
曾几何时,我们想要对图片进行PS,那可是难为了我们这般PS门外汉。
然而,MagicQuill这款开源的图像元素修改,可算是解救了我们这些PS小白啊。
那么,现在我们就可以在自己电脑部署这款开源的图像编辑神器。
但想要在本地电脑部署这款开源的AI图像编辑神器,你的电脑显存要大于12G(虽然官方说是8G),预留硬盘空间在40G(模型就有30G),CUDA版本得在12.1或更高。
创建 python 虚拟环境
创建python虚拟环境是为了每个项目,库依赖各自隔离,不受影响。
我电脑python使用的版本是3.10.9,使用python自带的venv来创建虚拟环境,当然咯,你也可以使用anaconda或miniconda来创建虚拟环境。
随后,我们激活刚刚创建好的虚拟环境。
python -m venv MagicQuill-env
cd MagicQuill-env/Scripts
activate
clone MagicQuil 项目代码
git clone --recursive https://github.com/magic-quill/MagicQuill.git
cd MagicQuill
安装支持GPU的 torch 依赖
至于版本,那是官方的READMD.md中提到的,使用了阿里云镜像,能加速torch在国内的下载。
pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 -f https://mirrors.aliyun.com/pytorch-wheels/cu121

安装 MagicQuill 支持 gradio 依赖
这个位于项目根路径下,我们直接pip install这个wheel文件即可。
pip install gradio_magicquill-0.0.1-py3-none-any.whl
安装 llava 依赖
这个llava也是包含在项目中的。
