
在人工智能领域,生成一致且连贯的故事绘本一直是一个具有挑战性的任务。Story-Adapter作为一个开源项目,旨在解决这一问题,为用户提供无需训练即可生成长篇故事视觉化的工具。本文将指导您如何在Windows系统上本地部署并运行Story-Adapter。
项目简介
Story-Adapter项目提出了一种无需训练的迭代框架,用于长篇故事的可视化生成,特别关注在生成过程中保持角色的一致性。通过利用现有的文本到图像生成模型,Story-Adapter能够根据输入的故事文本,生成一系列连贯且一致的图像帧,适用于绘本创作、动画制作等领域。
项目地址:https://github.com/UCSC-VLAA/story-adapter
环境准备
从项目的README.md中有关于本地安装的必要条件:
- Python 3.10.14
- PyTorch 2.2.2
- CUDA 12.1
- cuDNN 8.9.02
虽然官方是通过anaconda来创建python项目的虚拟环境,这也官方推荐的,可以说是所有开源AI 项目的友好方式。
然而我却不使用anaconda,而使用python自带创建虚拟环境的方式。
python -m venv story-adapter-env #创建 story-adapter-env 虚拟环境
cd story-adapter-env\Script
activate #激活虚拟环境
1. 安装Python
前往Python官方网站下载适用于Windows的最新版本Python安装包。在安装过程中,务必勾选“Add Python to PATH”选项,以便在命令提示符中直接使用Python命令。
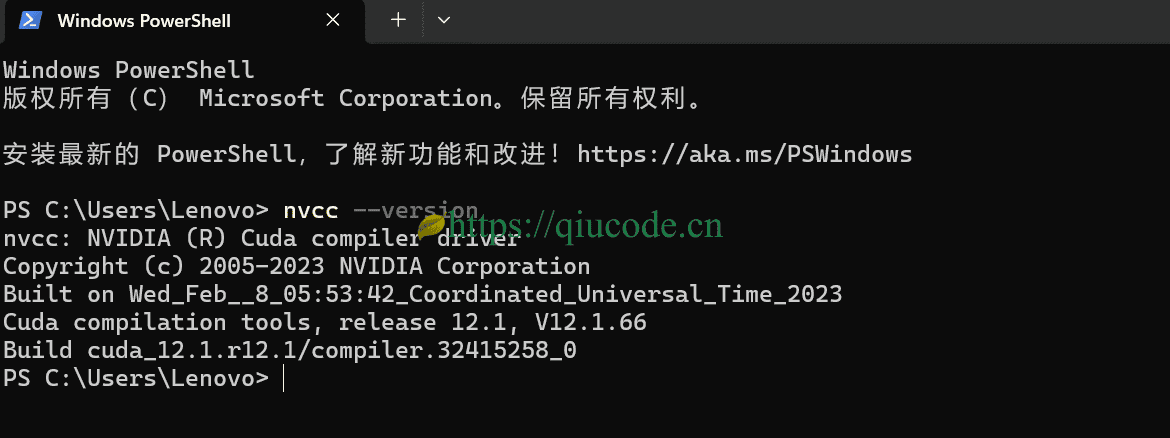
我安装的是python 3.10.9。
2.安装Git
访问Git for Windows下载并安装Git。安装完成后,您可以在命令提示符中使用git命令。
3.安装CUDA
