
Qwen2.5-VL是阿里云推出的开源多模态大模型,支持图像理解、视频分析、文档结构化处理等功能。
较上一个版本Qwen2-VL有质的飞越,Qwen2.5-VL通过动态分辨率适配和窗口注意力机制,显著降低显存占用并提升推理速度,72B模型在单卡A100上推理速度提升30% 。
身在AI这股浪潮中,只要本地电脑硬件条件允许的话,我都会尝试着去部署优秀的开源大模型。
说到开源大模型,相对而言的就是闭源大模型,我们在脑海中很自然地浮现出国外的OPENAI,以及国内的百度,也就是李彦宏所说的“开源大模型,对个人是没有好处”(好像是这么说的吧)。
由于DeepSeek的冲击,据说百度将要开源大模型了,这李彦宏不是妥妥的打了自己的脸了吗?很想隔空问李彦宏一句话,难道你的脸不痛吗?
克隆Qwen2.5-VL代码及安装必须依赖
git clone https://github.com/QwenLM/Qwen2.5-VL.git
使用Python3自带的venv库,创建虚拟环境。当然你也可以使用anaconda或miniconda工具进行创建python虚拟环境。
python -m venv qwen-vl-env
cd qwen-vl-env\Script
activate
之后回到Qwen2.5-VL代码的根路径下,进行必须依赖安装。
cd Qwen2.5-VL
pip install -r requirements_web_demo.txt
当然,为了可以使用GPU来推理,还需安装与你的CUDA版本匹配的pytorch
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu121
其实pytorch依赖是包含在requirements_web_demo.txt文件中,那是CPU版本的。
而对于windows用户来说,以下这步也是多余的。
pip install qwen-vl-utils
下载模型
Qwen2.5-VL开源三个不同参数的大模型,分别是3B、7B、72B。
Huggingface模型地址:https://huggingface.co/collections/Qwen/qwen25-vl-6795ffac22b334a837c0f9a5
Modelscope魔塔社区:https://modelscope.cn/collections/Qwen25-VL-58fbb5d31f1d47