首先,我们需要将项目根路径下的pyproject.toml复制到MagicQuill\LLaVA\。
随后,安装llava依赖。
copy /Y pyproject.toml MagicQuill\LLaVA\
pip install -e MagicQuill\LLaVA\
7、安装项目必须依赖。
安装项目必须依赖
pip install -r requirements.txt
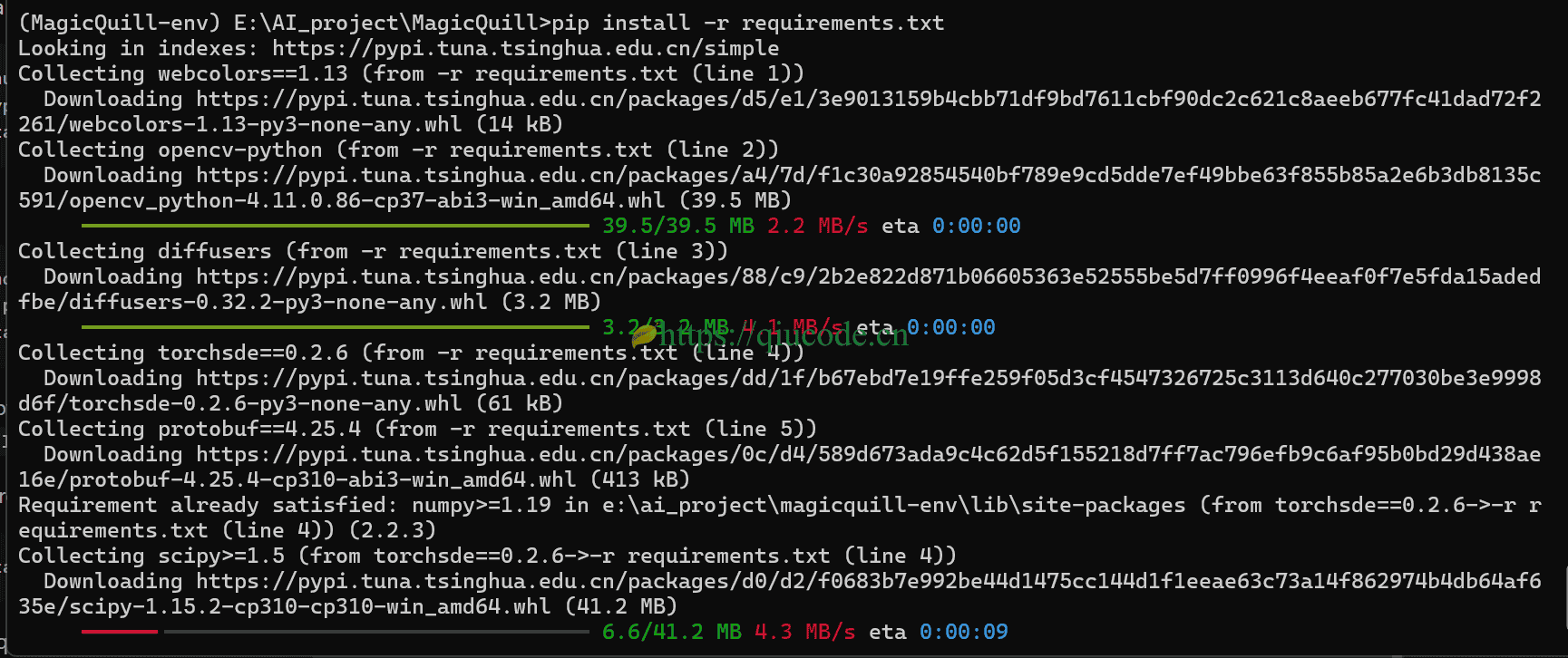
下载模型
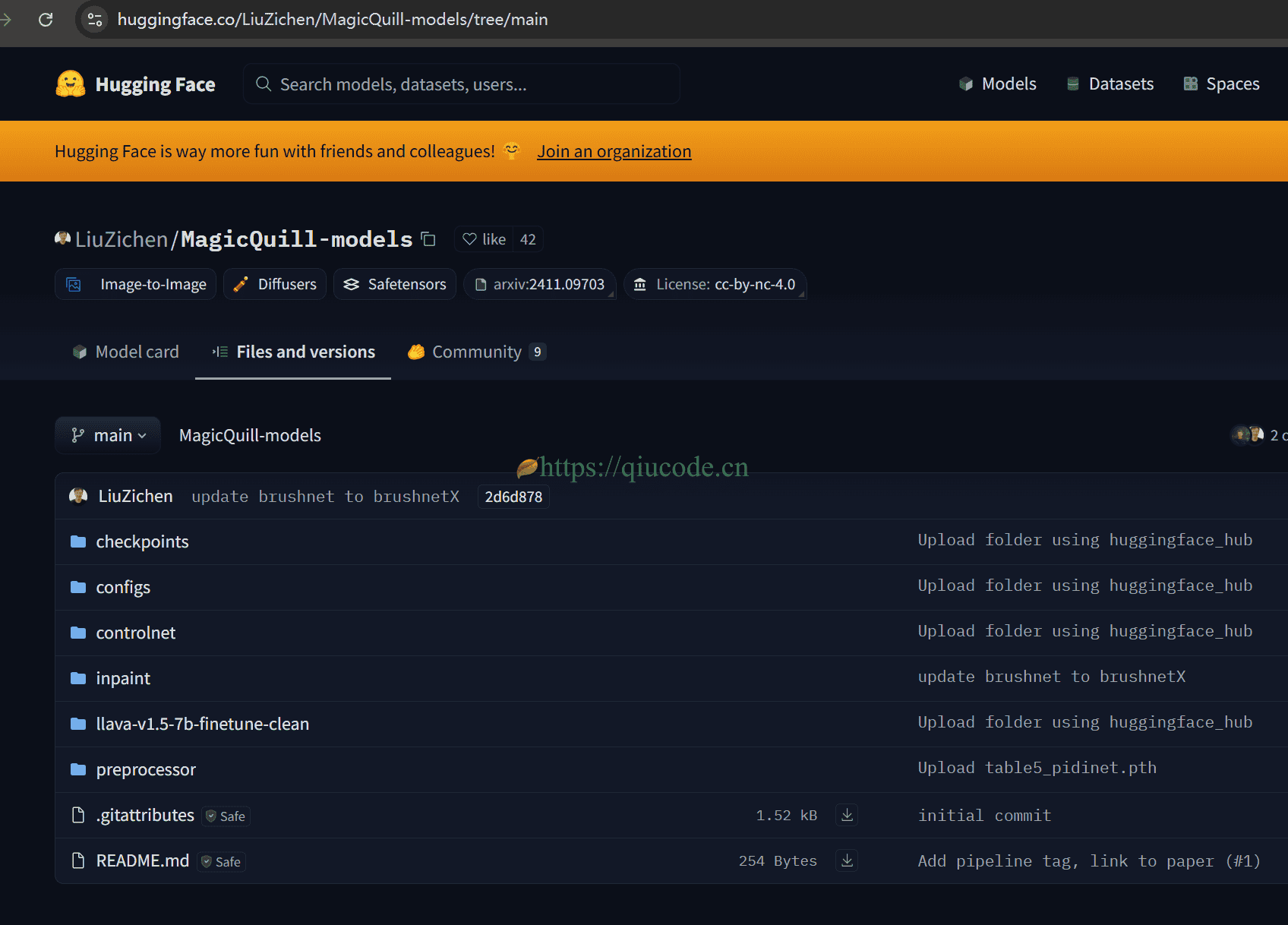
