
在上一篇,我们初步了解什么是机器学习,以及它能给我们带来,相对于传统编程解决更为优先、易于维护的一套解决方案。那么,本文将继续为您举例,机器学习给我们生活上带来哪些便捷。
机器学习在现实中的示例
通过上一篇的讲解,我们多多少少对机器学习(“Machine Learning”)有了些许了解,同时也对机器学习(“Machine Learning”)一词不再那么抗拒了。
那么,机器学习到底在现实生活为我们解决哪些难题呢?亦或是传统方案目前无法实现的。
1、可以分析生产线上的产品图像,并对其进行分类。这属于
图像分类范畴,通常是使用卷积神经网络(CNN),亦或是Transformer。2、 可以用于对脑部检测是否存在肿瘤。这便是
图像语义分割,图像中的每个像素都被分类 (因为我们想要确定肿瘤的确切位置和形状),通常是使用卷积神经网络(CNN),亦或是Transformer。3、对新闻文章进行自动分类。这属于
自然语言处理(NLP)范畴,更为具体地应该是文本分类。虽然可以使用循环神经网络(RNN)和卷积神经网络来解决,但显然Transformer处理的效果更好。4、自动标记恶意评论。这也是
文本分类范畴,处理的方案也是选用NLP工具。5、自动总结长文档。这好比去阅读短篇小说,而后总结出讲了什么故事?或者是故事情节脉络。这是
NLP的一个分支,称为文本摘要,同样也是使用NLP工具进行处理。6、搭建
聊天机器人或个人助理。这就涉及到诸多NLP组成部分,包括自然语言理解(NLU)和问答模块。7、根据大量绩效指标来预测公司明年的盈利情况。这属于一个
回归任务(即预测值),可以使用任何回归模型(regression model,)来解决,诸如线性回归( linear regression)、多项式回归(polynomial regression)模型。如果您考虑过去绩效指标的序列,您则会使用RNN、CNN和Transformer。8、应用程序对语音命令做出反应。这是
语音识别,需要处理音频样本,这些样本都是长而复杂的序列,通常使用RNN、CNN和Transformer来处理。9、检测信用卡欺诈。这属于
异常检测。可以使用隔离森林(isolation forests)、高斯混合模型(Gaussian mixture models)和自动编码器(autoencoders)。10、根据购买情况对客户进行细分,进而为每个细分市场做出不同的营销策略。这便是
聚类(clustering),可以使用k-means、DBSCAN等来实现。11、使用图表来表示复杂的高维度数据集。这是
数据可视化,通常涉及到降维技术。12、根据客户过去的购买情况推荐出感兴趣的产品。这属于
推荐系统。一种方法是将过去的购买行为(以及有关客户的其他信息)输入到人工神经网络(ANN),并让它输出最有可能的下一次购买行为。 该神经网络通常会根据所有客户过去的购买顺序进行训练。13、为游戏创建智能机器人。这通常可以使用
强化学习(RL)来解决,它是机器学习的一个分支,训练代理(例如机器人)来选择随着时间的推移最大化其奖励的操作(例如,机器人可能会获得奖励) 每当玩家在给定环境(例如游戏)内失去一些生命值时。 在围棋比赛中击败世界冠军的著名AlphaGo程序就是使用RL构建的。
当然,这个示例列表可以一直列下去,但希望它能让您感受到机器学习可以处理的任务令人难以置信的广度和复杂性,并且 您将用于每项任务的技术类型。
机器学习系统的类型
机器学习系统种类繁多,但可以根据以下这些标准大致分出几大类,它远不止限于此。
- 1、在它们训练期间如何受到监督,可细分为,包括但不限于
监督、无监督、半监督以及自我监督等等。 - 2、在它们训练期间是否可以即时增量学习,可分为
在线学习和批量学习。 - 3、它们的工作方式是简单地将
新数据点和已知数据点进行比较呢?还是通过检查数据训练中的模式并构建预测模型来工作呢?这样可分为基于实例的学习和模型的学习。
当然咯,这些标准并不是固化不变的,您总是可以按您自己喜欢的任何方式随意的组合它们。就拿垃圾邮件过滤器来说明吧!它可以使用深度神经网络(deep neural network)模型进行动态学习,该模型人类提供的垃圾邮件和样本数据进行训练,这使其成为一个在线、基于模型的监督学习系统。
训练监督
机器学习系统可以根据训练期间受到的监督数量和类型进行划分。有很多类别,但目前只讲讲监督、无监督、自我监督、半监督以及强化学习。
监督学习(Supervised learning)
在监督学习中,提供给算法的训练集包括所需的解决方案,则称为标签。
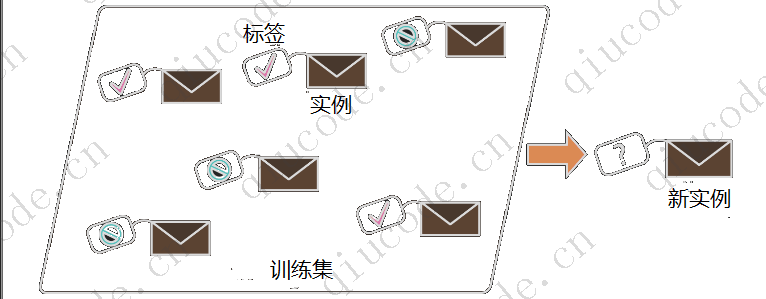
垃圾邮件过滤器接受了很多电子邮件及其分类(垃圾邮件)的训练,并且它必须学习该如何对新邮件进行分类。
也可以根据一组特征(里程、车龄以及品牌等)来预测目标值。为了训练,您需要为其提供很多汽车示例,包括它们的功能和价格。这种任务称为回归。
注意:某些
回归模型也可用于分类,反之亦然。逻辑回归( logistic regression)通常用于分类,因为它可以输出与给定类别的概率相对应的值(例如:垃圾邮件概率为20%)

