
在此保留验证过程之后,您可以在完整的训练集(包括验证集)上训练最佳模型,这将为您提供最终模型。在这种情况下,需要记住的最重要的规则是,验证集和测试集都必须尽可能具有生产中预期使用的数据的代表性,因此它们应该完全由有代表性的图片组成:您可以对它们进行洗牌,将一半放在验证集中,另一半放在测试集中(确保在这两个集合中都没有重复或接近重复的数据)。在网络图片上对模型进行培训之后,如果您观察到模型在验证集上的性能令人失望,您将不知道这是因为您的模型超出了培训集,还是仅仅是由于网络图片和移动应用程序图片之间的不匹配。
测试和验证
了解模型对新案例的推广效果的唯一方法是在新案例上进行实际尝试。 一种方法是将模型投入生产并监控其性能。 这很有效,但如果你的模型非常糟糕,你的用户会抱怨——这不是最好的主意。
更好的选择是将数据分为两组:训练集和测试集。顾名思义,您使用训练集训练模型,并使用测试集测试模型。 新案例的错误率称为泛化错误(或样本外错误),通过在测试集上评估模型,您可以获得此错误的估计值。 该值告诉您模型在以前从未见过的实例上的表现如何。
如果训练误差较低(即您的模型在训练集上很少犯错误)但泛化误差较高,则意味着您的模型过度拟合训练数据
通常使用 80% 的数据进行训练,保留 20% 的数据进行测试。 然而,这取决于数据集的大小:如果它包含 1000 万个实例,那么保留 1% 意味着您的测试集将包含 100,000 个实例,可能足以很好地估计泛化误差。
超参数调整和模型选择
评估模型非常简单:只需使用测试集即可。 但是假设您在两种类型的模型(例如线性模型和多项式模型)之间犹豫不决:您如何在它们之间做出决定? 一种选择是训练两者并比较它们使用测试集的泛化程度。
现在假设线性模型概括得更好,但您想要应用一些正则化以避免过度拟合。 问题是,如何选择正则化超参数的值? 一种选择是使用该超参数的 100 个不同值来训练 100 个不同的模型。 假设您找到了生成具有最低泛化误差(例如,只有 5% 误差)的模型的最佳超参数值。 您将此模型投入生产,但不幸的是它的性能没有达到预期,并产生 15% 的错误。 刚刚发生了什么?
问题在于您在测试集上多次测量了泛化误差,并且您调整了模型和超参数以生成针对该特定集的最佳模型。 这意味着该模型不太可能在新数据上表现良好。
此问题的常见解决方案称为保留验证(如下图):您只需保留部分训练集即可评估多个候选模型并选择最佳模型。 新保留的集合称为验证集(或开发集或开发集)。 更具体地说,您在简化的训练集(即完整训练集减去验证集)上训练具有各种超参数的多个模型,然后选择在验证集上表现最佳的模型。 在此保留验证过程之后,您可以在完整的训练集(包括验证集)上训练最佳模型,这将为您提供最终模型。 最后,您在测试集上评估最终模型,以获得泛化误差的估计。

这种解决方案通常效果相当好。但是,若验证集过小,则模型评估将不精确:您可能最终错误地选择了一个次优模型。相反,如果验证集太大,则剩余的训练集将比完整的训练集小得多。为什么这样不 好?那么,由于最终的模型将在完整的训练集上训练,所以比较在一个小得多的训练集上训练的候选模型是不理想的。这就像选择跑得最快的短跑选手参加马拉松比赛一样。解决这个问题的一个方法是执行重复的交叉验证,使用许多小的验证集。在对其余数据进行训练后,每个模型在每个验证集评估一次。通过对模型的所有评估进行平均化,您可以更准确地衡量模型的性能。然而,有一个缺点:训练时间乘以验证集的数量。
