
随着时间的推移,模型也需做出相应的变化。但就采用新数据与旧数据一起训练,势必需要耗费更多的资源,为了解决这一状况,本文带您了解,关于新数据该如何训练?
批量与在线学习
用于对机器学习系统进行分类的另一个标准是系统可以从输入数据流中增量学习。
批量学习
在批量学习中,系统无法增量学习:必须使用所有可用数据进行训练。 这通常需要大量时间和计算资源,因此通常是离线完成的。 首先对系统进行训练,然后将其投入生产并运行,无需再学习; 它只是应用它所学到的东西。 这就是所谓的离线学习。
不幸的是,模型的性能往往会随着时间的推移而缓慢衰减,这仅仅是因为世界在不断发展,而模型却保持不变。 这种现象通常称为模型腐烂或数据漂移。 解决方案是定期使用最新数据重新训练模型。 您需要执行此操作的频率取决于用例:如果模型对猫和狗的图片进行分类,其性能将下降非常缓慢,但如果模型处理快速发展的系统,例如对金融市场进行预测, 那么它可能会很快衰减。
注意:
即使是一个被训练用来对猫狗图片进行分类的模型,也可能需要定期重新训练,这并不是因为猫狗会在一夜之间发生变异,而是因为摄像头不断变化,图像格式、清晰度、亮度和尺寸比例也会随之变化。此外,明年人们可能会喜欢不同的品种,或者他们可能会决定给他们的宠物戴上小帽子,谁知道呢?
如果您希望批量学习系统了解新数据(例如新型垃圾邮件),则需要在完整数据集(不仅是新数据,还包括旧数据)上从头开始训练新版本的系统 ),然后用新型号替换旧型号。 幸运的是,训练、评估和启动机器学习系统的整个过程可以相当容易地实现自动化,因此即使是批量学习系统也可以适应变化。 只需根据需要更新数据并从头开始训练新版本的系统。
此解决方案很简单,通常效果很好,但使用全套数据进行训练可能需要几个小时,因此您通常每 24 小时甚至每周训练一次新系统。 如果您的系统需要适应快速变化的数据(例如,预测股票价格),那么您需要更具反应性的解决方案。
此外,对全套数据进行训练需要大量的计算资源(CPU、内存空间、磁盘空间、磁盘 I/O、网络 I/O 等)。 如果你有大量数据,并且每天让系统自动化从头开始训练,最终会花费你很多钱。 如果数据量巨大,甚至可能无法使用批量学习算法。
最后,如果您的系统需要能够自主学习并且资源有限(例如智能手机应用程序或火星上的漫游车),则需要携带大量训练数据并占用大量资源,每次训练几个小时。
在所有这些情况下,更好的选择是使用能够增量学习的算法。
在线学习
在在线学习中,您可以通过按顺序(单独或以称为小批量的小组形式)向系统提供数据实例来增量训练系统。 每个学习步骤都是快速且廉价的,因此系统可以在新数据到达时即时学习。
(在在线学习中,模型经过训练并投入生产,然后随着新数据的进入而不断学习)

在线学习对于需要适应极快变化的系统非常有用(例如,检测股票市场的新模式)。 如果您的计算资源有限,这也是一个不错的选择; 例如,如果模型是在移动设备上训练的。
此外,在线学习算法可用于在无法容纳一台机器主内存的庞大数据集上训练模型(这称为核外学习)。 该算法加载部分数据,对该数据运行训练步骤,然后重复该过程,直到对所有数据运行完毕。

