
在文生图这个领域里,甭管是开源的Stable Diffusion 3.5,还是闭源的在线绘图平台Midjourney,一度都是不支持中文提示词。
连prompt都不支持中文,就别提想要在图中写入中文。
虽然SD3.5、Midjourney等优秀绘画模型不支持中文提示词,但国内各大厂商一直致力于中文提示词。
CogView4-6B是智谱AI(Zhipu AI)推出的文生图模型,通过结合文本与图像的跨模态生成技术,在中文场景下展现出显著优势。
本地部署
那么,接下来,我们就在本地电脑部署下CogView4-6B这款开源的绘画模型,看看效果是否真有其官方宣传的那么好。
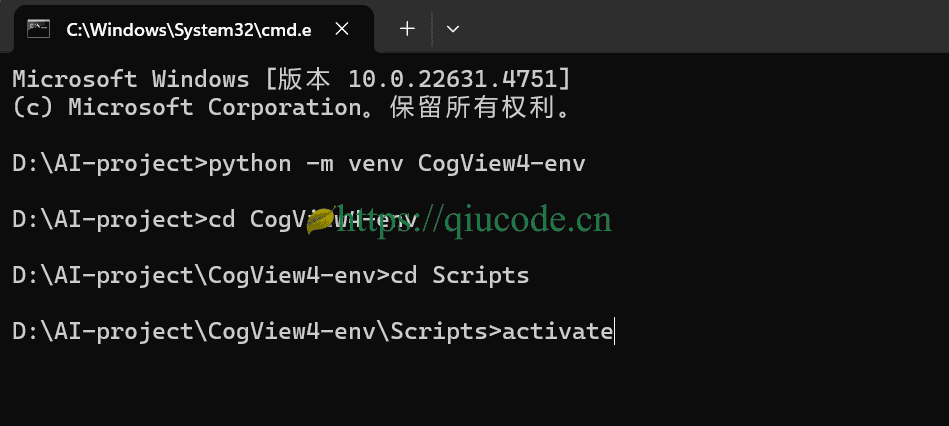
创建虚拟环境
首先,我们创建个python虚拟环境,你可以使用anaconda或miniconda来创建虚拟环境。我还是使用python3自带的venv模块搭建的虚拟环境。
我电脑使用的python版本为python 3.10.9,当然你也可以使用python 3.11。
python -m venv CogView4-env
cd CogView4-env\Scripts