数据不匹配
在某些情况下,很容易获得大量数据进行训练,但这些数据可能无法完美代表生产中使用的数据。 例如,假设您想要创建一个移动应用程序来拍摄花朵照片并自动确定其种类。 您可以轻松地在网络上下载数百万张鲜花照片,但它们并不能完全代表在移动设备上使用该应用程序实际拍摄的照片。 也许您只有 1,000 张代表性照片(即实际使用该应用拍摄的照片)。
在这种情况下,需要记住的最重要的规则是,验证集和测试集都必须尽可能具有生产中预期使用的数据的代表性,因此它们应该完全由有代表性的图片组成:您可以对它们进行洗牌,将一半放在验证集中,另一半放在测试集中(确保在这两个集合中都没有重复或接近重复的数据)。在网络图片上对模型进行培训之后,如果您观察到模型在验证集上的性能令人失望,您将不知道这是因为您的模型超出了培训集,还是仅仅是由于网络图片和移动应用程序图片之间的不匹配。
一个解决方案是将一些训练图片(来自网络)放在另一个集合中,AndrewNg称之为训练-开发集合(如下图)。在训练模型之后(在训练集上,而不是在train-dev集上),您可以在train-dev集上评估它。如果模 型表现不佳,那么它一定是过拟合了训练集,所以你应该尝试简化或正则化模型,获取更多的训练数据,并清理训练数据。但是,如果它在train-dev集中表现良好,那么您可以在dev集中评估模型。如果它的性能很差,那么问题一定是来自数据不匹配。你可以尝试通过预处理网页图片来解决这个问题,使它们看起来更像移动应用程序将要拍摄的图片,然后再训练模型。一旦您拥有了一个在train-dev集和dev集上都表现良好的模型,您可以在测试集上最后一次评估它,以了解它在生产中的表现可能有多好

图中所示。当真实数据稀缺时(右),您可以使用类似的丰富数据(左)进行训练,并在train-dev集中保留一部分数据以评估过拟合;然后使用真实数据评估数据不匹配(dev集)并评估最终模型的性能(测试集)。
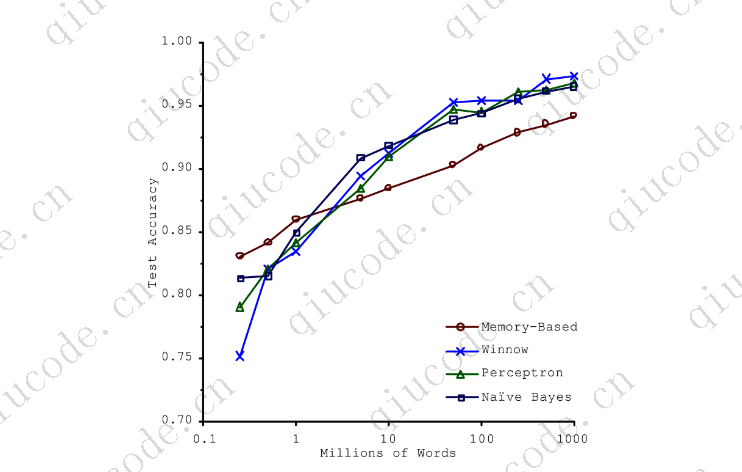
##### 没有免费的午餐定理模型是数据的简化表示。简化是为了抛弃那些不太可能推广到新实例的多余细节。当您选择一个特定类型的模型时,您隐含地对数据进行假设。例如,如果您选择一个线性模型,您就隐含地假设数据基本上是线性的,并且实例和直线之间的距离仅仅是噪声,可以安全地忽略它。
在1996年的一篇著名论文中,?David Wolpert证明,如果你对数据完全不做任何假设,那么就没有理由喜欢一个模型胜过任何其他模型。这就是所谓的“没有免费的午餐”(NFL)定理。对于一些数据集,最好的模型是线性模型,而对于其他数据集,它是一个神经网络。没有一个模型是先验保证更好地工作(因此定理的名称)。确定哪种模型最好的唯一方法是评估所有模型。由于这是不可能的,在践中你对数据做一些合理的假设,只评估几个合理的模型。例如,对于简单的任务,您可以评估各种级别的正则化线性模型,而对于复杂的问题,您可以评估各种神经网络。
练习
我们介绍了机器学习中的一些最重要的概念。 在接下来的研习中,我们将更深入地研究并编写更多代码,但在此之前,请确保您可以回答以下问题:
- 1、.您如何定义机器学习?