在线学习系统的一个重要参数是它们适应不断变化的数据的速度:这称为学习率(learning rate)。 如果您设置较高的学习率,那么您的系统将快速适应新数据````,但它也会很快忘记旧数据(并且您不希望垃圾邮件过滤器仅标记显示的最新类型的垃圾邮件) )。 反之,如果设置的学习率```较低,系统就会有较大的惯性; 也就是说,它的学习速度会更慢,但对新数据中的噪声或非代表性数据点(异常值)序列也不太敏感。
核外学习(Out-of-core learning )通常是离线完成的(即不在实时系统上),因此在线学习可能是一个令人困惑的名称。 将其视为````增量学习```(incremental learning)。
在线学习的一个巨大挑战是,如果将不良数据输入系统,系统的性能将会下降,而且可能会很快下降(取决于数据质量和学习率)。 如果它是一个实时系统,您的客户会注意到。 例如,不良数据可能来自错误(例如,机器人上的传感器故障),也可能来自试图欺骗系统的人(例如,向搜索引擎发送垃圾邮件以试图在搜索结果中排名靠前)。 为了降低这种风险,您需要密切监控系统,并在检测到性能下降时立即关闭学习(并可能恢复到之前的工作状态)。 您可能还想监视输入数据并对异常数据做出反应; 例如,使用异常检测算法。
基于实例与基于模型的学习
对机器学习系统进行分类的另一种方法是通过它们如何进行归纳。大多数机器学习任务都是关于做出预测的。这意味着,给定一定数量的训练样本,系统需要能够对以前从未见过的样本做出很好的预测(推广到)。在训练数据上有一个好的性能度量是好的,但还不够;真正的目标是在新实例上表现良好。 泛化的方法主要有两种:基于实例的学习和基于模型的学习。
基于装置的学习
也许最琐碎的学习方式就是用心学习。如果以这种方式创建垃圾邮件过滤器,它只会标记所有与用户已经标记的邮件相同的电子邮件–这不是最糟糕的解决方案,但肯定不是最好的解决方案。
而不是仅仅标记电子邮件是相同的已知垃圾邮件,你的垃圾邮件过滤器可以编程,也标志电子邮件是非常类似已知的垃圾邮件。这需要衡量两封电子邮件之间的相似性。两封电子邮件之间的一个(非常基本的)相似性度量可以是计算它们共有的单词数。如果电子邮件与已知的垃圾邮件有许多共同之处,系统就会将其标记为垃圾邮件。
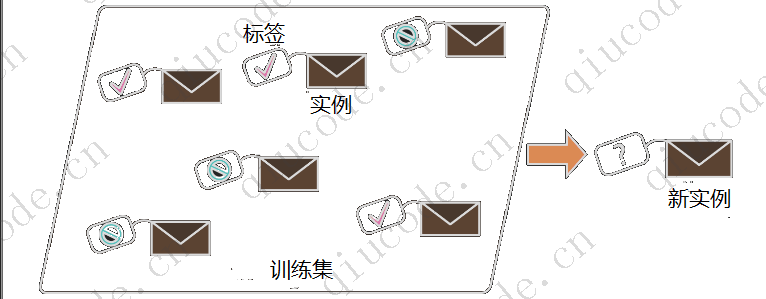
这被称为基于实例的学习:系统通过记忆学习示例,然后通过使用相似性度量将它们与所学习的示例(或其中的子集)进行比较,从而推广到新的案例。例如,在图1-16中,新实例将被归类为三角形,因为大多数最相似的实例都属于该类。

基于模型的学习和典型的机器学习工作流
从一组例子中进行归纳的另一种方法是建立这些例子的模型,然后使用该模型进行预测。这就是所谓的基于模型的学习。

例如,假设您想知道金钱是否能让人快乐,因此您从 OECD 网站下载了美好生活指数数据以及世界银行有关人均国内生产总值 (GDP) 的统计数据。 然后连接表格并按人均 GDP 排序。


这里似乎确实有一个趋势! 尽管数据存在噪声(即部分随机),但看起来生活满意度随着国家人均 GDP 的增加或多或少呈线性上升。 因此,您决定将生活满意度建模为人均 GDP 的线性函数。 此步骤称为模型选择:您选择了仅具有一个属性的生活满意度线性模型,即人均 GDP。
life_satisfaction = θ0 + θ1 × GDP_per_capita
该模型有两个模型参数,θ0 和 θ1.4 通过调整这些参数,您可以使您的模型表示任何线性函数。