回归问题:给定一个输入特征,预测一个值(通常有多个输入特征,有时有多个输出值)。
无监督学习(Unsupervised learning)
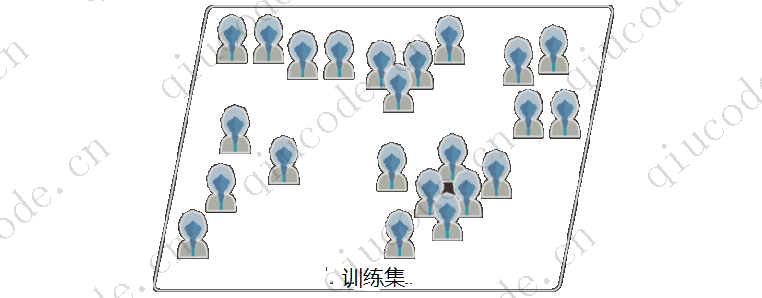
在无监督学习中,训练数据是不需要标记的。该系统试图在没有老师的情况下进行学习。
假设您有大量有关博客访问者的数据,您可能需要运行聚类算法来尝试检测相似访问这组。而您永远也不会告诉算法访问这属于哪个组,它无需您的任何协助即可找到这些链接。它可能会注意到,40% 的访问者是喜欢漫画书并通常在放学后阅读您的博客的青少年,而 20% 是喜欢科幻小说并在周末访问的成年人。如果您使用了层次聚类算法(hierarchical clustering algorithm),它还可能将每个组细分为更小的组, 这可以帮助您针对每个组定位您的帖子。
(用于无监督学习的未标记训练集)
(聚类)

可视化算法也是一个无监督学习的好例子。您向它们提供大量复杂且未标记的数据,它们可以轻松输出绘制数据的 2D 或 3D 表示形式。 这些算法尝试保留尽可能多的结构(例如,尝试保持输入空间中的单独簇在可视化中不重叠),以便您可以了解数据的组织方式,并可能识别出意想不到的模式。
一个相关的任务是降维,其目标是简化数据而不丢失太多信息。 实现这一目标的一种方法是将多个相关特征合并为一个。 例如,一辆车的行驶里程可能与其车龄密切相关,因此降维算法会将它们合并为一个代表汽车磨损情况的特征, 这称为特征提取。

在将
训练数据提供给另一个机器学习算法(例如监督学习算法)之前,尝试使用降维算法来减少训练数据的维数通常是一个好主意。 它将运行得更快,数据将占用更少的磁盘和内存空间,并且在某些情况下它也可能表现得更好。
异常检测也是一项无监督任务。例如,检测异常的信用卡交易以防止欺诈、发现制造缺陷,或者在将数据输入另一个学习算法之前自动从数据集中删除异常值。 系统在训练期间显示的大部分是正常实例,因此它学会识别它们; 然后,当它看到一个新实例时,它可以判断它是否看起来像正常实例,或者是否可能存在异常。
一个非常相似的任务是新颖性检测:它的目的是检测看起来与训练集中的所有实例不同的新实例。 这需要有一个非常“干净”的训练集, 您希望算法检测的任何实例。 例如,如果您有数千张狗的图片,其中 1% 代表吉娃娃,那么新颖性检测算法不应将吉娃娃的新图片视为新颖性。另一方面,异常检测算法可能会认为这些狗非常罕见,并且与其他狗如此不同,因此它们可能会将它们归类为异常(无意冒犯吉娃娃)。
(异常检测)

