
Transformation Pipelines
有许多数据转换步骤需要以正确的顺序执行。幸运的是,Scikit-Learn提供了Pipeline类来帮助处理这样的转换序列。下面是一个用于数值属性的小管道,它首先对输入特性进行归并,然后对输入特性进行缩放:
from sklearn.pipeline import Pipeline
num_pipeline = Pipeline([
("impute", SimpleImputer(strategy="median")),
("standardize", StandardScaler()),
])
Pipeline构造函数采用名称/估算器对(2元组)的列表,定义了一系列步骤。名称可以是您喜欢的任何名称,只要它们是唯一的,并且不包含双下划线(__)。以后我们讨论超参数调优时,它们会很有用。估计器必须都是转换器(即,它们必须有一个fit_transform()方法),除了最后一个,它可以是任何东西:转换器、预测器或任何其他类型的估计器。
如果你不想命名transformers你可以使用 make_pipeline() 函数; 它将transformers作为位置参数,并使用transformers类的名称(小写且不带下划线)创建管道(例如,“simpleimputer”):
from sklearn.pipeline import make_pipeline
num_pipeline = make_pipeline(SimpleImputer(strategy="median"), StandardScaler())
如果多个transformers具有相同的名称,则会在其名称后附加索引(例如“foo-1”、“foo-2”等)。
当您调用管道的 fit() 方法时,它会在所有transformers上顺序调用 fit_transform(),将每个调用的输出作为参数传递给下一个调用,直到到达最终估计器,为此它只调用 fit() 方法。
该管道公开与最终估计器相同的方法。 在此示例中,最后一个估计器是 StandardScaler,它是一个transformers,因此管道也充当transformers。 如果您调用管道的transform()方法,它将按顺序将所有转换应用于数据。 如果最后一个估计器是预测器而不是变换器,那么管道将具有 Predict() 方法而不是 Transform() 方法。 调用它会按顺序将所有转换应用于数据并将结果传递给预测器的 Predict()方法
让我们调用管道的 fit_transform() 方法并查看输出的前两行,四舍五入到小数点后两位:

如前所述,如果要恢复一个漂亮的DataFrame,可以使用管道的get_feature_names_ out()方法:
df_housing_num_prepared = pd.DataFrame(
housing_num_prepared, columns=num_pipeline.get_feature_names_out(),
index=housing_num.index)
管道支持索引;例如,管道[1]返回管道中的第二个估计值,管道[:-1]返回一个包含除最后一个估计值以外的所有估计值的管道对象。您还可以通过steps属性(它是名称/估算器对的列表)或named_steps字典属性(它将名称映射到估算器)访问估算器。例如,num_line[“ simpleimputer”]返回名为“simpleimputer”的估计器。
到目前为止,我们已经分别处理了分类列和数值列。如果有一个能够处理所有列的转换器,将适当的转换应用到每一列,那会更方便。为此,您可以使用olumnTransformer。例如,下面的ColumnTransformer将把num_pipeline(我们刚刚定义的那个)应用于数字属性,把cat_pipeline应用于类别属性:
from sklearn.compose import ColumnTransformer
num_attribs = ["longitude", "latitude", "housing_median_age", "total_rooms",
"total_bedrooms", "population", "households", "median_income"]
cat_attribs = ["ocean_proximity"]
cat_pipeline = make_pipeline(
SimpleImputer(strategy="most_frequent"),
OneHotEncoder(handle_unknown="ignore"))
preprocessing = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", cat_pipeline, cat_attribs),
])
首先导入ColumnTransformer类,然后定义数字和分类列名的列表,并为分类属性构造一个简单的管道。最后,我们构造了一个列变换器。它的构造函数需要一个三元组(3-tuple)列表,每个三元组包含一个名称(必须是唯一的且不包含双下划线)、一个转换器和一个应该应用转换器的列的名称(或索引)列表。
由于列出所有的列名不是很方便,Scikit-Learn提供了一个make_column_selector()函数,该函数返回一个选择器函数,您可以使用它来自动选择给定类型的所有特性,例如数值型或类别型。可以将此选择器函数传递给ColumnTransformer,而不是传递给列名或索引。此外,如果您不关心命名转换器,可以使用make_column_transformer(),它为 您选择名称,就像make_pipeline()一样。例如,下面的代码创建了与前面相同的ColumnTransformer,只是转换器自动命名为“pipline-1”和“pipline-2”,而不是“num”和“cat”:
from sklearn.compose import make_column_selector, make_column_transformer
preprocessing = make_column_transformer(
(num_pipeline, make_column_selector(dtype_include=np.number)),
(cat_pipeline, make_column_selector(dtype_include=object)),
)
现在我们准备将此ColumnTransformer应用到住房数据:
housing_prepared = preprocessing.fit_transform(housing)
太好了!我们有一个预处理管道,用于获取整个训练数据集,并将每个转换器应用于适当的列,然后水平连接转换后的列。(变压器绝不能改变行数)。这再次返回一个NumPy数组,但是您可以使用preprocessing.get_feature_names_out()获得列名,并像我们之前所做的那样将数据包装在一个漂亮的DataFrame中。
你的项目进行得非常顺利,你几乎可以训练一些模型了!现在,您希望创建一个单一的管道,它将执行到目前为止您已经试验过的所有转换。让我们回顾一下管道将做什么,为什么:
- 数值特征中的缺失值将通过用中位数替换它们来填补,因为大多数ML算法不期望缺失值。在分类特征中,缺失值将被最频繁的类别替换。
- ·分类特征将是一热编码,因为大多数ML算法只接受数字输入。
- 。一些比率特征将被计算并添加:基岩比率、每栋房屋的容积比率和每栋房屋的人口比率。希望这些将更好地与房屋的中位数价值相关,从而帮助ML模型。
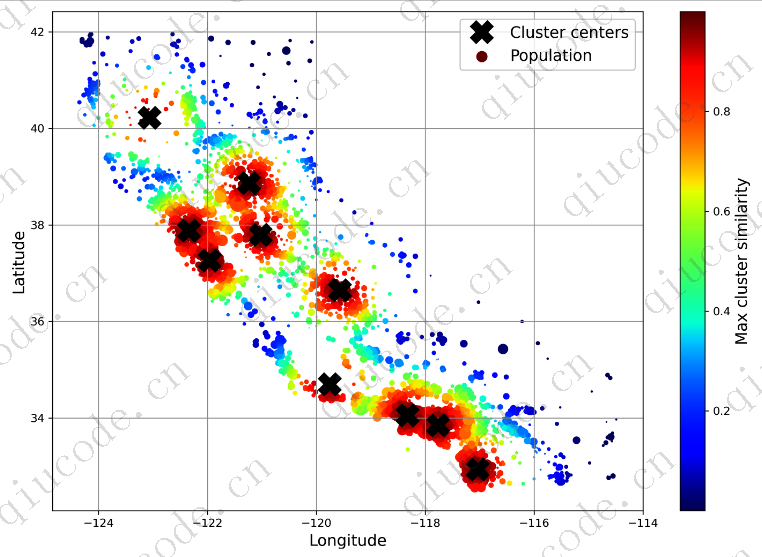
- 还将添加一些聚类相似性功能。这些可能比纬度和经度对模型更有用。
- 具有长尾的特征将被替换为它们的对数,因为大多数模型更喜欢具有大致均匀分布或高斯分布的特征。
- 所有数值特征都将被标准化,因为大多数ML算法喜欢所有特征具有大致相同的比例
构建完成所有这些工作的管道的代码现在应该看起来很熟悉了:
def column_ratio(X):
return X[:, [0]] / X[:, [1]]
def ratio_name(function_transformer, feature_names_in):
return ["ratio"] # feature names out
def ratio_pipeline():
return make_pipeline(
SimpleImputer(strategy="median"),
FunctionTransformer(column_ratio, feature_names_out=ratio_name),
StandardScaler())
log_pipeline = make_pipeline(
SimpleImputer(strategy="median"),
FunctionTransformer(np.log, feature_names_out="one-to-one"),
StandardScaler())
cluster_simil = ClusterSimilarity(n_clusters=10, gamma=1., random_state=42)
default_num_pipeline = make_pipeline(SimpleImputer(strategy="median"),
StandardScaler())
preprocessing = ColumnTransformer([
("bedrooms", ratio_pipeline(), ["total_bedrooms", "total_rooms"]),
("rooms_per_house", ratio_pipeline(), ["total_rooms", "households"]),
("people_per_house", ratio_pipeline(), ["population", "households"]),
("log", log_pipeline, ["total_bedrooms", "total_rooms", "population",
"households", "median_income"]),
("geo", cluster_simil, ["latitude", "longitude"]),
("cat", cat_pipeline, make_column_selector(dtype_include=object)),
],
remainder=default_num_pipeline) # one column remaining: housing_median_age
如果运行此ColumnTransformer,它将执行所有转换并输出具有24个特性的NumPy数组:

 2023-11-18 20:53:29 +0800 +0800
2023-11-18 20:53:29 +0800 +0800 2023-11-05 11:30:06 +0800 +0800
2023-11-05 11:30:06 +0800 +0800 2023-10-24 19:30:00 +0800 +0800
2023-10-24 19:30:00 +0800 +0800 2023-10-14 17:02:17 +0800 +0800
2023-10-14 17:02:17 +0800 +0800 2023-08-27 16:32:17 +0800 +0800
2023-08-27 16:32:17 +0800 +0800