- 2、您能说出它最擅长的四种应用类型吗?
- 3、什么是标记训练集?
- 4、最常见的两种监督任务是什么?
- 5、你能说出四种常见的无监督任务吗?
- 6、你会使用什么类型的算法来让机器人在各种未知地形中行走?
- 7、您将使用什么类型的算法将客户分为多个组?
- 8、您会将垃圾邮件检测问题定义为监督学习问题还是无监督学习问题?
- 9、什么是在线学习系统?
- 10、什么是核外学习?
- 11、 什么类型的算法依赖相似性度量来进行预测?
- 12、模型参数和模型超参数有什么区别?
- 13、基于模型的算法搜索什么? 他们为了成功最常用的策略是什么? 他们如何做出预测?
- 14、您能说出机器学习的四个主要挑战吗?
- 15、 如果您的模型在训练数据上表现良好,但对新实例的泛化效果很差,会发生什么情况? 您能说出三种可能的解决方案吗?
- 16、什么是测试集,为什么要使用它?
- 17、 验证集的目的是什么?
- 18、什么是train-dev集,什么时候需要它,如何使用它?
- 19、 如果使用测试集调整超参数会出现什么问题?
 2023-08-13 15:12:38 +0800 +0800
2023-08-13 15:12:38 +0800 +0800 2023-07-28 21:12:38 +0800 +0800
2023-07-28 21:12:38 +0800 +0800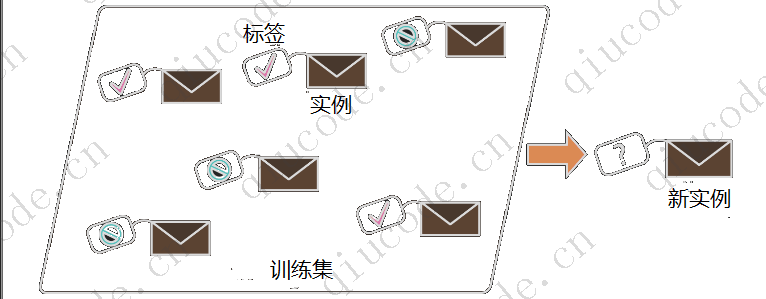 2023-07-17 21:22:38 +0800 +0800
2023-07-17 21:22:38 +0800 +0800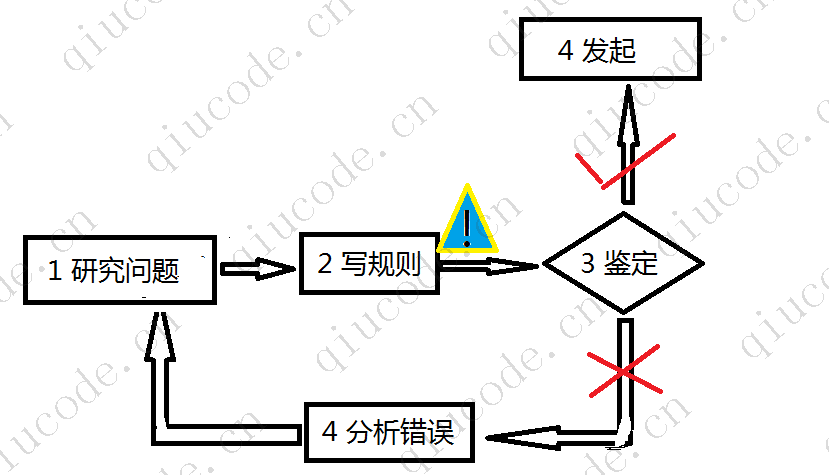 2023-07-15 10:18:38 +0800 +0800
2023-07-15 10:18:38 +0800 +0800