
现在正处于百模乱战的时期,对于模型微调,想必您是有所了解了,毕竟国外的大语言模型一开源,国内便纷纷基于该模型进行微调,从而开始宣称领先于某某、超越了谁。可到头来,却让人发现他们套壳了国外大语言模型对外开放的API。
好了,我们不说国内各种大模型宣称超过了谁,毕竟,嘴巴长在别人脸上,我们管不了,也管不着,吹牛终将是会露馅的!
当我们需要对开源大模型进行微调时,看看有几种方法可以做到这一点的!
网格搜索
手动调整超参数,直到找到超参数值的完美组合。 这将是一项非常乏味的工作,而且您可能没有时间去探索多种组合。
相反,您可以使用 Scikit-Learn 的 GridSearchCV 类来搜索您。 您需要做的就是告诉它您希望它试验哪些超参数以及要尝试哪些值,它将使用交叉验证来评估超参数值的所有可能组合。 例如,以下代码搜索 RandomForestRegressor 的最佳超参数值组合:
from sklearn.model_selection import GridSearchCV
full_pipeline = Pipeline([ ("preprocessing", preprocessing), ("random_forest", RandomForestRegressor(random_state=42)), ])
param_grid = [{'preprocessing__geo__n_clusters': [5, 8, 10], 'random_forest__max_features': [4, 6, 8]},
{'preprocessing__geo__n_clusters': [10, 15], 'random_forest__max_features': [6, 8, 10]}, ]
grid_search = GridSearchCV(full_pipeline, param_grid, cv=3, scoring='neg_root_mean_squared_error')
grid_search.fit(housing, housing_labels)
请注意,您可以引用管道中任何估计器的任何超参数,即使该估计器嵌套在多个管道和列转换器的深处。 例如,当 Scikit-Learn 看到“preprocessing__geo__n_clusters”时,它会在双下划线处分割该字符串,然后在管道中查找名为“preprocessing”的估计器并找到预处理 ColumnTransformer。 接下来,它在此 ColumnTransformer 中查找名为“geo”的转换器,并找到我们在纬度和经度属性上使用的 ClusterSimilarity 转换器。 然后它找到该变压器的n_clusters超参数。 同样,random_forest__max_features指的是名为“random_forest”的估计器的max_features超参数,这当然是RandomForest模型。
这个param_grid中有两个字典,因此GridSearchCV将首先评估第一个字典中指定的n_clusters和max_features超参数值的所有3×3=9个组合,然后它将尝试第一个字典中指定的所有2×3=6个超参数值组合 第二个字典。 因此,网格搜索总共将探索 9 + 6 = 15 种超参数值组合,并且每个组合都会对管道进行 3 次训练,因为我们使用的是 3 折交叉验证。 这意味着总共将有 15 × 3 = 45 轮训练! 这可能需要一段时间,但是完成后您可以获得如下参数的最佳组合:
grid_search.best_params_ {'preprocessing__geo__n_clusters': 15, 'random_forest__max_features': 6}
您可以使用 grid_search.best_estimator_ 访问最佳估计器。 如果 GridSearchCV 使用refit=True(这是默认值)进行初始化,那么一旦它使用交叉验证找到最佳估计器,它就会在整个训练集上重新训练它。 这通常是一个好主意,因为向其提供更多数据可能会提高其性能。
评估分数可使用 grid_search.cv_results_ 获得。 这是一个字典,但如果将其包装在 DataFrame中,您将获得每个超参数组合和每个交叉验证分割的所有测试分数的良好列表,以及所有分割的平均测试分数:
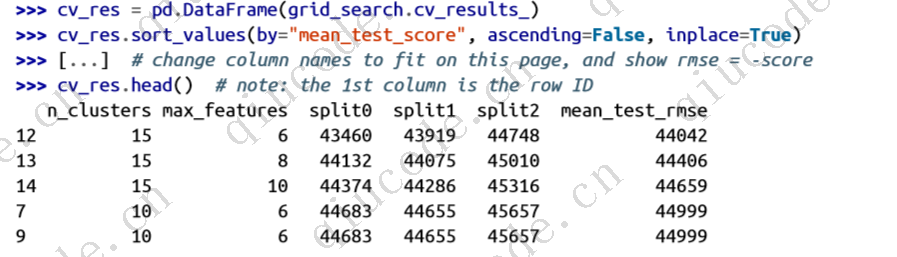
最佳模型的平均测试 RMSE 分数为 44,042,这比您之前使用默认超参数值获得的分数(47,019)要好。 恭喜,您已成功微调您的最佳模型!
随机搜索
当您探索相对较少的组合时(如前面的示例所示),网格搜索方法很好,但 RandomizedSearchCV 通常更可取,特别是当超参数搜索空间很大时。 该类的使用方式与 GridSearchCV 类大致相同,但它不是尝试所有可能的组合,而是评估固定数量的组合,在每次迭代时为每个超参数选择一个随机值。 这听起来可能令人惊讶,但这种方法有几个好处:
- 如果您的某些超参数是连续的(或离散的,但有许多可能的值),并且您让随机搜索运行例如 1,000 次迭代,那么它将为每个超参数探索 1,000 个不同的值,而网格搜索只会探索 您为每个值列出的几个值。
- 假设某个超参数实际上没有太大影响,但您还不知道。 如果它有 10 个可能的值,并将其添加到网格搜索中,那么训练时间将延长 10 倍。 但如果将其添加到随机搜索中,则不会有任何区别。
- 如果有6 个超参数需要探索,每个超参数都有10 个可能的值,那么网格搜索除了训练模型一百万次之外别无选择,而随机搜索始终可以运行您选择的任意次数的迭代。
对于每个超参数,您必须提供可能值的列表或概率分布:
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs = {'preprocessing__geo__n_clusters': randint(low=3, high=50), 'random_forest__max_features': randint(low=2, high=20)}
rnd_search = RandomizedSearchCV( full_pipeline, param_distributions=param_distribs, n_iter=10, cv=3, scoring='neg_root_mean_squared_error', random_state=42)
rnd_search.fit(housing, housing_labels)
Scikit-Learn 还具有 HalvingRandomSearchCV 和 HalvingGridSearchCV 超参数搜索类。 他们的目标是更有效地使用计算资源,要么更快地训练,要么探索更大的超参数空间。 它们的工作原理如下:在第一轮中,使用网格方法或随机方法生成许多超参数组合(称为“候选者”)。 然后,像往常一样,这些候选者被用来训练模型,并使用交叉验证进行评估。 然而,训练使用的资源有限,这大大加快了第一轮的速度。 默认情况下,“有限资源”意味着模型在训练集的一小部分上进行训练。 然而,其他限制也是可能的,例如,如果模型具有超参数来设置它,则减少训练迭代的次数。 一旦每个候选人都经过评估,只有最好的候选人才能进入第二轮,在那里他们将获得更多资源来竞争。 经过几轮之后,最终的候选人将使用全部资源进行评估。 这可能会节省您一些调整超参数的时间。
 2022-12-08 20:59:39 +0800 +0800
2022-12-08 20:59:39 +0800 +0800 2024-01-14 15:50:17 +0800 +0800
2024-01-14 15:50:17 +0800 +0800 2023-12-11 19:50:17 +0800 +0800
2023-12-11 19:50:17 +0800 +0800 2023-11-18 20:53:29 +0800 +0800
2023-11-18 20:53:29 +0800 +0800 2023-11-05 11:30:06 +0800 +0800
2023-11-05 11:30:06 +0800 +0800