
在上一篇我们已然训练了一个用于对数字图像识别的模型,但我们目前还不知道该模型在识别数字图像效率如何?所以,本文将对该模型进行评估。
使用交叉验证衡量准确性
评估模型的一个好方法是使用交叉验证,让我们使用cross_val_score()函数来评估我们的 SGDClassifier 模型,使用三折的 k 折交叉验证。k-fold 交叉验证意味着将训练集分成 k 个折叠(在本例中是三个),然后训练模型 k 次,每次取出一个不同的折叠进行评估:

当您看到这组数字,是不是感到很兴奋?毕竟所有交叉验证折叠的准确率(预测准确率)均超过了 95%。然而,在您兴奋于这组数字前,还是让我们来看看一个假分类器,它只是将每张图片归入最常见的类别,在本例中就是负类别(即非 5):
from sklearn.dummy import DummyClassifier
dummy_clf = DummyClassifier()
dummy_clf.fit(X_train, y_train_5)
print(any(dummy_clf.predict(X_train))) # prints False: no 5s detected
您能猜出这个模型的准确度吗?让我们一探究竟:

没错,它的准确率超过 90%!这只是因为只有大约 10% 的图片是 5,所以如果你总是猜测图片不是 5,你就会有大约 90% 的时间是正确的。比诺斯特拉达穆斯还准。
这说明了为什么准确率通常不是分类器的首选性能指标,尤其是在处理偏斜 数据集时(即某些类别的出现频率远高于其他类别)。评估分类器性能的更好方法是查看混淆矩阵(CM)。
实施交叉验证
与 Scikit-Learn 现成提供的功能相比,您有时需要对交叉验证过程进行更多控制。在这种情况下,你可以自己实现交叉验证。下面的代码与 Scikit-Learn 的 cross_val_score() 函数做了大致相同的事情,并会打印出相同的结果:
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
skfolds = StratifiedKFold(n_splits=3) # add shuffle=True if the dataset is # not already shuffled
for train_index, test_index in skfolds.split(X_train, y_train_5):
clone_clf = clone(sgd_clf)
X_train_folds = X_train[train_index]
y_train_folds = y_train_5[train_index]
X_test_fold = X_train[test_index]
y_test_fold = y_train_5[test_index]
clone_clf.fit(X_train_folds, y_train_folds)
y_pred = clone_clf.predict(X_test_fold)
n_correct = sum(y_pred == y_test_fold)
print(n_correct / len(y_pred)) # prints 0.95035, 0.96035, and 0.9604
StratifiedKFold 类执行分层抽样,生成的折叠数包含每个类别的代表性比例。每次迭代时,代码都会创建分类器的克隆,在训练折叠上训练该克隆,并在测试折叠上进行预测。然后计算正确预测的次数,并输出正确预测的比例。
混淆矩阵
混淆矩阵的一般概念是计算在所有 A/B 对中,A 类实例被分类为 B 类的次数。例如,要知道分类器将 8 和 0 的图像混淆的次数,可以查看混淆矩阵的第 8 行第 0 列。
要计算混淆矩阵,首先需要有一组预测结果,以便与实际目标进行比较。你可以在测试集上进行预测,但最好暂时不要使用测试集(记住,只有在项目的最后阶段,也就是分类器准备好启动时,才会使用测试集)。相反,你可以使用 cross_val_predict() 函数:
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)
与cross_val_score() 函数一样,cross_val_predict() 也会执行 k 折交叉验证,但它返回的不是评估分数,而是在每个测试折上做出的预测。这意味着你可以得到训练集中每个实例的准确预测(我说的 “准确 “是指 “样本外”:模型对训练期间从未见过的数据进行预测)。
现在可以使用 confusion_matrix() 函数获取混淆矩阵了。只需将目标类 (y_train_5) 和预测类 (y_train_pred) 传递给它即可:

混淆矩阵的每一行代表一个实际类别,每一列代表一个预测类别。矩阵的第一行是非 5 图像(负类): 其中 53 892 幅图像被正确分类为非 5 图像(称为真阴性图像),其余 687 幅图像被错误分类为 5 图像(称为假阳性图像,也称为 I 类错误)。第二行是 5 的图像(正类): 有 1 891 张图片被错误地归类为非 5(假阴性,也称为 II 类错误),而其余 3 530 张图片被正确地归类为 5(真阳性)。一个完美的分类器只有真阳性和真阴性,因此其混淆矩阵只有在主对角线上(从左上角到右下角)才有非零值:

混淆矩阵提供了大量信息,但有时您可能更喜欢更简洁的指标。一个有趣的指标是正向预测的准确度;这被称为分类器的精度(公式 见下图)。
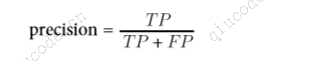
TP 是正面的数量,FP是反面的数量。
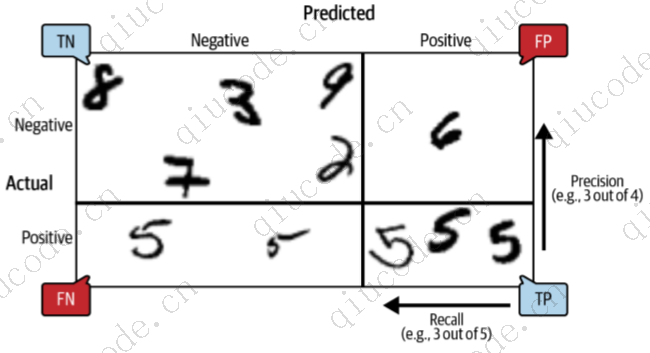
要想获得完美的精度,一个简单的方法就是创建一个分类器,除了对它最有信心的实例进行一次正向预测外,它总是进行负向预测。如果这一个预测是正确的,那么分类器的精度就是 100%(精度 = 1/1 = 100%)。显然,这样的分类器用处不大,因为它会忽略除了一个正向实例之外的所有实例。因此,精度通常与另一个名为召回率的指标一起使用,召回率也称为灵敏度或真阳性率(TPR):这是分类器正确检测到的阳性实例的比率(公式见下图)。

FN 当然是假不良的数量。
精确度和召回率
Scikit-Learn 提供多种函数来计算分类器指标,包括精度和召回率:

现在,我们的 “5-检测器 “看起来不像我们观察它的准确性时那么闪亮了。当它声称一幅图像代表 5 时,正确率只有 83.7%。而且,它只能检测到 65.1% 的 5。
通常情况下,将精确度和召回率合并为一个称为 F1 分数的指标会比较方便,尤其是在需要用一个指标来比较两个分类器时。F1 分数是精确度和召回率的调和平均数(公式 见下图)。普通均值对所有值一视同仁,而调和均值对低值的权重要大得多。因此,分类器只有在召回率和精确率都很高的情况下才能获得较高的 F1 分数。

要计算 F1 分数,只需调用f1_score()函数即可:

F1 分数有利于精确度和召回率相似的分类器。这并不总是你想要的:在某些情况下,你主要关心精度,而在另一些情况下,你真正关心的是召回率。例如,如果您训练了一个分类器来检测对儿童安全的视频,那么您可能更倾向于选择一个剔除了许多好视频(召回率低)但只保留安全视频(高精度)的分类器,而不是一个召回率高得多但却让一些非常糟糕的视频出现在您的产品中的分类器(在这种情况下,您甚至可能想要添加一个人工管道来检查分类器的视频选择)。另一方面,假设您训练了一个分类器来检测监控图像中的偷窃者:只要您的分类器的召回率达到 99%,即使它只有 30% 的精度也没有问题(当然,保安会收到一些错误警报,但几乎所有的偷窃者都会被抓住)。
不幸的是,鱼和熊掌不可兼得:提高精度会降低召回率,反之亦然。这就是所谓的精度/召回权衡。
 2024-03-09 14:59:44 +0800 +0800
2024-03-09 14:59:44 +0800 +0800 2024-03-15 17:48:03 +0800 +0800
2024-03-15 17:48:03 +0800 +0800 2024-03-09 17:45:01 +0800 +0800
2024-03-09 17:45:01 +0800 +0800 2024-01-14 15:50:17 +0800 +0800
2024-01-14 15:50:17 +0800 +0800 2023-12-11 19:50:17 +0800 +0800
2023-12-11 19:50:17 +0800 +0800