
说起文生音乐,我们自然会想到suno.ai这个音乐生成式平台,它算是目前市面上音乐生成式比较好的AI项目,虽然它是闭源的。
然而,一款由Multimodal Art Projection(M-A-P)(多模态艺术投影)团队与香港科技大学(HKUST)联合研发的YuE开源了,它是根据歌词生成整首歌的开源AI音乐模型。
YuE的开源,着实在开发者社区掀起了一阵热潮,但也给了AI浪潮中的文生音乐助推了不小波澜。
YuE 是一系列开创性的开源基础模型,专为音乐生成而设计,专门用于将歌词转换成完整的歌曲(lyrics2song)。它可以生成一首完整的歌曲,持续几分钟,包括朗朗上口的声乐曲目和伴奏曲目。YuE 能够模拟多种流派/语言/声乐技巧。请访问演示页面,了解令人惊叹的声乐表演。
概述
YuE项目地址:https://github.com/multimodal-art-projection/YuE 。
按照官方描述:
YuE 需要大量 GPU 来生成长序列。以下是推荐的配置:
对于具有 24GB 或更少的 GPU:运行最多 2 个会话以避免内存不足 (OOM) 错误。
对于完整的歌曲生成(许多会话,例如 4 个或更多):使用具有至少 80GB 的 GPU。即 H800、A100 或具有张量并行的多个 RTX4090。
要自定义会话数,界面允许您指定所需的会话数。默认情况下,模型运行 2 个会话(1 节 + 1 合唱)以避免 OOM 问题。
在 H800 GPU 上,生成 30 秒的音频需要 150 秒。在 RTX 4090 GPU 上,生成 30 秒的音频大约需要 360 秒。
社区提供了对于 GPU 资源有限的人,有 YuE-exllamav2 和 YuEGP。虽然两者都提高了生成速度和连贯性,但它们可能会损害音乐性。
YuEGP github地址:https://github.com/deepbeepmeep/YuEGP 。
YuE-exllamav2 github地址: https://github.com/sgsdxzy/YuE-exllamav2。
本地部署 YuEGP
我先在本地部署社区提供的低显存占用的YuEGP。
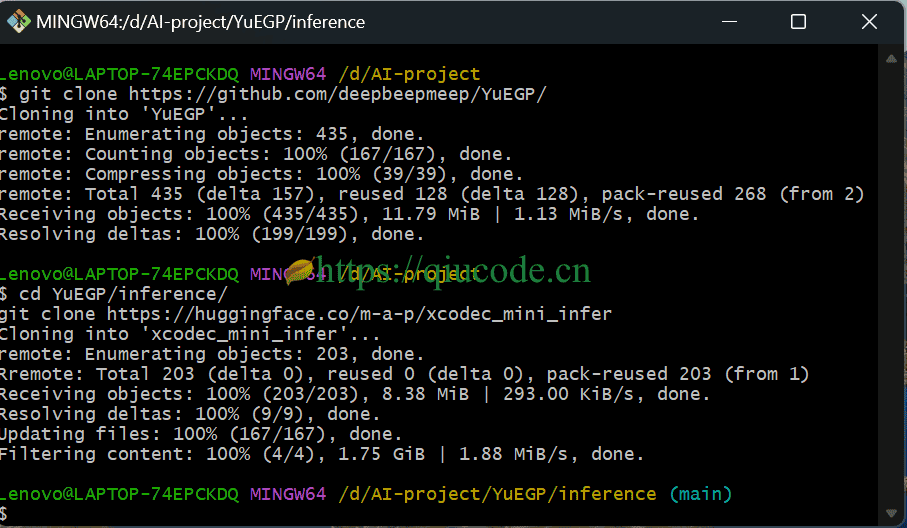
clone 推理代码
我们我先把推理代码clone下来。
git lfs install