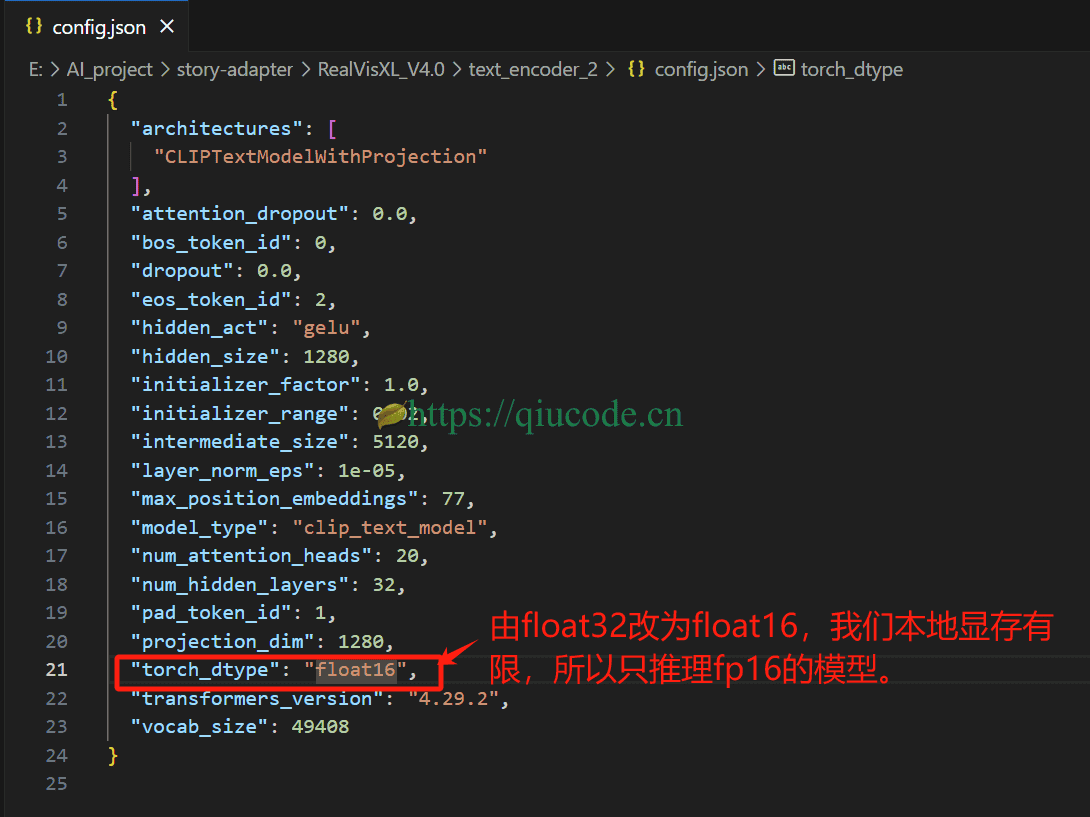
如果您的计算机配备了NVIDIA GPU,并希望利用GPU加速,请前往NVIDIA官方网站下载并安装适用于您GPU型号的CUDA Toolkit。
克隆项目代码
执行以下命令以克隆Story-Adapter项目代码:
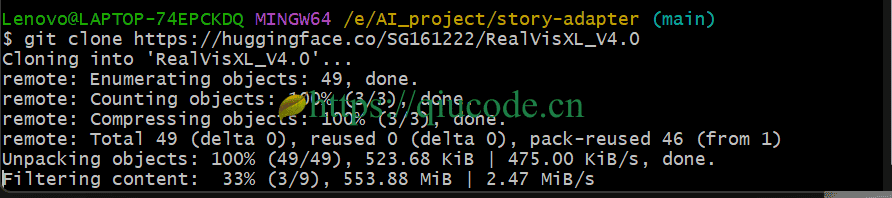
git clone https://github.com/UCSC-VLAA/story-adapter.git
cd story-adapter
此操作将在当前目录下创建一个名为story-adapter的文件夹,包含项目的所有代码。
安装依赖项
pip install-r requirements.txt-i https://pypi.tuna.tsinghua.edu.cn/simpe/
下载模型
在下载模型,请提前准备好网络(你应该懂的什么是网络吧)。