模型大小总共29.9GB,所以电脑硬盘得预留出这么大的空间出来。
国内可直接:https://hkustconnect-my.sharepoint.com/:u:/g/personal/zliucz_connect_ust_hk/EWlGF0WfawJIrJ1Hn85_-3gB0MtwImAnYeWXuleVQcukMg?e=Gcjugg&download=1
Hugginface:https://huggingface.co/LiuZichen/MagicQuill-models/tree/main
下载后,直接解压到当前路径即可。
运行 gradio_run.py
但出现如下图所示的错误,那是这个项目需要去hugginfface下载必要的文件,这时,就得在terminal开启网络咯(你应该懂得什么是网络吧!)
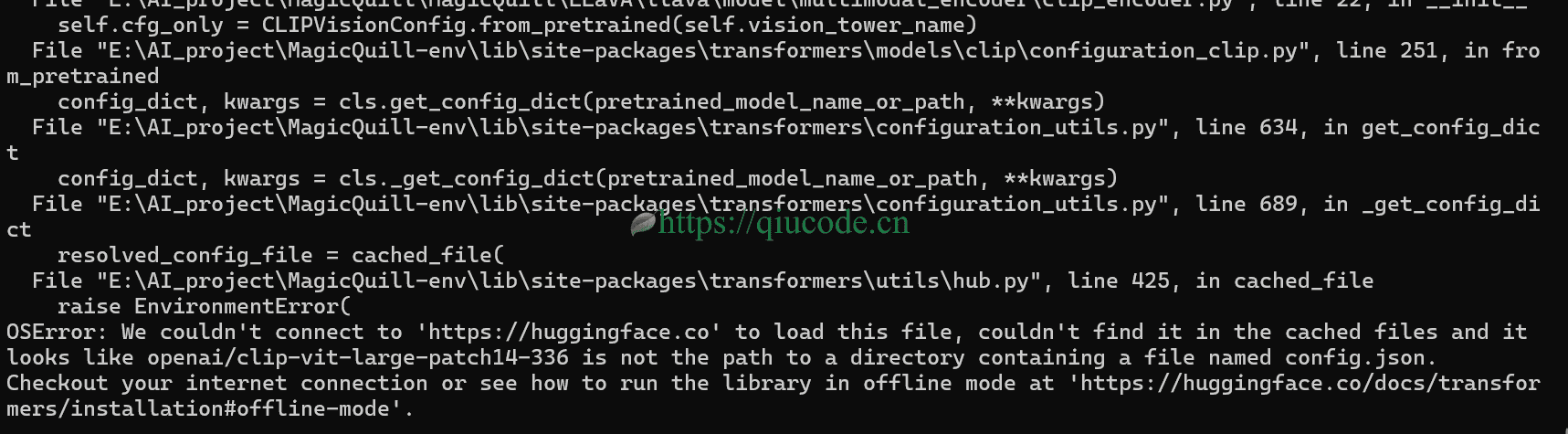
我们设置好了网络后,再次执行python gradio.py,便开始从Huggingface.co下载项目必要的文件及模型。
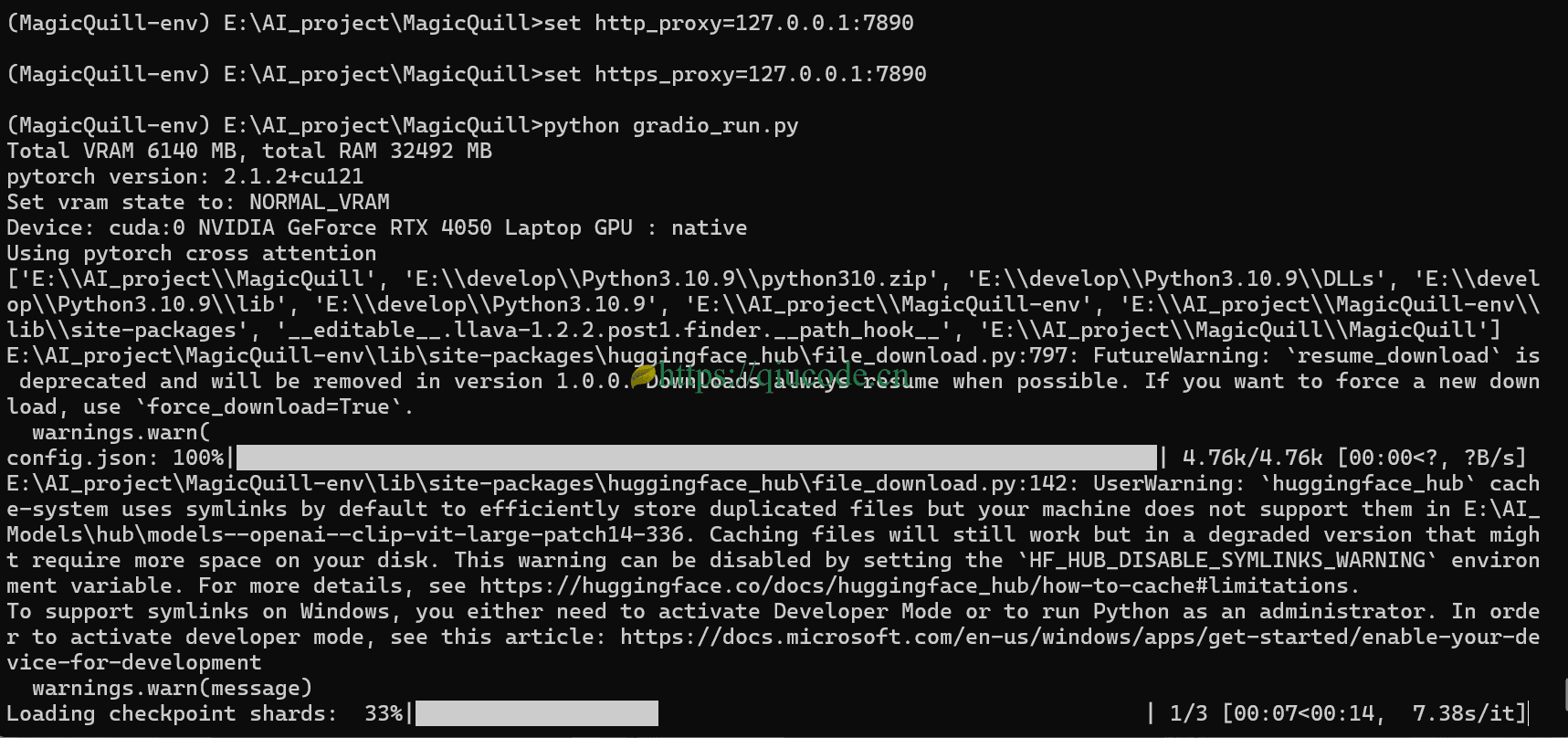
等所有必要文件下载成功后,出现下图这般信息,说明我们在本地电脑部署成功了。
那么,接下来,就是我们表演的时候了。