activate
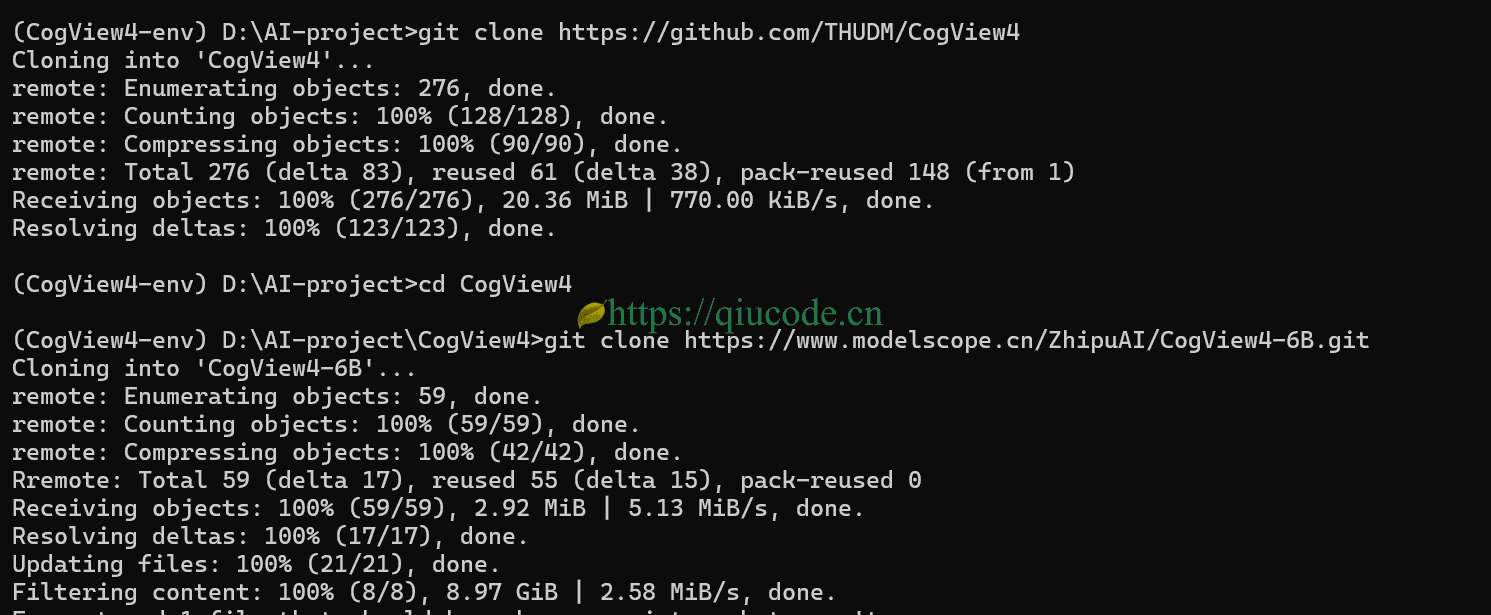
clone 推理代码及下载模型
git clone https://github.com/THUDM/CogView4
cd CogView4
# 根据自身网络条件 选择以下任一方式来下载模型。
# modelscope
git clone https://www.modelscope.cn/ZhipuAI/CogView4-6B.git
