
精确率(召回率)的权衡
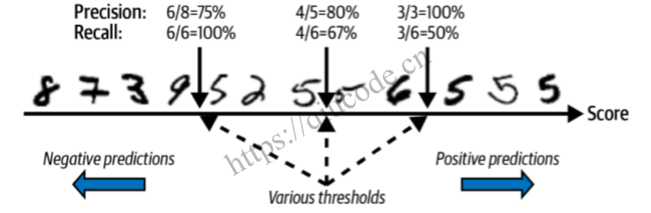
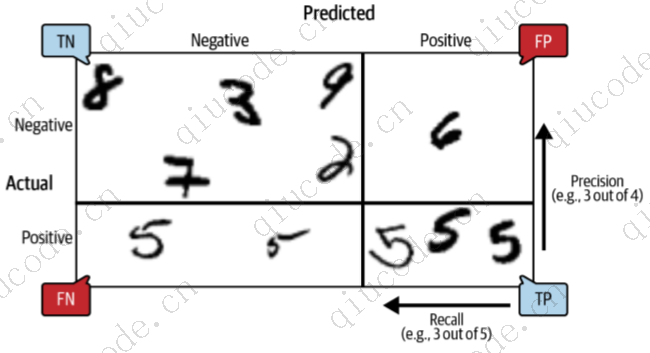
为了理解这种权衡,让我们看看 SGDClassifier 如何做出分类决策。 对于每个实例,它根据决策函数计算分数。 如果该分数大于阈值,则将该实例分配给正类; 否则它会将其分配给负类。 图 3-4 显示了从左侧最低分数到右侧最高分数的几个数字。 假设决策阈值位于中心箭头(两个 5 之间):您会在该阈值右侧发现 4 个真阳性(实际为 5),以及 1 个假阳性(实际上为 6)。 因此,使用该阈值,精度为 80%(5 分之 4)。 但在 6 个实际的 5 中,分类器仅检测到 4 个,因此召回率为 67%(6 中的 4)。 如果提高阈值(将其移动到右侧的箭头),假阳性(6)会变成真阴性,从而提高精度(在本例中高达 100%),但一个真阳性会变成假阴性 ,将召回率降低至 50%。 相反,降低阈值会增加召回率并降低精确度。
Scikit-Learn 不允许您直接设置阈值,但它允许您访问它用于进行预测的决策分数。 您可以调用其decision_function()方法,而不是调用分类器的predict()方法,该方法返回每个实例的分数,然后使用您想要根据这些分数进行预测的任何阈值:

SGDClassifier 使用等于 0 的阈值,因此前面的代码返回与 Predict() 方法相同的结果(即 True)。 让我们提高门槛:

这证实了提高阈值会降低召回率。 该图像实际上代表的是 5,当阈值为 0 时分类器会检测到它,但当阈值增加到 3,000 时分类器会错过它。
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function")
有了这些分数,使用 precision_recall_curve() 函数计算所有可能阈值的精度和召回率(该函数添加最后精度 0 和最后召回率 1,对应于无限阈值):
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
最后,使用 Matplotlib 将精度和召回率绘制为阈值的函数(见下图)。 让我们展示一下我们选择的阈值 3,000:
plt.plot(thresholds, precisions[:-1], "b--", label="Precision", linewidth=2) plt.plot(thresholds, recalls[:-1], "g-", label="Recall", linewidth=2) plt.vlines(threshold, 0, 1.0, "k", "dotted", label="threshold") [...] # beautify the figure: add grid, legend, axis, labels, and circles plt.show()
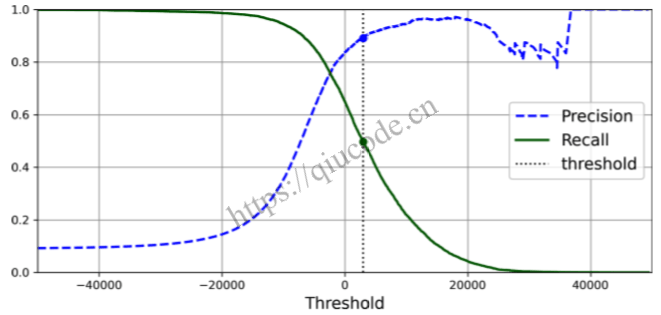
在此阈值下,准确率接近 90%,召回率约为 50%。 选择良好的精度/召回率权衡的另一种方法是直接针对召回率绘制精度图,如图 3-6 所示(显示了相同的阈值):
plt.plot(recalls, precisions, linewidth=2, label="Precision/Recall curve") [...] # beautify the figure: add labels, grid, legend, arrow, and text plt.show()
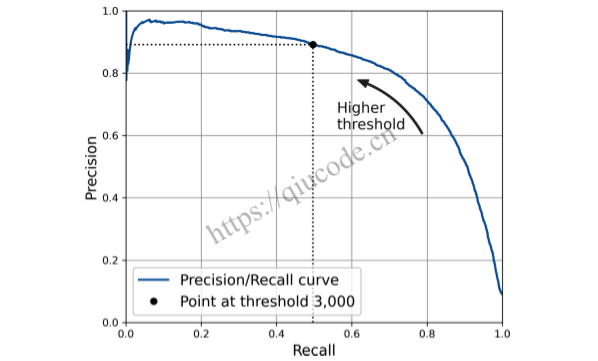
您可以看到,当召回率达到 80% 左右时,准确率确实开始急剧下降。 您可能希望在该下降之前选择精确率/召回率权衡,例如,召回率约为 60%。 但当然,选择取决于您的项目。
假设您决定以 90% 的精度为目标。 您可以使用第一个图来找到需要使用的阈值,但这不是很精确。 或者,您可以搜索可提供至少 90% 精度的最低阈值。 为此,您可以使用 NumPy 数组的 argmax() 方法。 这将返回最大值的第一个索引,在本例中意味着第一个 True 值:

要进行预测(目前在训练集上),您可以运行以下代码,而不是调用分类器的 Predict() 方法:
y_train_pred_90 = (y_scores >= threshold_for_90_precision)
让我们检查这些预测的精确度和召回率:

太棒了,你有一个 90% 精度的分类器! 正如您所看到的,创建具有几乎任何您想要的精度的分类器相当容易:只需设置足够高的阈值,就可以了。 但是等等,不要这么快——如果召回率太低,高精度分类器就不是很有用! 对于许多应用程序来说,48% 的召回率根本就不够好。
 2024-03-15 18:26:43 +0800 +0800
2024-03-15 18:26:43 +0800 +0800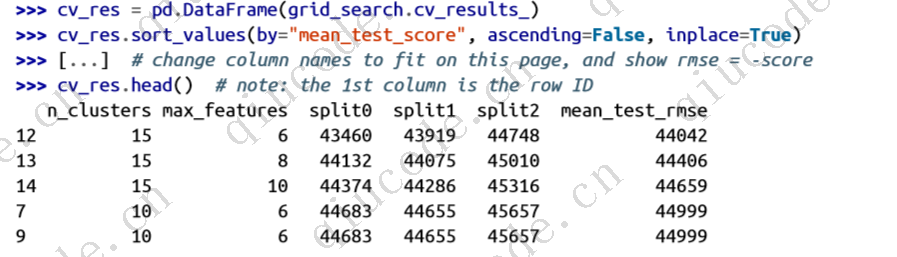 2024-03-09 14:59:44 +0800 +0800
2024-03-09 14:59:44 +0800 +0800 2024-03-15 17:48:03 +0800 +0800
2024-03-15 17:48:03 +0800 +0800 2024-03-09 17:45:01 +0800 +0800
2024-03-09 17:45:01 +0800 +0800 2024-01-14 15:50:17 +0800 +0800
2024-01-14 15:50:17 +0800 +0800