按照官方的指引来下载对应的模型,及存放的位置。
Download the checkpoint
downloading RealVisXL_V4.0 put it into “./RealVisXL_V4.0”
downloading clip_image_encoder put it into “./IP-Adapter/sdxl_models/image_encoder”
downloading ip-adapter_sdxl put it into “./IP-Adapter/sdxl_models/ip-adapter_sdxl.bin”
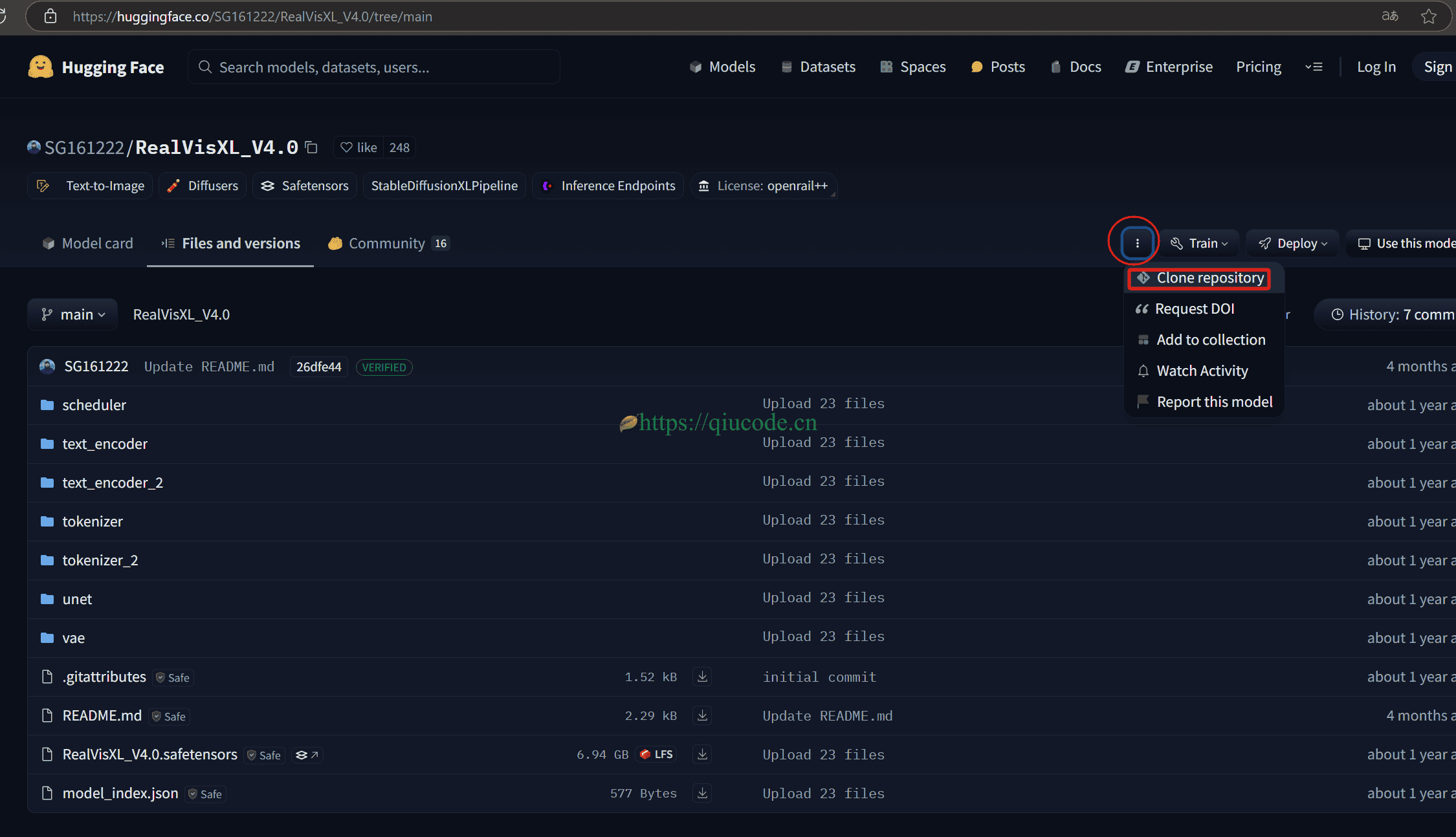
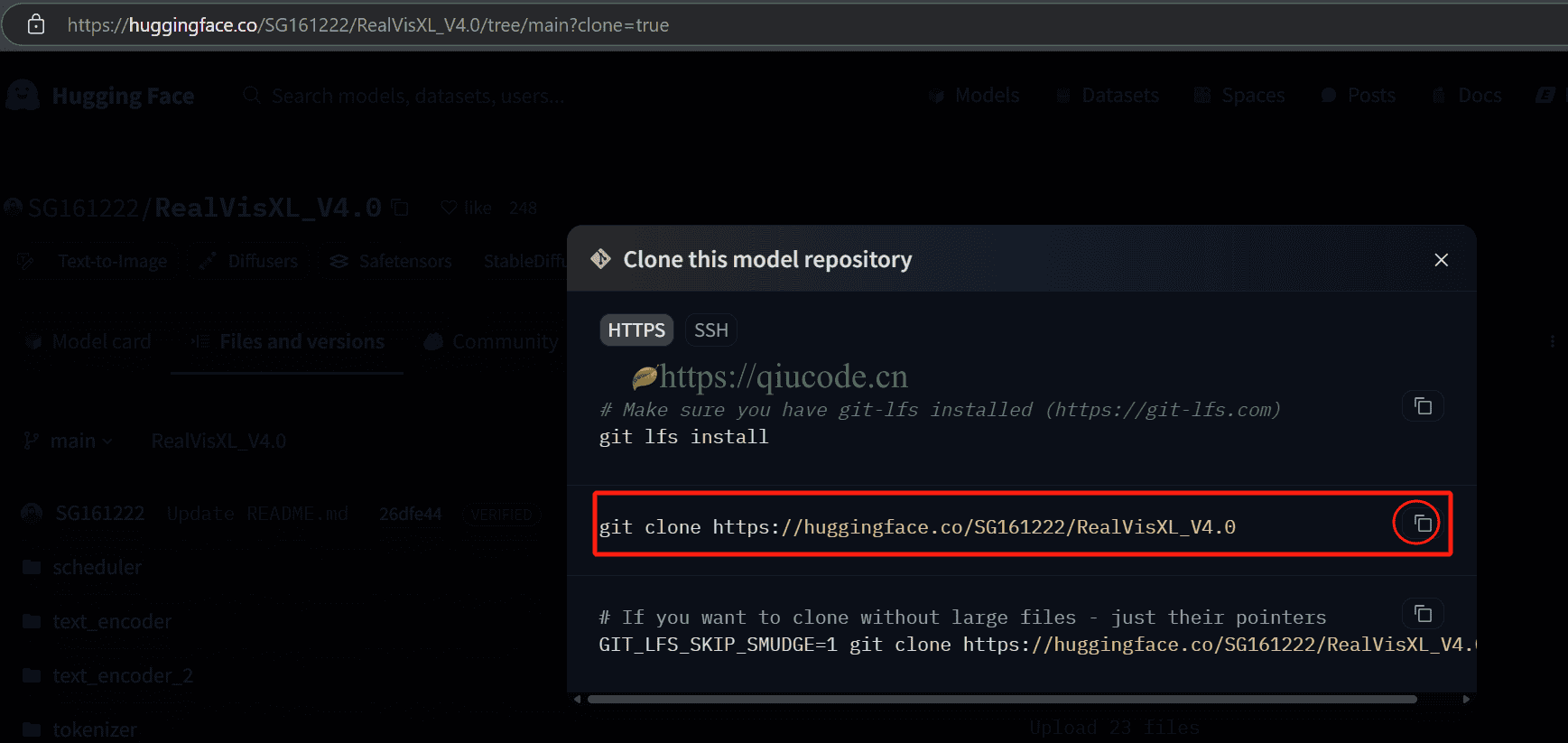
其他也是同样的操作哦,前提你得先设置好git的网络哦,否则会下载不了哦。
等你模型下载好了之后,项目目录结构最终如下图所示。