# Huggingface.co
git clone https://huggingface.co/THUDM/CogView4-6B
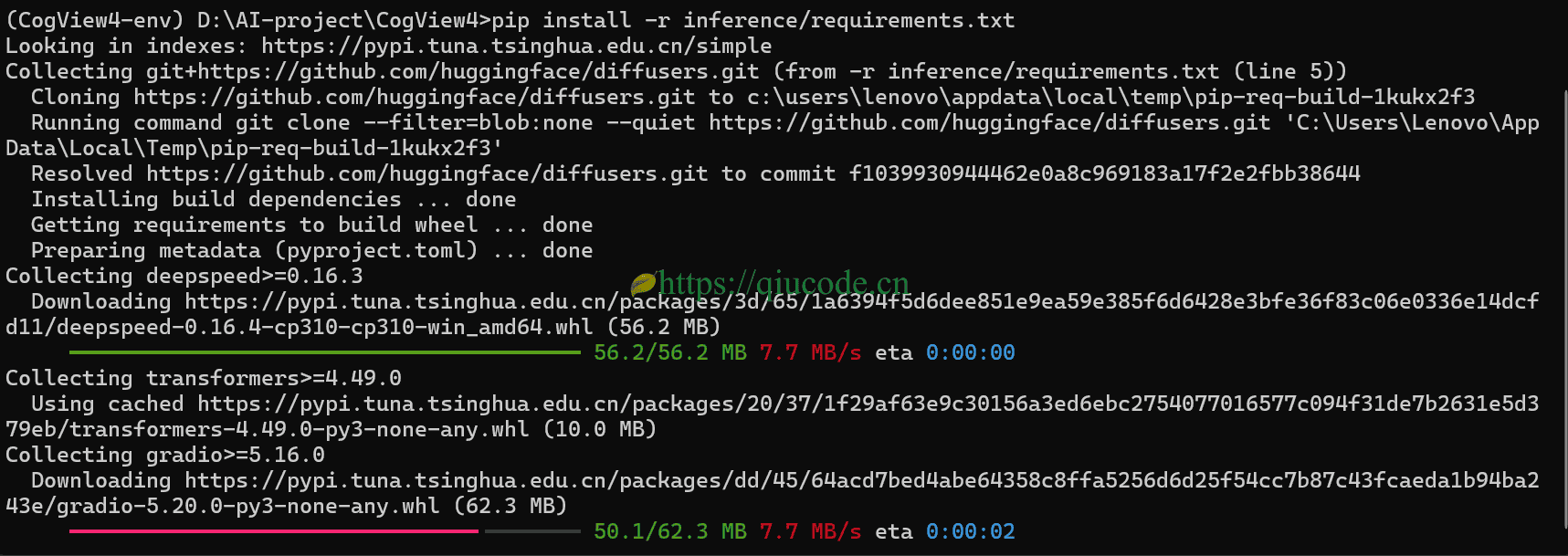
安装项目所需依赖
其实,如果按照官方的,也就是执行以下这行命令,是无法启动项目的。
pip install -r inference/requirements.txt
按照requirements.txt的依赖来安装torch是CPU版本,并不支持GPU,所以我们需要uninstall这个不带GPU版本的torch以及torchao。
