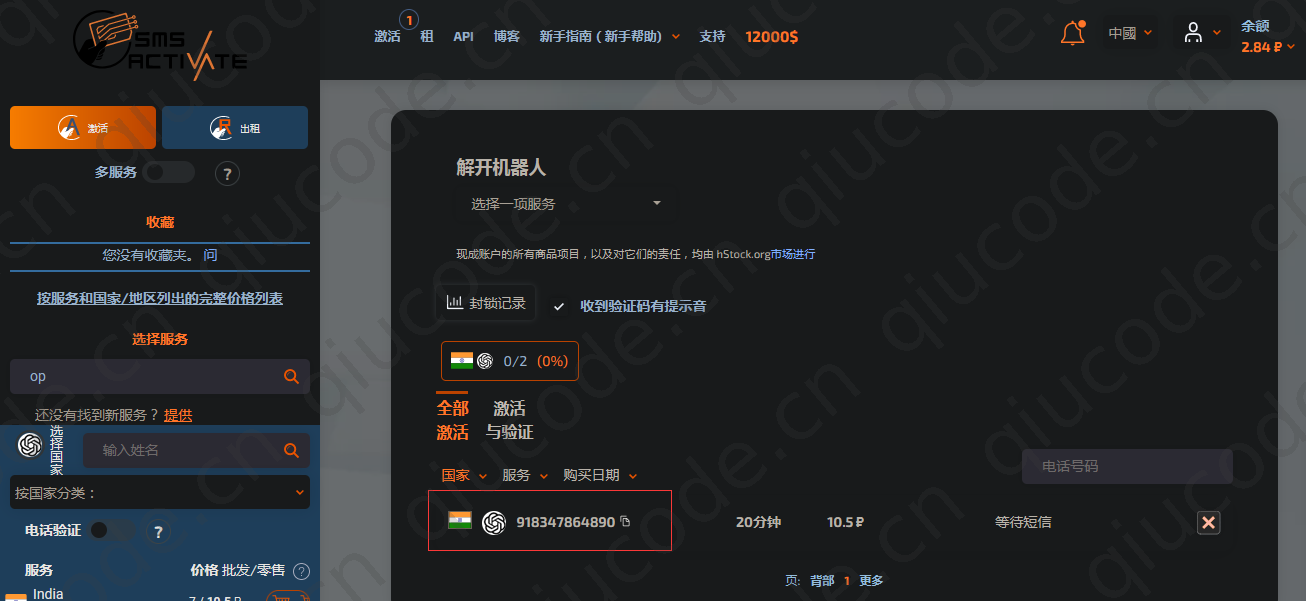
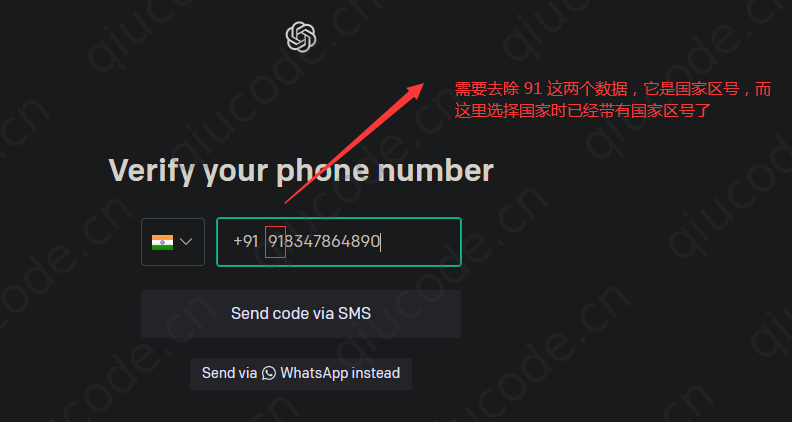
回到虚拟号码平台,若是没看到验证码,可以刷新下页面就出来了。

拷贝接收的验证码黏贴到OpenAI,注册完成,出现下面页面那就成功了。
登陆 OpenAI
我们重写打开个页签,输入 https://chat.openai.com/auth/login,现在总算可以玩一把现下最火的网红 AI 了。

填入刚刚注册的OpenAI账号。
登陆成功界面,久违的ChatGPT页面就展现在你的眼前,接下来就可以把玩了。
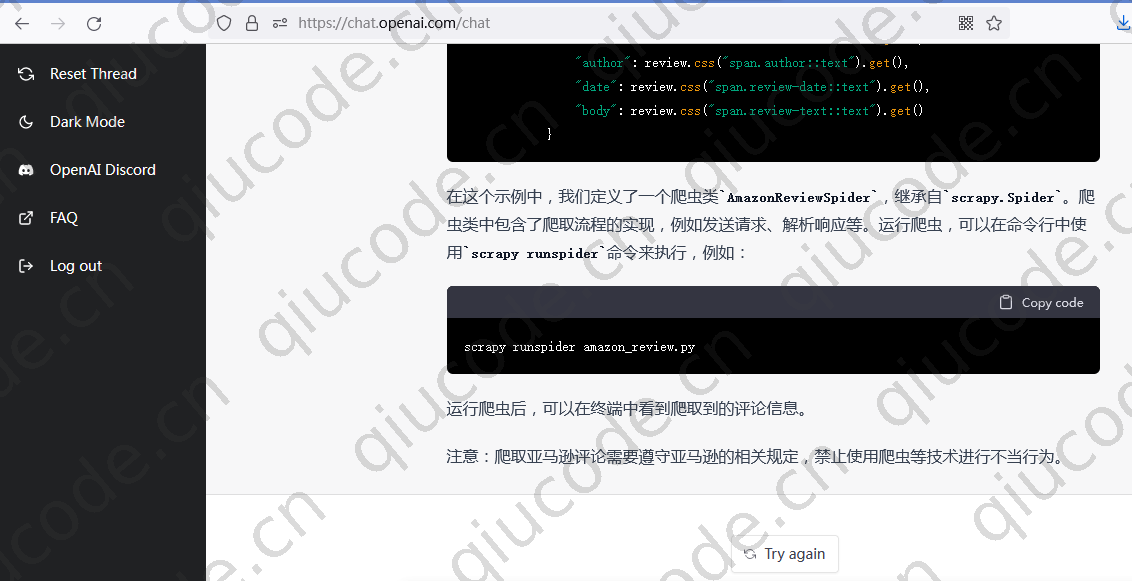
让 ChatGPT 帮你写爬取 Amazon 数据
我们在输入框输入些内容,看看 ChatGPT 能给我们什么样的答案?