在使用模型之前,您需要定义参数值 θ0 和 θ1。您如何知道哪些值将使您的模型表现最佳? 要回答这个问题,您需要指定一个绩效衡量标准。 您可以定义一个效用函数(或适应度函数)来衡量模型的好坏,也可以定义一个成本函数来衡量模型的糟糕程度。 对于线性回归问题,人们通常使用成本函数来衡量线性模型的预测与训练示例之间的距离; 目标是最小化这个距离。
这就是线性回归算法的用武之地:您向其提供训练示例,它会找到使线性模型最适合您的数据的参数。 这称为训练模型。 在我们的例子中,算法发现最佳参数值为 θ0 = 3.75 和 θ1 = 6.78 × 10–5。
令人困惑的是,“模型”一词可以指一种模型类型(例如,线性回归),也可以指完全指定的模型架构(例如,具有一个输入和一个输出的线性回归),或者指准备使用的最终训练模型 用于预测(例如,具有一个输入和一个输出的线性回归,使用
θ0 = 3.75和θ1 = 6.78 × 10–5)。 模型选择包括选择模型类型并充分指定其架构。 训练模型意味着运行算法来找到最适合训练数据的模型参数,并希望对新数据做出良好的预测。

import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
# 下载并准备数据
data_root = "https://github.com/ageron/data/raw/main/"
lifesat = pd.read_csv(data_root + "lifesat/lifesat.csv")
X = lifesat[["GDP per capita (USD)"]].values
y = lifesat[["Life satisfaction"]].values
# 可视化数据
lifesat.plot(kind='scatter', grid=True,x="GDP per capita (USD)", y="Life satisfaction")
plt.axis([23_500, 62_500, 4, 9])
plt.show()
# 选择一个线性模型模型
model = LinearRegression()
# 训练模型
model.fit(X, y)
# 为塞浦路斯做一个预测
X_new = [[37_655.2]] # 塞浦路斯的人均国内生产总值在2020年
print(model.predict(X_new)) # 输出:【【6.30165767】

如果您使用基于实例的学习算法,您会发现以色列的人均 GDP 最接近塞浦路斯(38,341 美元),并且由于 OECD 数据告诉我们以色列人的生活满意度为 7.2,您会得到 预测塞浦路斯的生活满意度为 7.2。 如果你把镜头缩小一点,看看两个最接近的国家,你会发现立陶宛和斯洛文尼亚,两者的生活满意度都是 5.9。 对这三个值进行平均,得到 6.33,这非常接近基于模型的预测。 这个简单的算法称为 k 最近邻回归(在本例中,k = 3)。
将前面代码中的线性回归模型替换为 k 最近邻回归就像替换这些行一样简单:
from sklearn.linear_model import LinearRegression model = LinearRegression()换成这两行:
from sklearn.neighbors import KNeighborsRegressor model = KNeighborsRegressor(n_neighbors=3)
如果一切顺利,您的模型将做出良好的预测。 如果没有,您可能需要使用更多属性(就业率、健康状况、空气污染等),获取更多或质量更好的训练数据,或者选择更强大的模型(例如多项式回归模型)。
总之:
- 您研究了数据。
- 您选择了一个型号。
- 您使用训练数据对其进行训练(即,学习算法搜索最小化成本函数的模型参数值)。
- 最后,您应用该模型对新案例进行预测(这称为 • 推理),希望该模型能够很好地泛化。
到目前为止,我们已经涵盖了很多内容:您现在知道机器学习的真正含义、为什么有用、ML 系统的一些最常见类别是什么,以及典型的项目工作流程是什么样的。 现在让我们看看学习中可能会出现哪些问题并妨碍您做出准确的预测。
 2023-07-17 21:22:38 +0800 +0800
2023-07-17 21:22:38 +0800 +0800 2023-07-15 10:18:38 +0800 +0800
2023-07-15 10:18:38 +0800 +0800