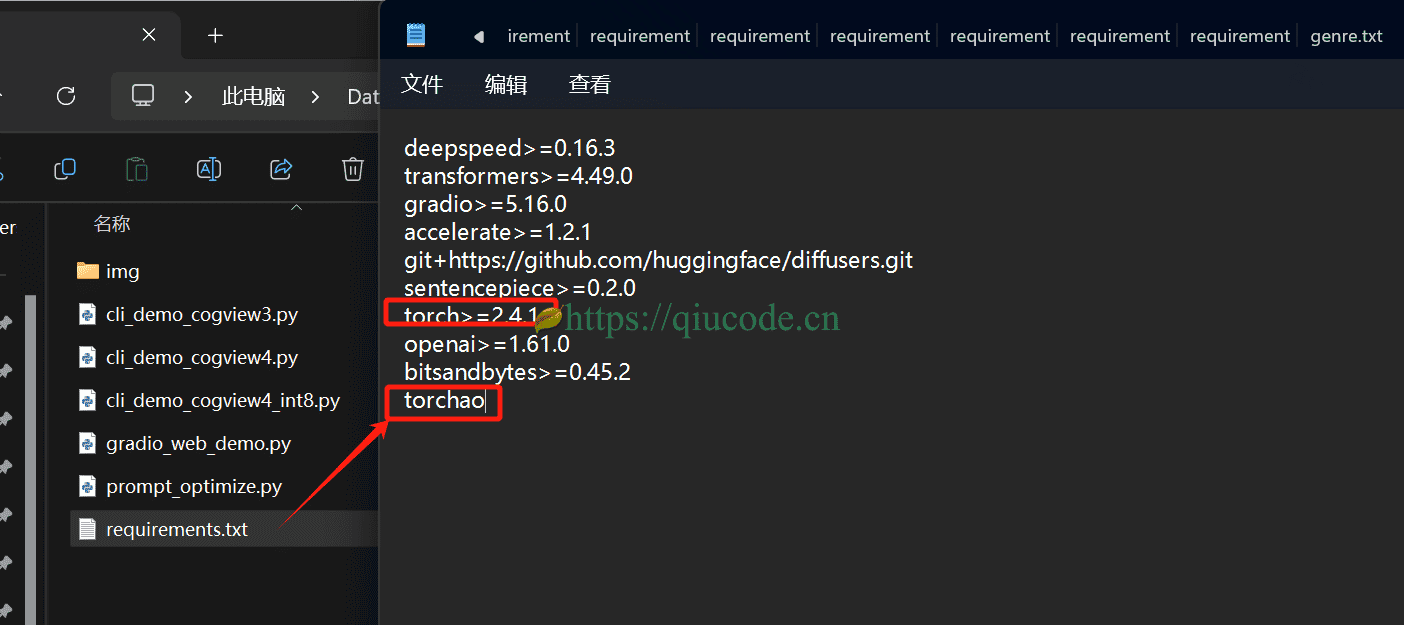
如果你电脑的显存低于12G的话,那么需要设置set MODE=1。
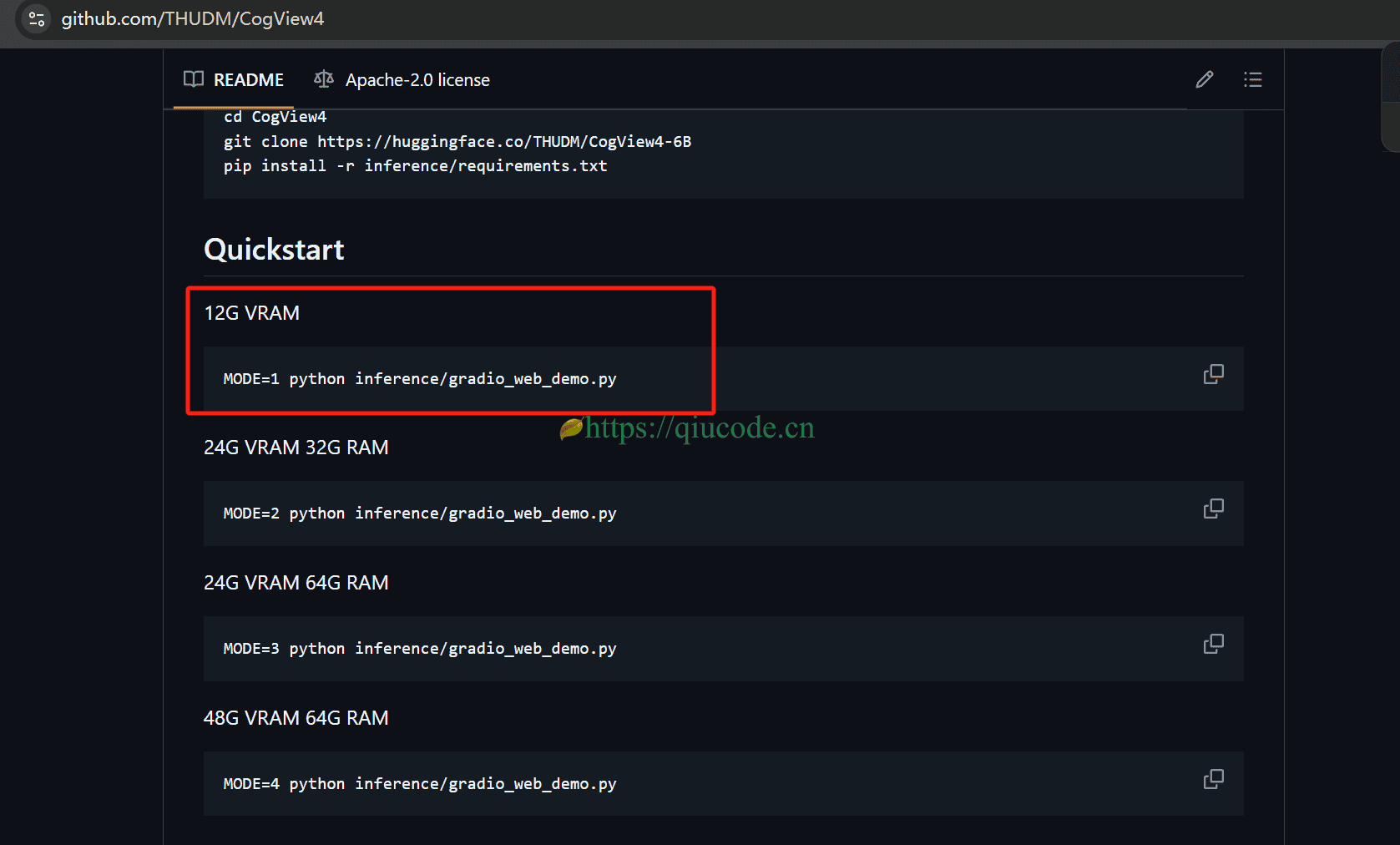
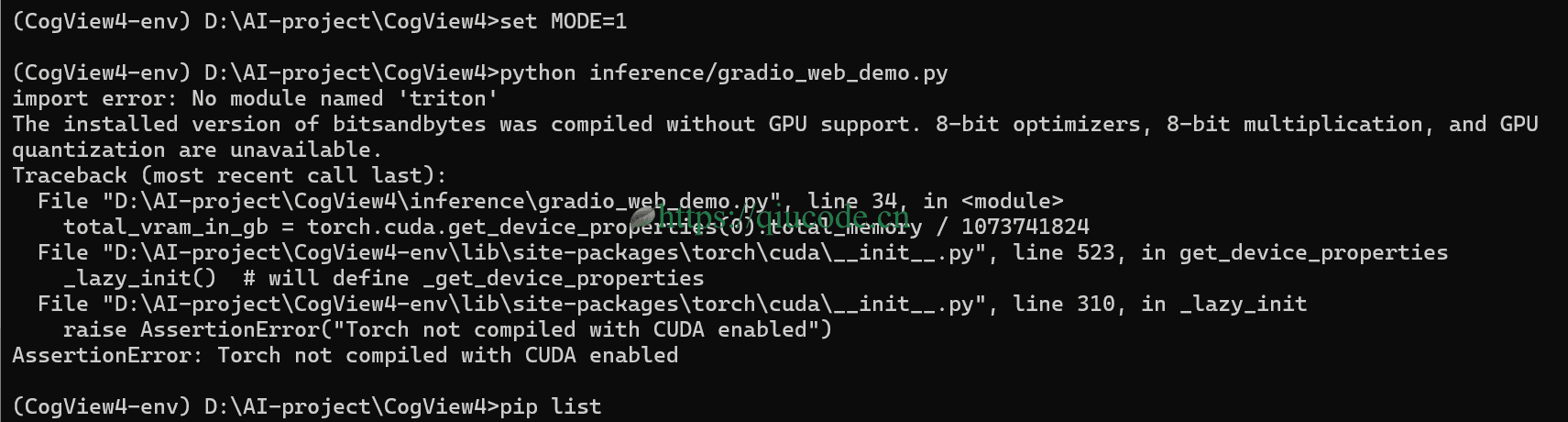
然而,在Terminal下载torch的CUDA版本,下载速度总是那么不尽如人意。
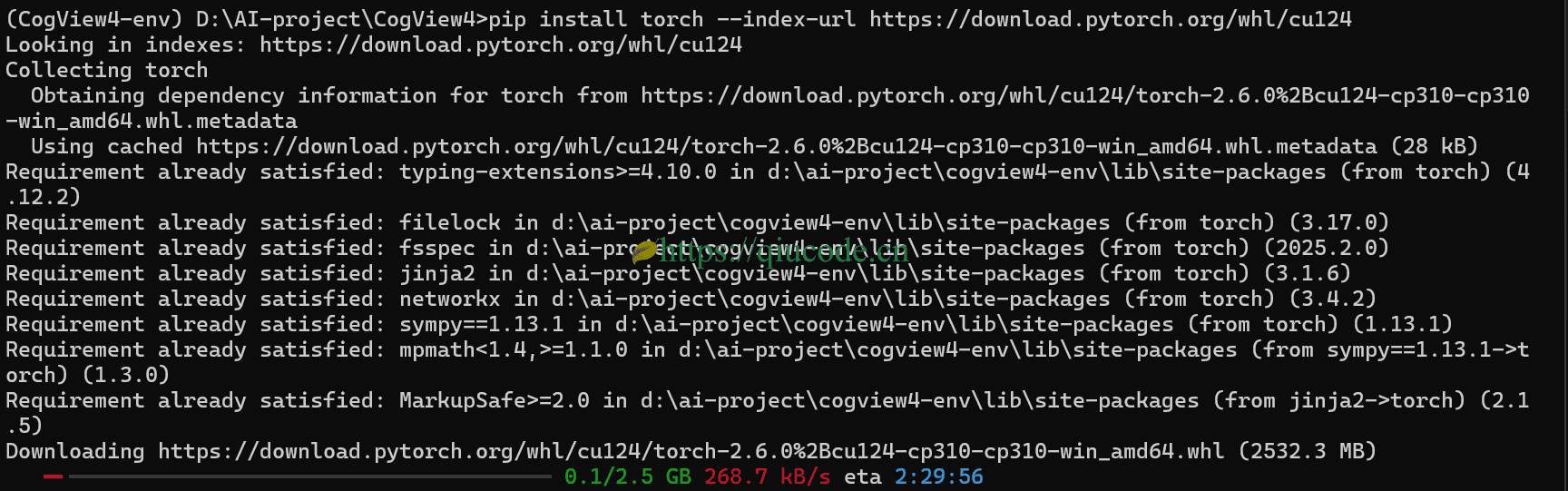