我们借助Stable Diffusion3.5随意画出一张图片,好在MagicQuill上尽情的把玩。
随后,我们将刚刚SD3.5为我们生成图片,上传到MagicQuill中,对这张图进行编辑,以感受它所带来的震撼感。
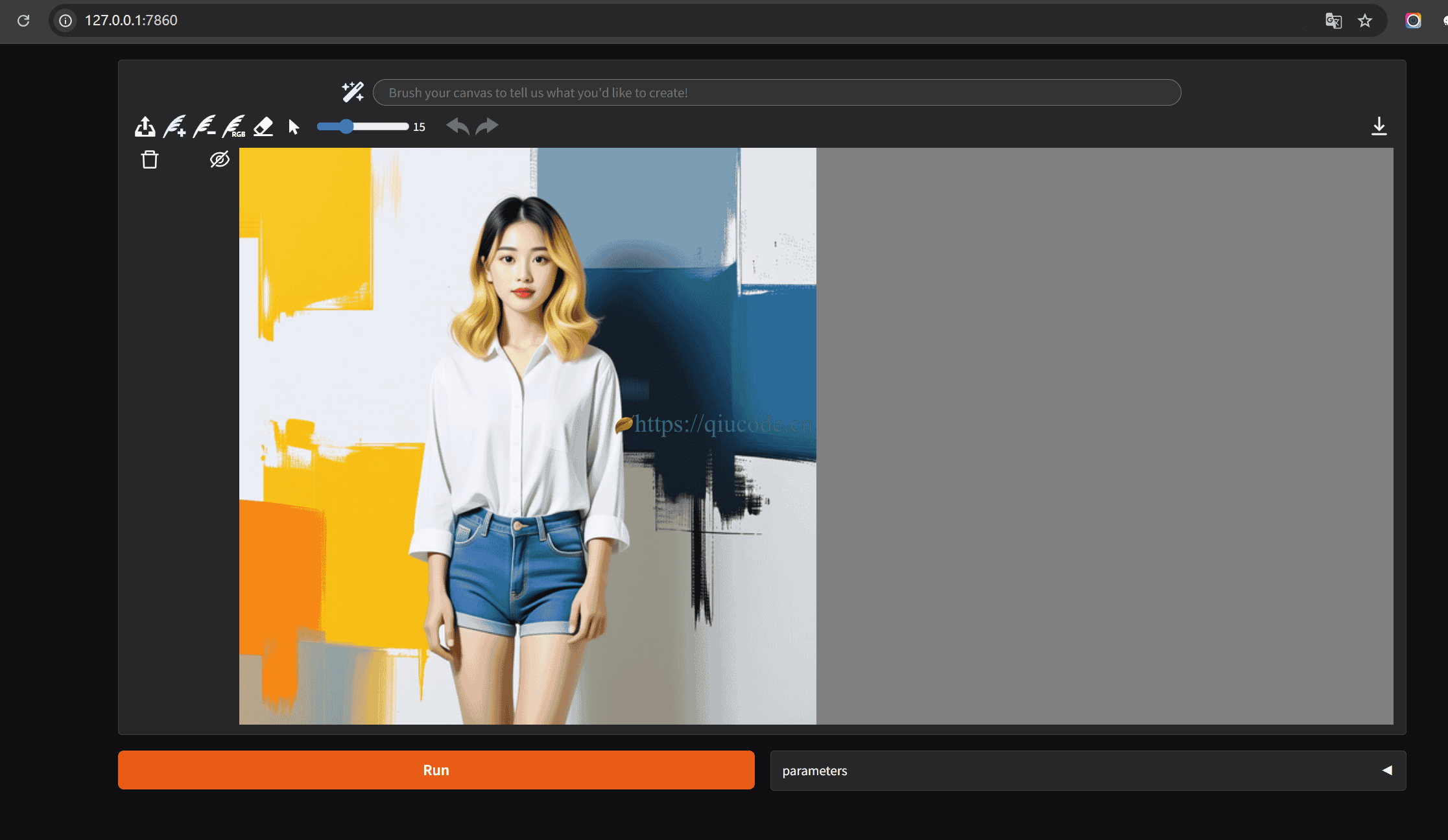
我们先来个简单的,那边给图片中的人物戴上太阳镜,这也是官方给出的示例,所推崇的。
生成出来的效果还是挺不错的。
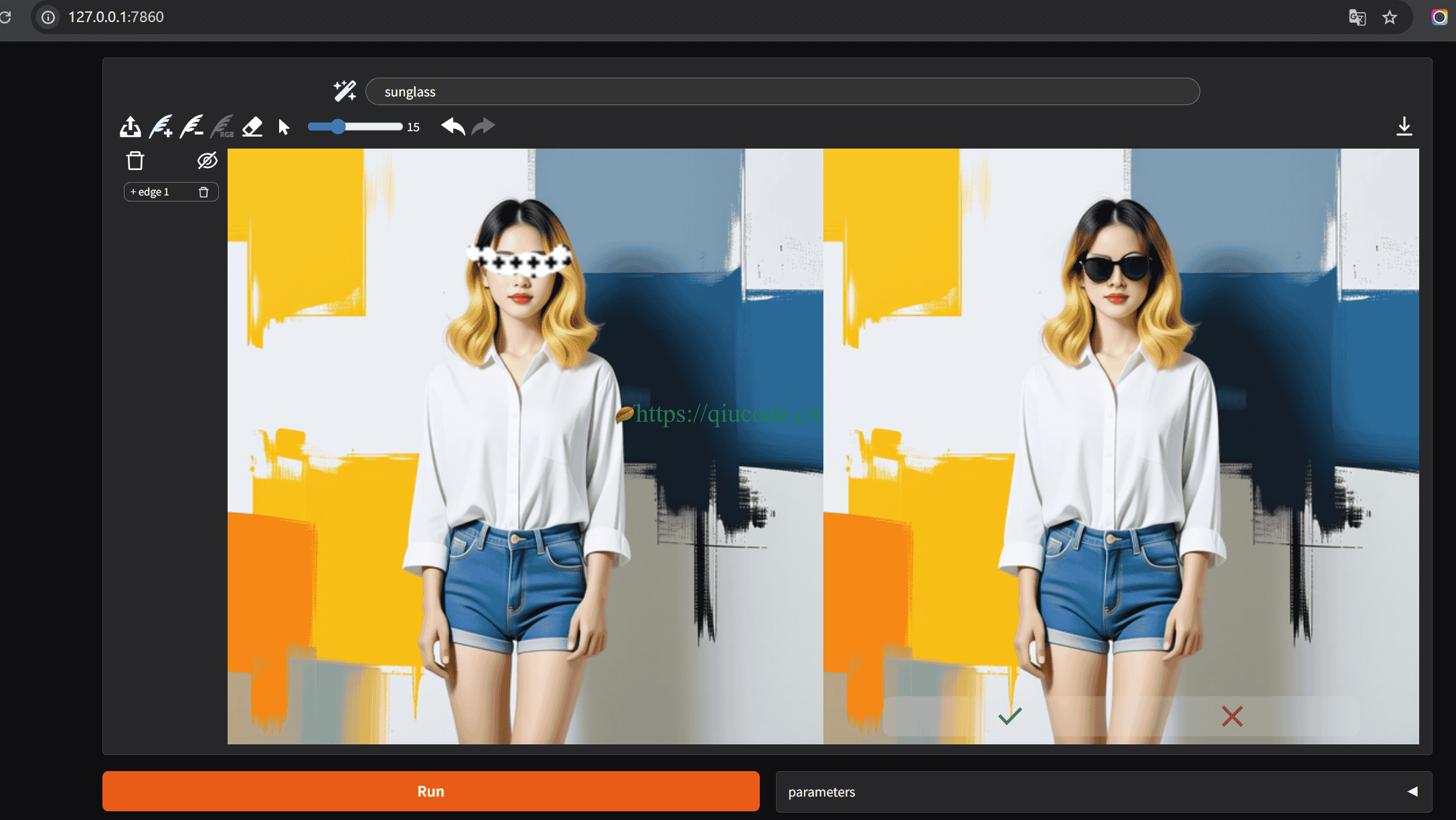
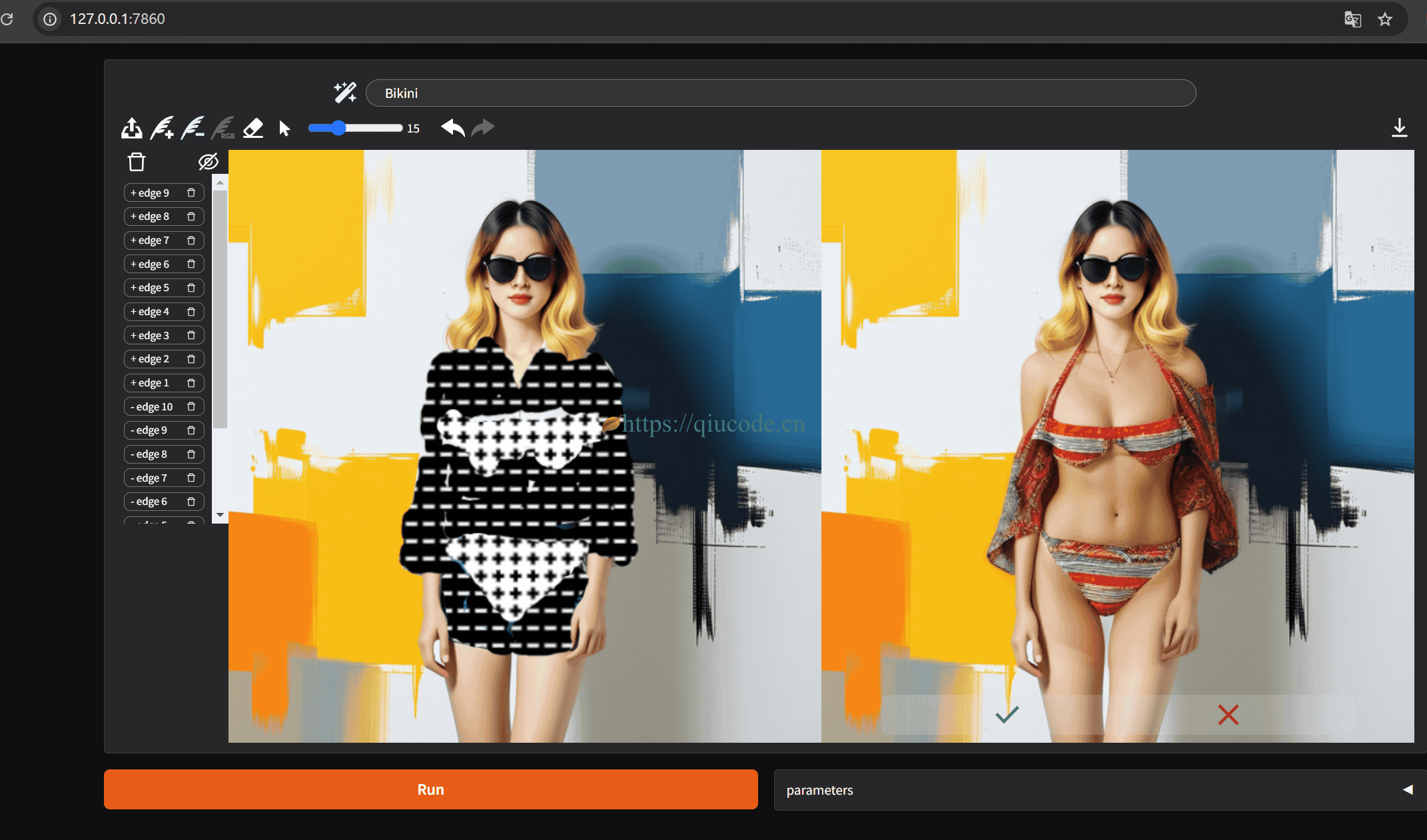