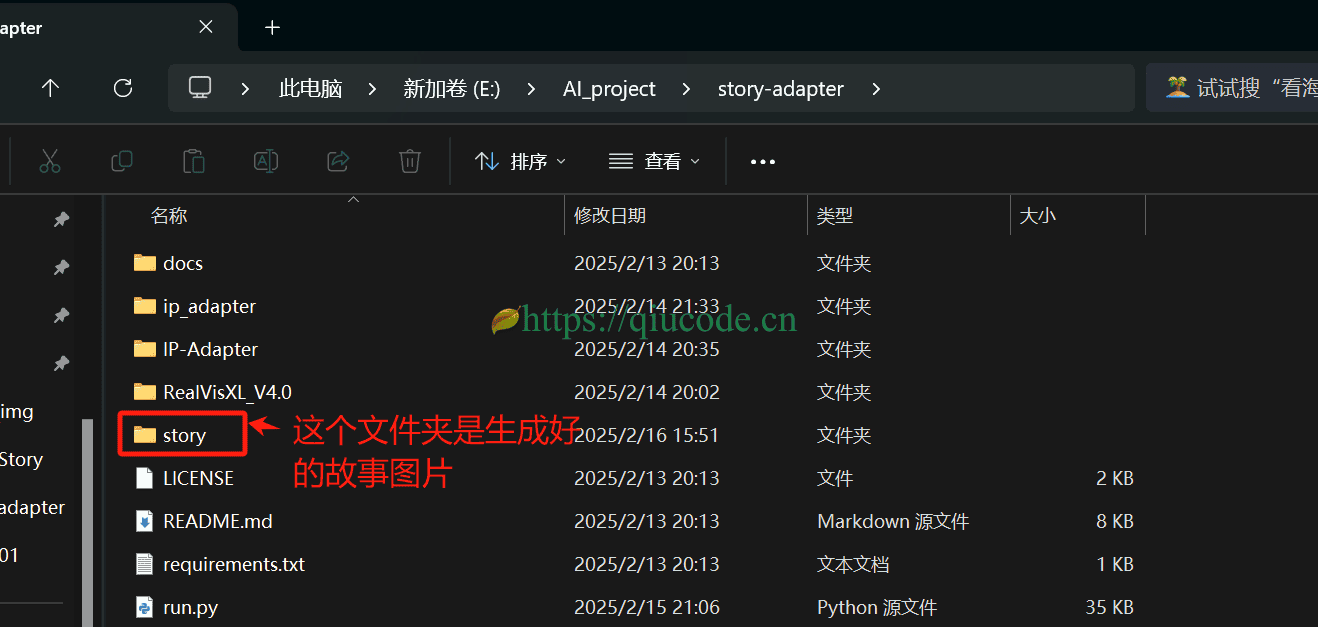
运行项目
由于run.py文件已经配置好参数,所以我们就是用默认的,官方提供了6个故事prompt,我选择了第三个。
python run.py #也可以通过命令行参数进行传递, --story story4
会在当前项目根路径下自动创建story文件夹。
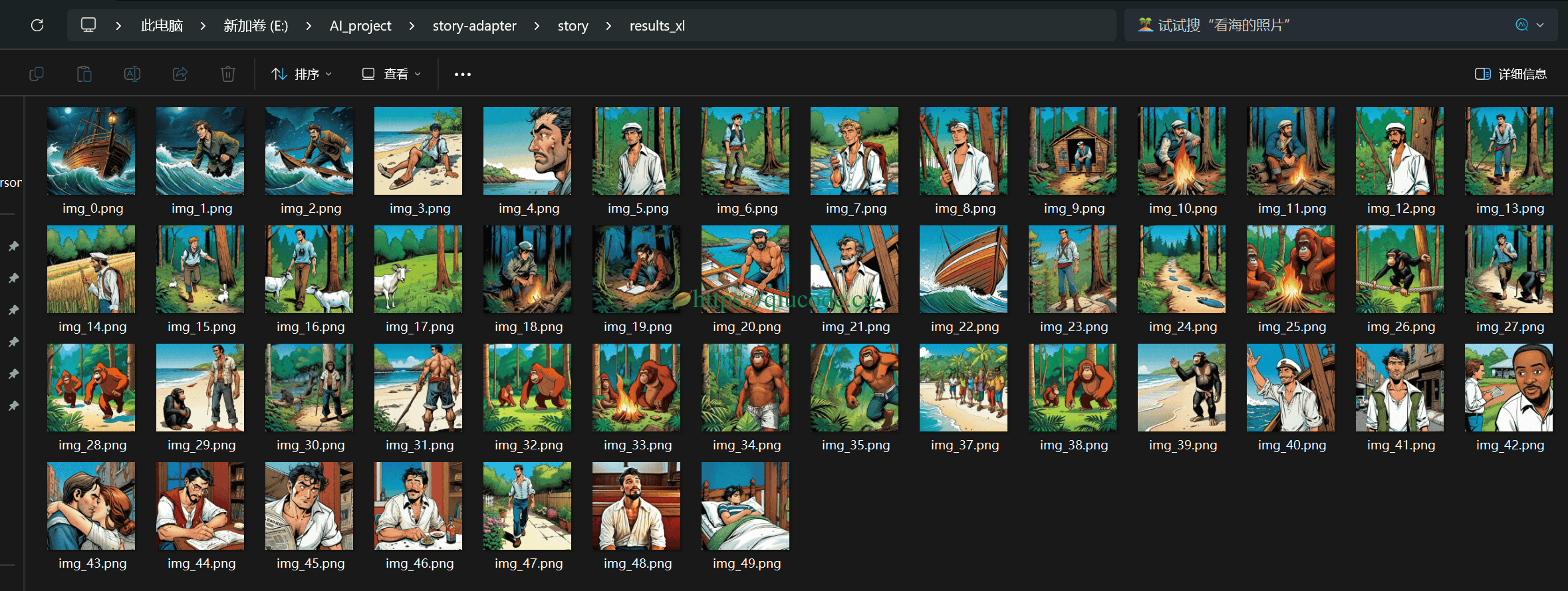
从这些图片可以看出,这是一个男人出海,不幸遇上风浪,被飘到原始森林,当然船只也坏了,而后他通过自己打造一只船,再次踏出海,索性的是,这回总算是回到了,日思夜想的故乡,与妻子相聚。在接下来的日子,他便将这段经历通过文字,记录了下来。或许是常年与大海打交道,身体终究还是抗不住那通风的折磨,住进了医院。
 2025-02-03 20:26:43 +0800 +0800
2025-02-03 20:26:43 +0800 +0800