git clone https://github.com/deepbeepmeep/YuEGP/
cd YuEGP/inference/
git clone https://huggingface.co/m-a-p/xcodec_mini_infer
创建虚拟环境
随后,我们使用python3自带的venv来创建虚拟环境,当然咯,你也是可以使用anaconda或miniconda来搭建python虚拟环境。
python -m venv YuEGP-env
cd YuEGP-env/Scripts
activate
安装GPU版的torch
设置清华源镜像
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
安装CUDA对应版本的torch。
pip install torch==2.5.1 torchvision torchaudio --index-url https://download.pytorch.org/whl/test/cu124
安装 FlashAttention 2
虽然官方说这个是可选的,但是你不安装这个,是运行不起来的,因为代码中有使用了flashAttention2。
在安装flashAttention2之前,你得保证你安装的CUDA版本是在12.4以上。
在 阿里云开源的文生视频万相 Wan2.1之本地部署Wan2.1-T2V-1.3B模型 中有介绍该如何在windows中安装,如果你是第一次安装的话,可以参考这篇文章,这里就不再赘述了。
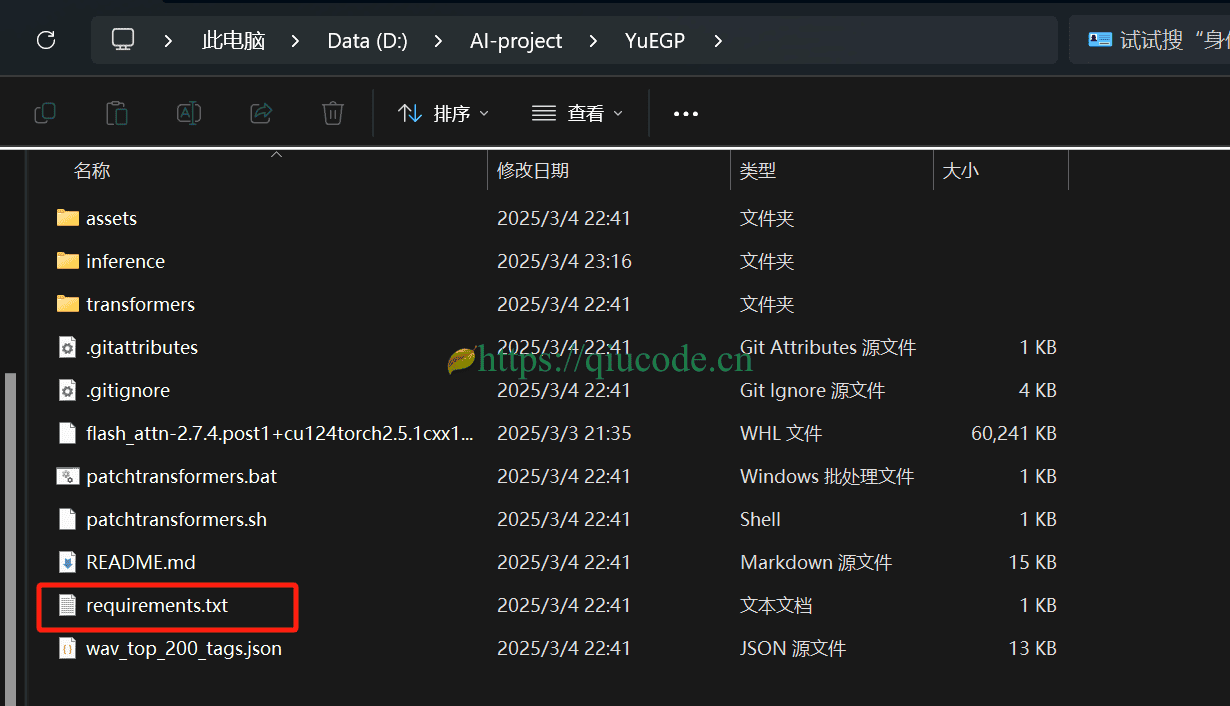
安装项目所需的依赖
pip install -r requirements.txt
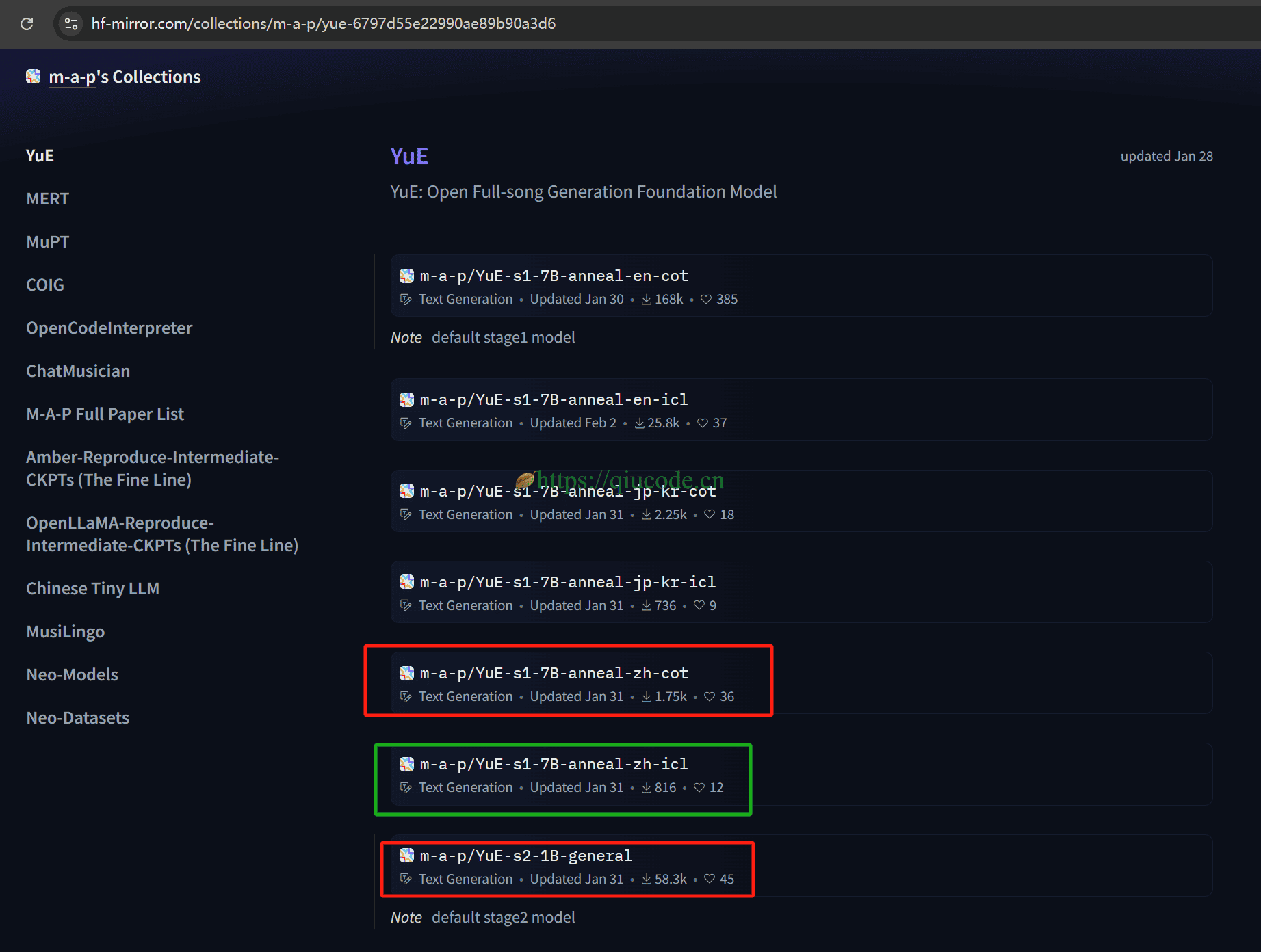
下载模型
国内可访问的:https://hf-mirror.com/collections/m-a-p/yue-6797d55e22990ae89b90a3d6。
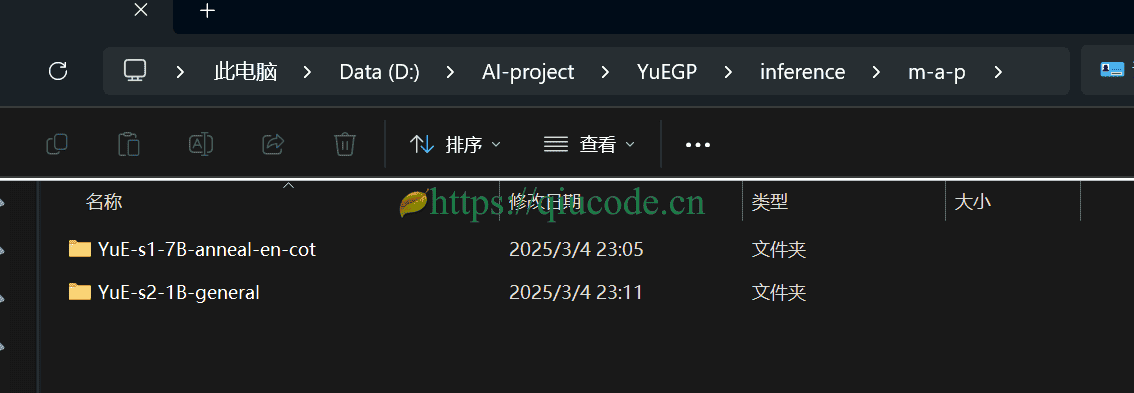
下载的模型存放于inference/m-a-p目录。
运行项目
cd inference
python gradio_server.py
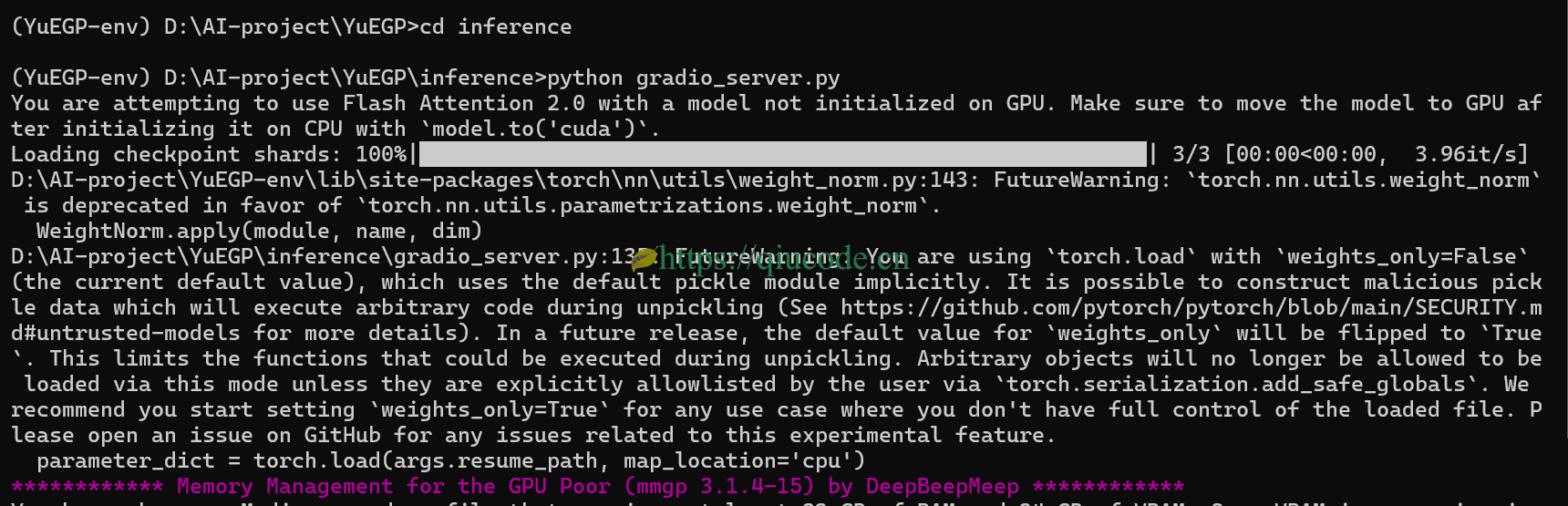
打开你常用的浏览器,在地址栏输入127.0.0.1:7860.
