
多类别分类器
二元分类器可以区分两个类别,而多类别分类器(也称为多叉分类器)可以区分两个以上的类别。
一些 Scikit-Learn 分类器(如 LogisticRegression、RandomForestClassifier 和 GaussianNB)能够原生处理多个类别。其他分类器则是严格的二进制分类器(如 SGDClassifier 和 SVC)。不过,您可以使用多种策略来使用多个二进制分类器执行多类分类。
要创建一个能将数字图像分为 10 类(从 0 到 9)的系统,一种方法是训练 10 个二进制分类器,每个数字一个(0-检测器、1-检测器、2-检测器,以此类推)。然后,当您想对一幅图像进行分类时,您可以从每个分类器中得到该图像的判定分数,然后选择分类器输出分数最高的类别。这就是所谓的 “以一敌百”(OvR)策略,有时也称为 “以一敌众”(OvA)策略。
另一种策略是为每一对数字训练一个二元分类器:一个用于区分 0 和 1,另一个用于区分 0 和 2,还有一个用于区分 1 和 2,以此类推。这就是所谓的一对一(OvO)策略。如果有 N 个类别,则需要训练 N × (N - 1) / 2 个分类器。对于 MNIST 问题,这意味着要训练 45 个二进制分类器!当你想对一幅图像进行分类时,你必须让图像通过所有 45 个分类器,看看哪个分类器赢得了最多的对决。OvO 的主要优势在于,每个分类器只需在训练集中包含其必须区分的两个类别的部分进行训练。
有些算法(如支持向量机分类器)随训练集的大小而缩放,效果不佳。对于这些算法,OvO 是首选,因为在小训练集上训练多个分类器比在大训练集上训练少数分类器更快。不过,对于大多数二元分类算法来说,OvR 是首选。
Scikit-Learn 会检测你是否尝试在多分类任务中使用二元分类算法,并根据算法自动运行 OvR 或 OvO。让我们使用 sklearn.svm.SVC 类支持向量机分类器来尝试一下。我们只对前 2,000 张图像进行训练,否则会耗费很长时间:
from sklearn.svm import SVC
svm_clf = SVC(random_state=42) svm_clf.fit(X_train[:2000], y_train[:2000]) # y_train, not y_train_5
我们使用从 0 到 9 的原始目标类别(y_train),而不是 5 对其余目标类别(y_train_5)来训练 SVC。由于有 10 个类别(即多于 2 个),Scikit-Learn 使用 OvO 策略训练了 45 个二元分类器。现在,让我们对一幅图像进行预测:

赢得决斗的次数加上或减去一个小调整(最大 ±0.33)以打破平局:没错!这段代码实际上进行了 45 次预测,每对班级一次,并选择了赢得决斗最多的班级。如果你调用 decision_function() 方法,就会看到它为每个实例返回 10 个分数:每个班级一个。根据分类器的得分,每个类得到的分数等于

得分最高的是 9.3 分,确实是 5 级:

训练分类器时,分类器会在 classes_ attribute中存储目标类列表,并按值排序。在 MNIST 的情况下,classes_ array 中每个类的索引很容易与类本身相匹配(例如,索引为 5 的类恰好是 “5 “类),但在一般情况下,你就没那么幸运了;你需要像这样查找类标签:

如果您想强制 Scikit-Learn 使用一对一或一对多,可以使用 OneVsOneClassifier 或 OneVsRestClassifier 类。只需创建一个实例,并向其构造函数传递一个分类器(甚至不必是二进制分类器)。例如,这段代码使用 OvR 策略创建了一个基于 SVC 的多分类器:
from sklearn.multiclass import OneVsRestClassifier
ovr_clf = OneVsRestClassifier(SVC(random_state=42)) ovr_clf.fit(X_train[:2000], y_train[:2000])
让我们进行一次预测,并检查已训练分类器的数量:

在多类数据集上训练 SGDClassifier 并用它进行预测也同样简单:

预测错误确实会发生!这次,Scikit-Learn 在引擎盖下使用了 OvR 策略:因为有 10 个类别,所以它训练了 10 个二元分类器。现在,decision_function() 方法会为每个类别返回一个值。让我们看看 SGD 分类器为每个类别分配的分数:

可以看出,分类器对自己的预测不是很有信心:几乎所有的分数都非常负面,而第 3 类的分数为 +1,824 分,第 5 类也不差,为 -1,386 分。当然,你需要在不止一幅图像上对这个分类器进行评估。由于每个类别中的图片数量大致相同,因此准确度指标也没有问题。像往常一样,你可以使用 cross_val_score() 函数来评估模型:

它在所有测试折叠中的准确率超过 85.8%。如果使用随机分类器,准确率会达到 10%,所以这个成绩还不算太差,但还可以做得更好。只需缩放输入(如第 2 章所述),准确率就能提高到 89.1%以上:

 2024-03-29 11:43:43 +0800 +0800
2024-03-29 11:43:43 +0800 +0800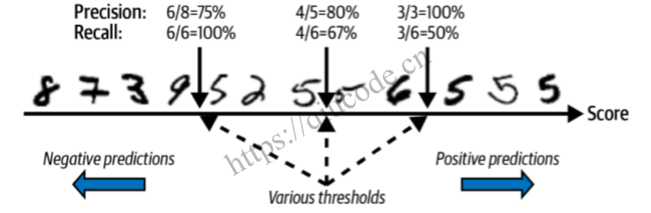 2024-03-21 19:43:43 +0800 +0800
2024-03-21 19:43:43 +0800 +0800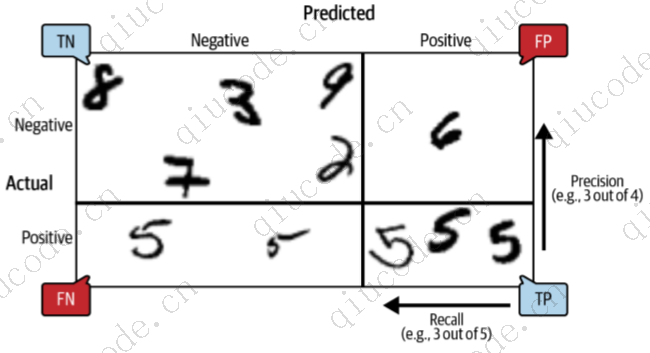 2024-03-15 18:26:43 +0800 +0800
2024-03-15 18:26:43 +0800 +0800 2024-03-15 17:48:03 +0800 +0800
2024-03-15 17:48:03 +0800 +0800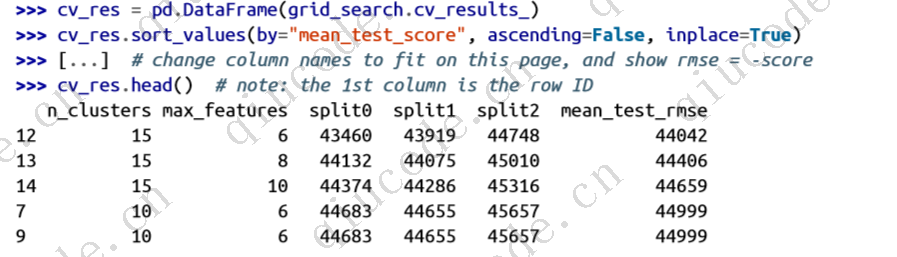 2024-03-09 14:59:44 +0800 +0800
2024-03-09 14:59:44 +0800 +0800