运行官方的gradio demo示例
可不知是什么原因,我运行python web_demo_mm.py却出现错误,报的错误都是与gradio相关的错误信息,致使我一度怀疑,是不是需要更新gradio的依赖呢。
然而,事与愿违,报错还是一如既往报错,它可不会因为你更新了gradio依赖,就停止报错了。
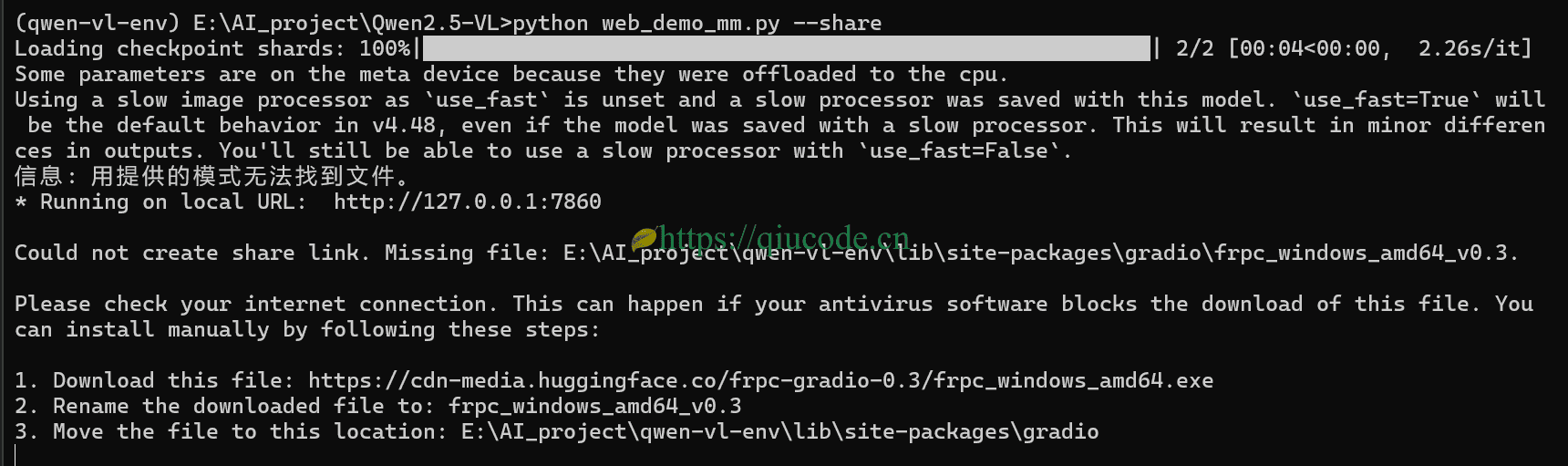
所以呢,我就运行官方不带gradio的示例,结果却成功,这让我异常兴奋。
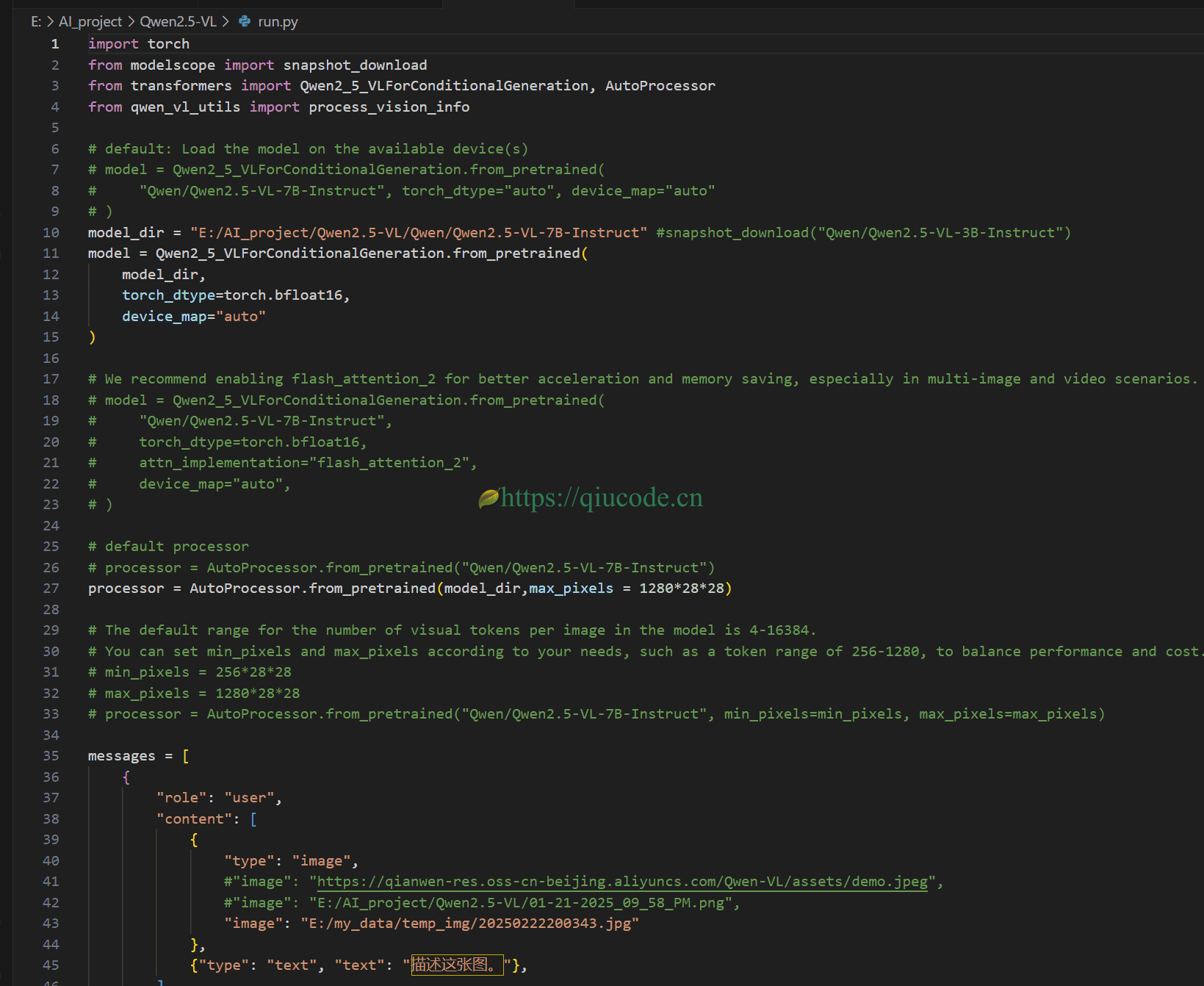
import torch
from modelscope import snapshot_download
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
# model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-VL-7B-Instruct", torch_dtype="auto", device_map="auto"
# )
model_dir = "E:/AI_project/Qwen2.5-VL/Qwen/Qwen2.5-VL-7B-Instruct" #snapshot_download("Qwen/Qwen2.5-VL-3B-Instruct")
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_dir,
torch_dtype=torch.bfloat16,
device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-VL-7B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# default processor
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct")
processor = AutoProcessor.from_pretrained(model_dir,max_pixels = 1280*28*28)