关联规则学习(association rule learning)是一个常见的无监督任务,其目标是挖掘大量数据并发现属性之间有趣的关系。 例如,假设您拥有一家超市。 在销售日志上运行关联规则可能会发现购买烧烤酱和薯片的人也倾向于购买牛排。 因此,您可能希望将这些物品彼此靠近放置。
半监督学习(Semi-supervised learning)
由于标记数据通常既耗时又昂贵,因此您通常会有大量未标记的实例,而很少有标记的实例。 一些算法可以处理部分标记的数据。 这称为半监督学习。

图中,具有两个类(三角形和正方形)的半监督学习:未标记的示例(圆圈)有助于将新实例(十字)分类为三角形类而不是正方形类,即使它更接近标记的正方形
例如,一些照片托管服务(Google Photos),将照片上传到该服务后,它会自动识别出同一个人 A 出现在照片 1、5 和 11 中,而另一个人 B 出现在照片 2、5 和 7 中。这是算法的无监督部分(聚类)。 现在系统需要的只是您告诉它这些人是谁。 只需为每个人添加一个标签,它就能为每张照片中的每个人命名,这对于搜索照片很有用。
大多数半监督学习算法是无监督和监督算法的组合。 例如,可以使用聚类算法将相似的实例分组在一起,然后可以用其聚类中最常见的标签来标记每个未标记的实例。 一旦整个数据集被标记,就可以使用任何监督学习算法。
自我监督学习 (Self-supervised learning)
机器学习的另一种方法实际上涉及从完全未标记的数据集生成完全标记的数据集。 同样,一旦整个数据集被标记,就可以使用任何监督学习算法。 这种方法称为自我监督学习。 例如,如果您有大量未标记图像的数据集,则可以随机屏蔽每个图像的一小部分,然后训练模型来恢复原始图像。 在训练过程中,蒙版图像用作模型的输入,原始图像用作标签。
(左图作为 输入,右图是 输出)

生成的模型本身可能非常有用,例如,修复损坏的图像或从图片中删除不需要的对象。 但通常情况下,使用自我监督学习训练的模型并不是最终目标。 您通常需要针对稍微不同的任务(您真正关心的任务)调整和微调模型。
假设您真正想要的是有一个宠物分类模型:给定任何宠物的图片,它会告诉您它属于什么物种。 如果您有大量未标记的宠物照片数据集,则可以首先使用自我监督学习来训练图像修复模型。 一旦表现良好,它应该能够区分不同的宠物种类:当它修复一张脸部被遮住的猫的图像时,它必须知道不要添加狗的脸。
假设您的模型架构允许(大多数神经网络架构都允许),那么就可以调整模型,使其预测宠物物种而不是修复图像。 最后一步 包括在标记 数据集上微调模型:模型已经知道猫、狗和其他宠物物种的样子,因此只需要这一步,以便模型可以学习它已经知道的物种与我们期望从中获得的标签之间的映射。
将知识从一项任务迁移到另一项任务称为
迁移学习,它是当下机器学习中最重要的技术之一,特别是在使用深度神经网络(即由多层神经元组成的神经网络)时。
有些人认为自监督学习是无监督学习的一部分,因为它处理完全未标记的数据集。 但自我监督学习在训练过程中使用(生成的)标签,因此在这方面它更接近监督学习。 无监督学习通常用于处理聚类、降维或异常检测等任务,而自我监督学习则专注于与监督学习相同的任务:主要是分类和回归。 简而言之,最好将自我监督学习视为一个单独的类别。
强化学习(Reinforcement learning )
强化学习是一种非常不同的机器学习。 学习系统在本文中称为代理,可以观察环境、选择和执行操作,并获得回报(或以负奖励形式进行惩罚)。 然后,它必须自行学习什么是最好的策略(称为策略),以便随着时间的推移获得最大的回报。 策略定义了代理在给定情况下应该选择什么操作。

例如,许多机器人采用强化学习算法来学习如何行走。 DeepMind 的 AlphaGo 程序也是强化学习的一个很好的例子:它在 2017 年 5 月的围棋比赛中击败了当时世界排名第一的柯洁,登上了新闻头条。 它通过分析数百万场比赛,然后与自己进行许多比赛来了解其获胜策略。 请注意,在与冠军的比赛中学习被关闭; AlphaGo 只是应用了它学到的策略。
 2023-07-15 10:18:38 +0800 +0800
2023-07-15 10:18:38 +0800 +0800