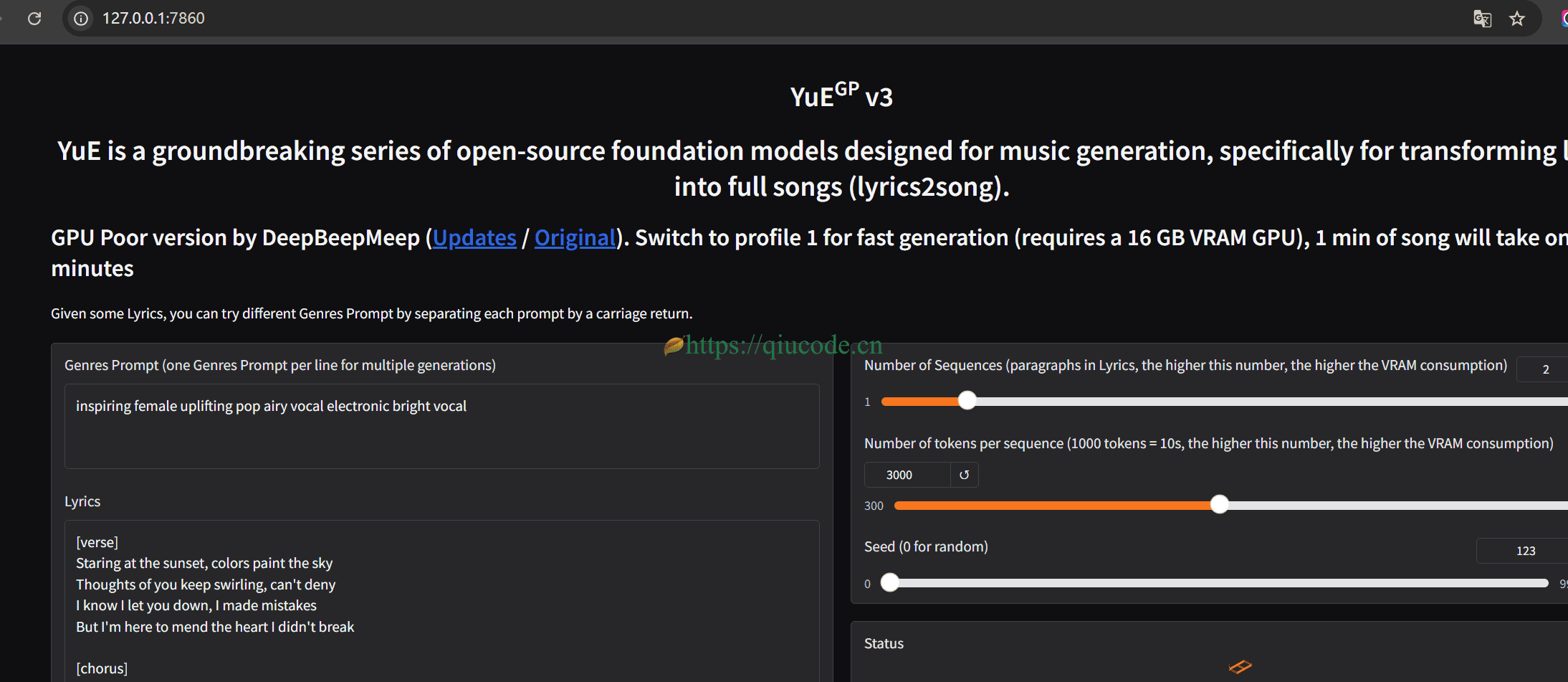
可以调整参数来加速生成。
 2025-03-01 21:26:43 +0800 +0800
2025-03-01 21:26:43 +0800 +0800 2025-02-25 22:26:43 +0800 +0800
2025-02-25 22:26:43 +0800 +0800 2025-02-23 21:26:43 +0800 +0800
2025-02-23 21:26:43 +0800 +0800 2025-02-16 16:26:43 +0800 +0800
2025-02-16 16:26:43 +0800 +0800 2025-02-03 20:26:43 +0800 +0800
2025-02-03 20:26:43 +0800 +0800