接下来,我们来点不一样的,让我们的肾腺直线飙升,对图中人物增删元素。
 2025-02-23 21:26:43 +0800 +0800
2025-02-23 21:26:43 +0800 +0800 2025-02-16 16:26:43 +0800 +0800
2025-02-16 16:26:43 +0800 +0800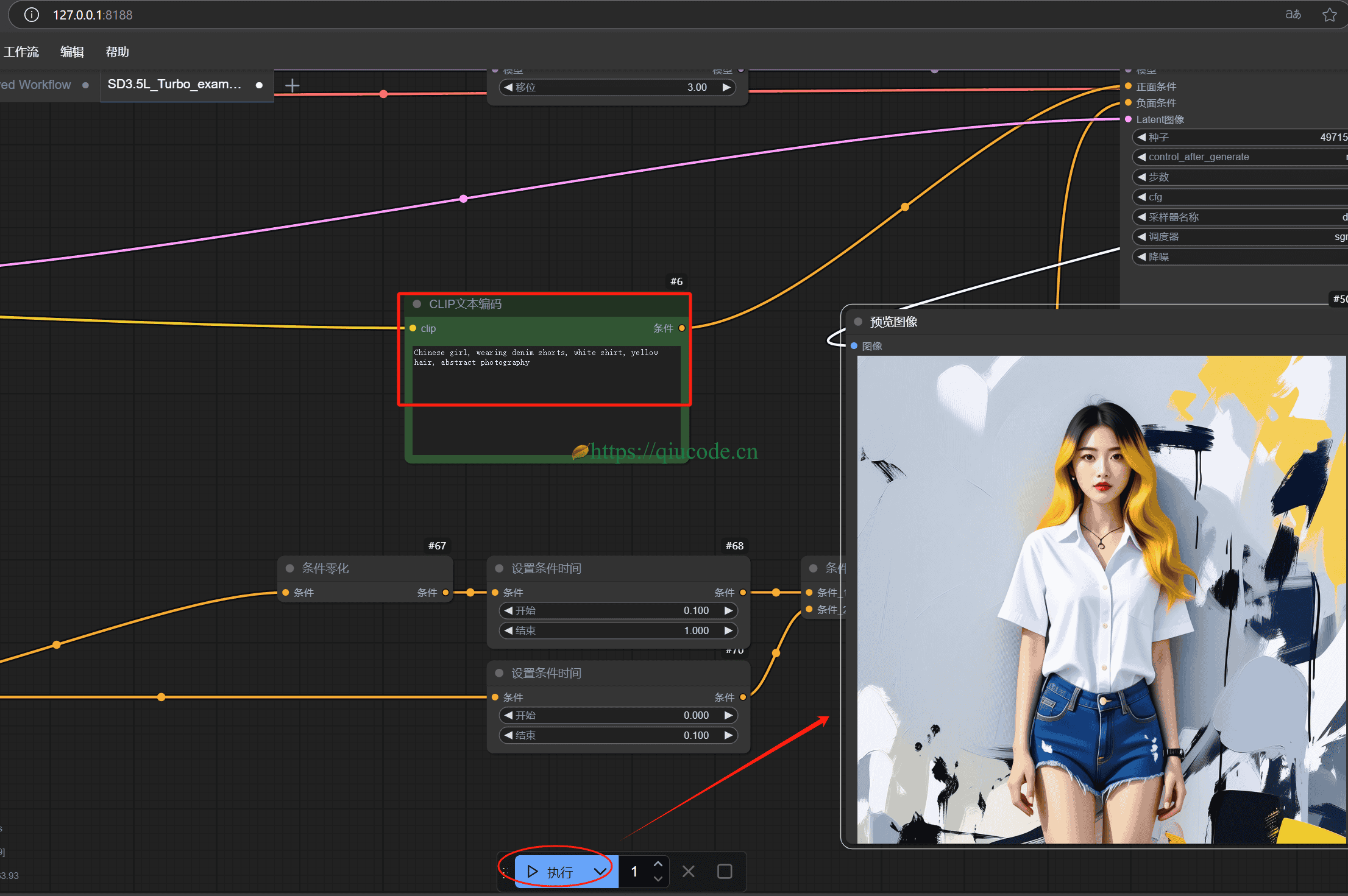 2025-02-03 20:26:43 +0800 +0800
2025-02-03 20:26:43 +0800 +0800