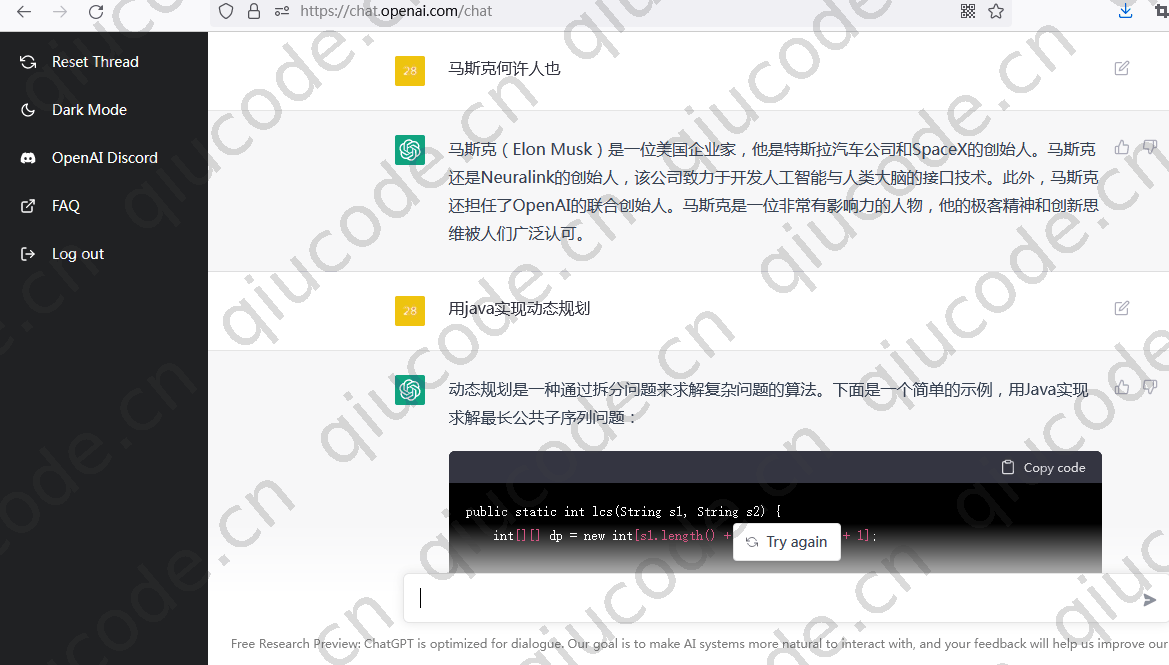
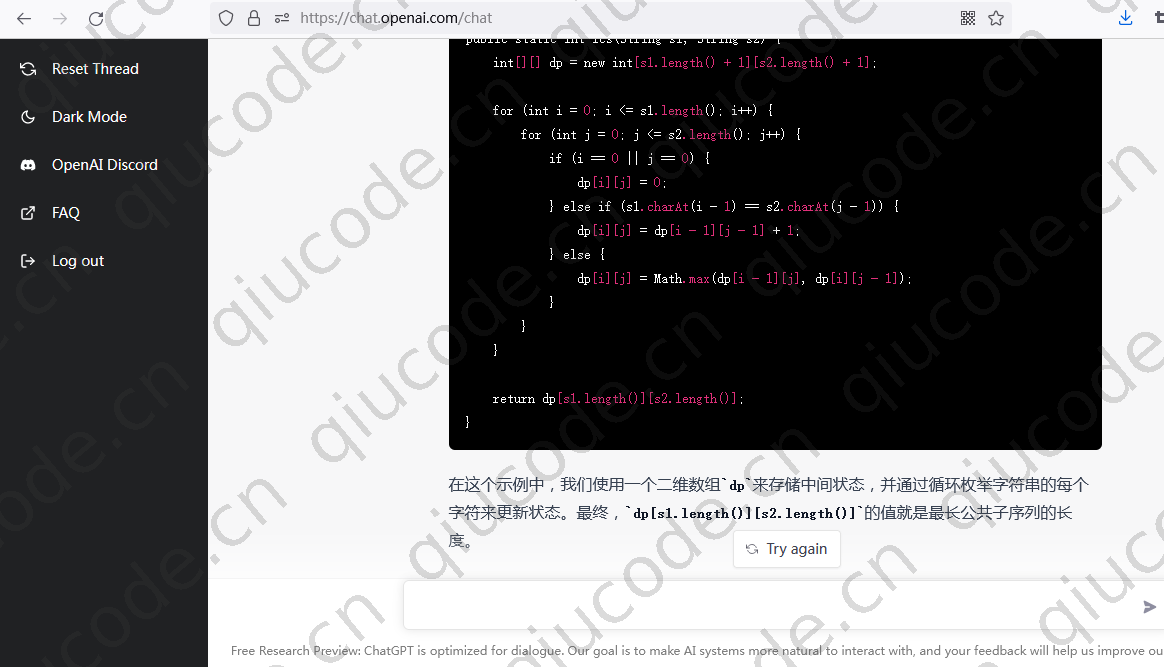
ChatGPT 用 java 实现的动态规划。
public static int lcs(String s1, String s2) {
int[][] dp = new int[s1.length() + 1][s2.length() + 1];
for (int i = 0; i <= s1.length(); i++) {
for (int j = 0; j <= s2.length(); j++) {
if (i == 0 || j == 0) {
dp[i][j] = 0;
} else if (s1.charAt(i - 1) == s2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[s1.length()][s2.length()];
}
我们在输入框输入使用python爬取亚马逊评论数据看看效果又会是什么呢?
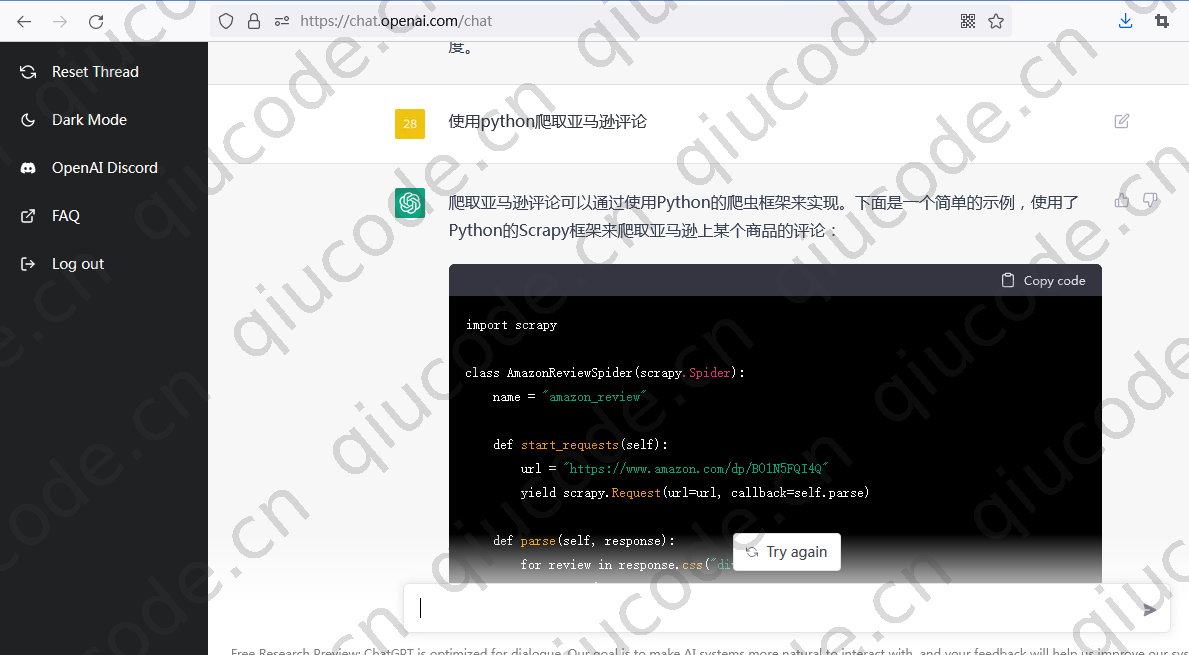
import scrapy
class AmazonReviewSpider(scrapy.Spider):
name = "amazon_review"
def start_requests(self):
url = "https://www.amazon.com/dp/B01N5FQI4Q"
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
for review in response.css("div.review"):
yield {
"rating": review.css("span.review-rating::text").get(),
"title": review.css("a.review-title::text").get(),
"author": review.css("span.author::text").get(),
"date": review.css("span.review-date::text").get(),
"body": review.css("span.review-text::text").get()
}