# The default range for the number of visual tokens per image in the model is 4-16384.
# You can set min_pixels and max_pixels according to your needs, such as a token range of 256-1280, to balance performance and cost.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
#"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
"image": "E:/AI_project/Qwen2.5-VL/01-21-2025_09_58_PM.png",
#"image": "E:/my_data/temp_img/20250222200343.jpg"
},
{"type": "text", "text": "描述这张图。"},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to(model.device)
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
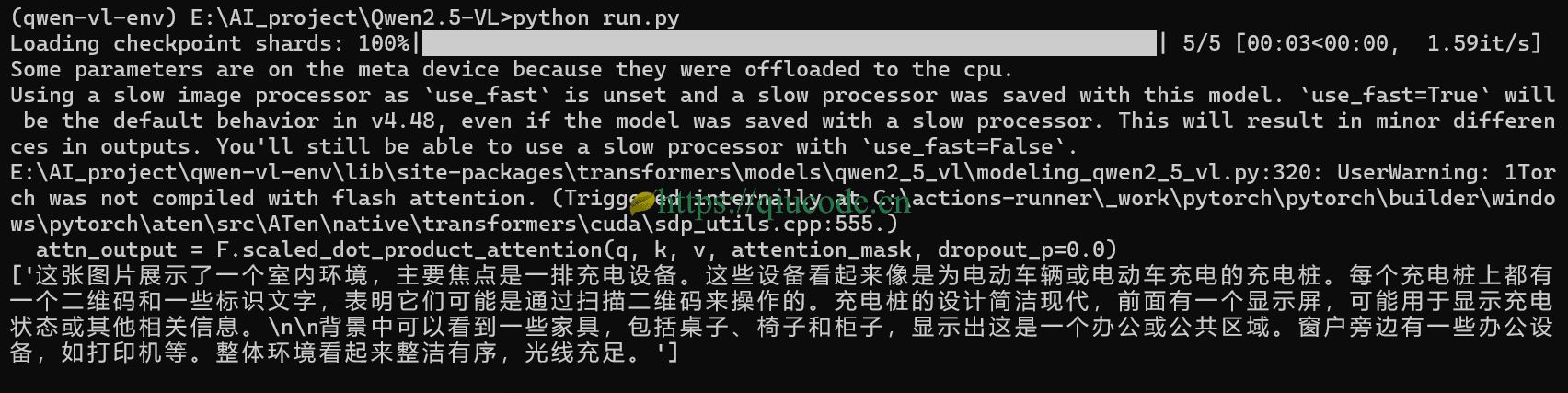
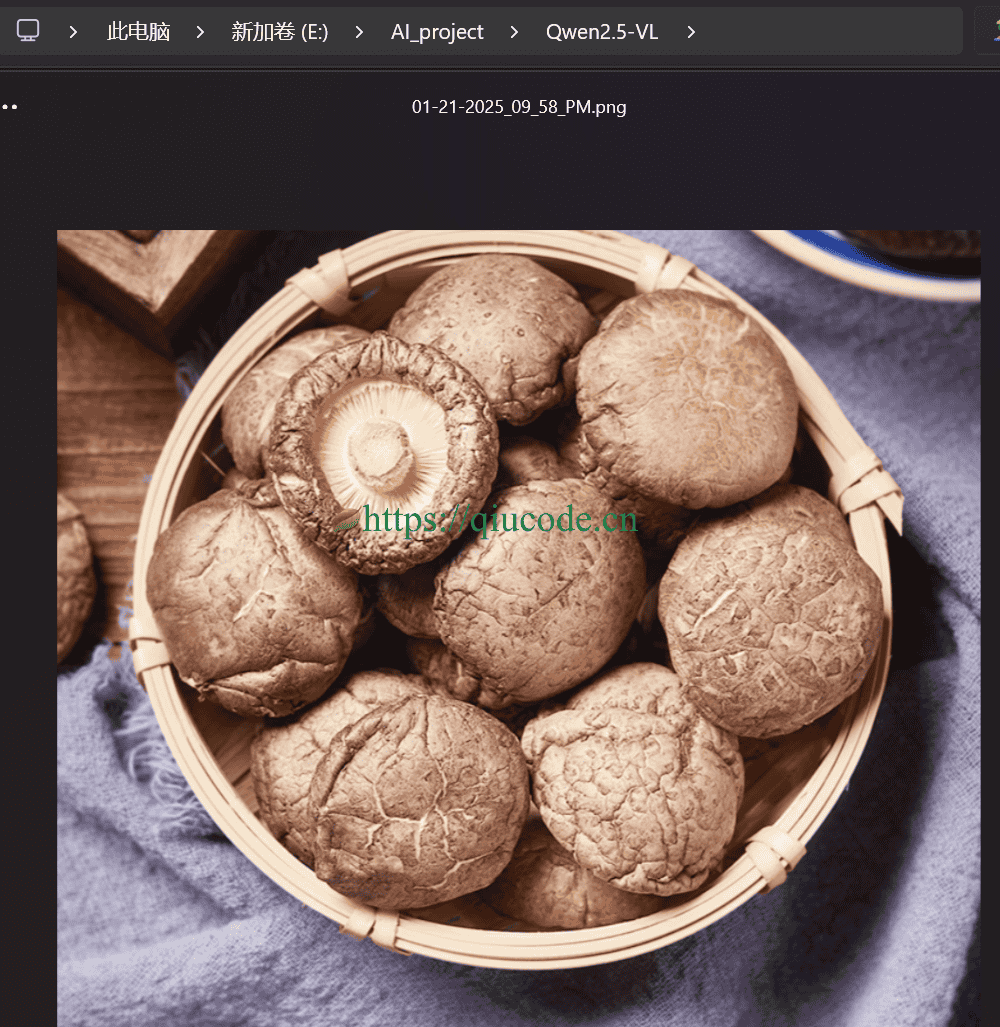
现在我让描述下这张图片。(原图是不加水印的)

可它把充电宝识别成了充电桩,至于其它的,还是不错。
我们再让它识别另一张图片。(原图是不加水印的)
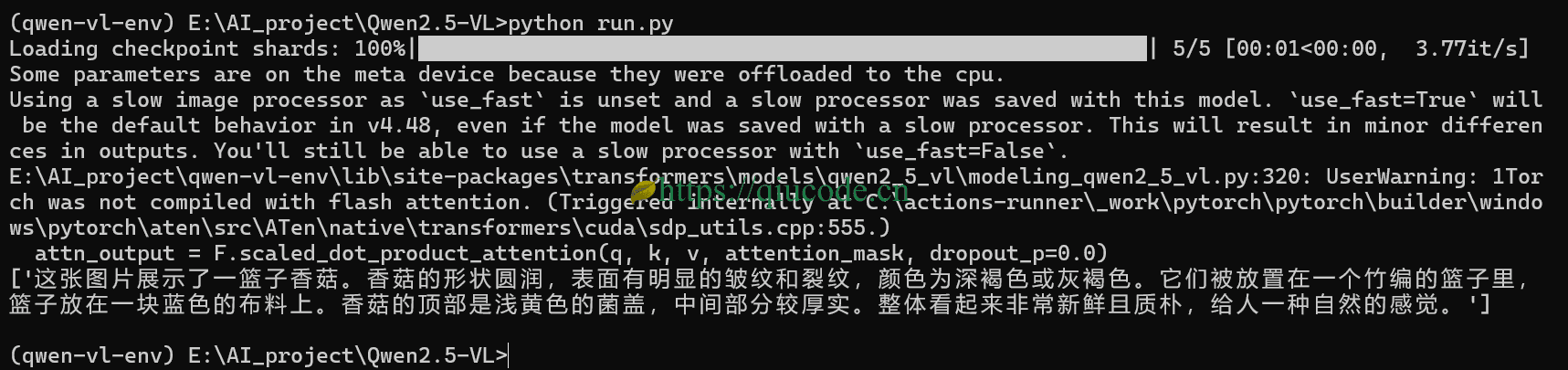
然而这次却出乎我的意料,识别的很准确。
至于那个官方的gradio示例出现报错问题,等有空了再去弄吧。
 2025-02-16 16:26:43 +0800 +0800
2025-02-16 16:26:43 +0800 +0800 2025-02-03 20:26:43 +0800 +0800
2025-02-03 20:26:43 +0800 +0800