那么,我们可以直接去https://download.pytorch.org/whl/torch 下载 对应的whl文件。
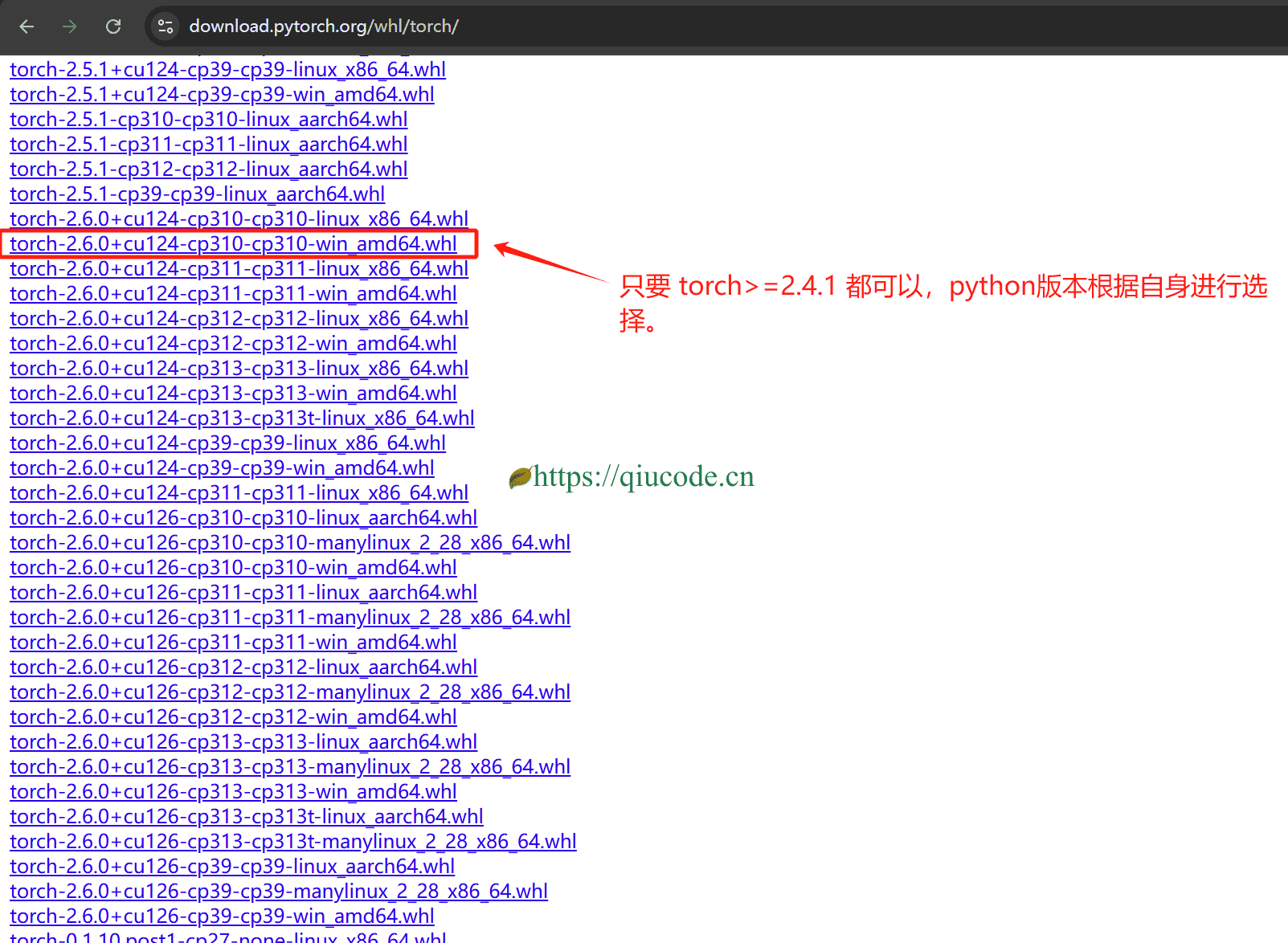
我们直接在Terminal直接pip install torch-xxx.whl。
卸载CPU版的torchao,安装带有CUDA版本的torchao。
运行 inference/gradio_web_demo.py
当我们安装好了CUDA版的torch和torchao后,再次执行python inference/gradio_web_demo.py。
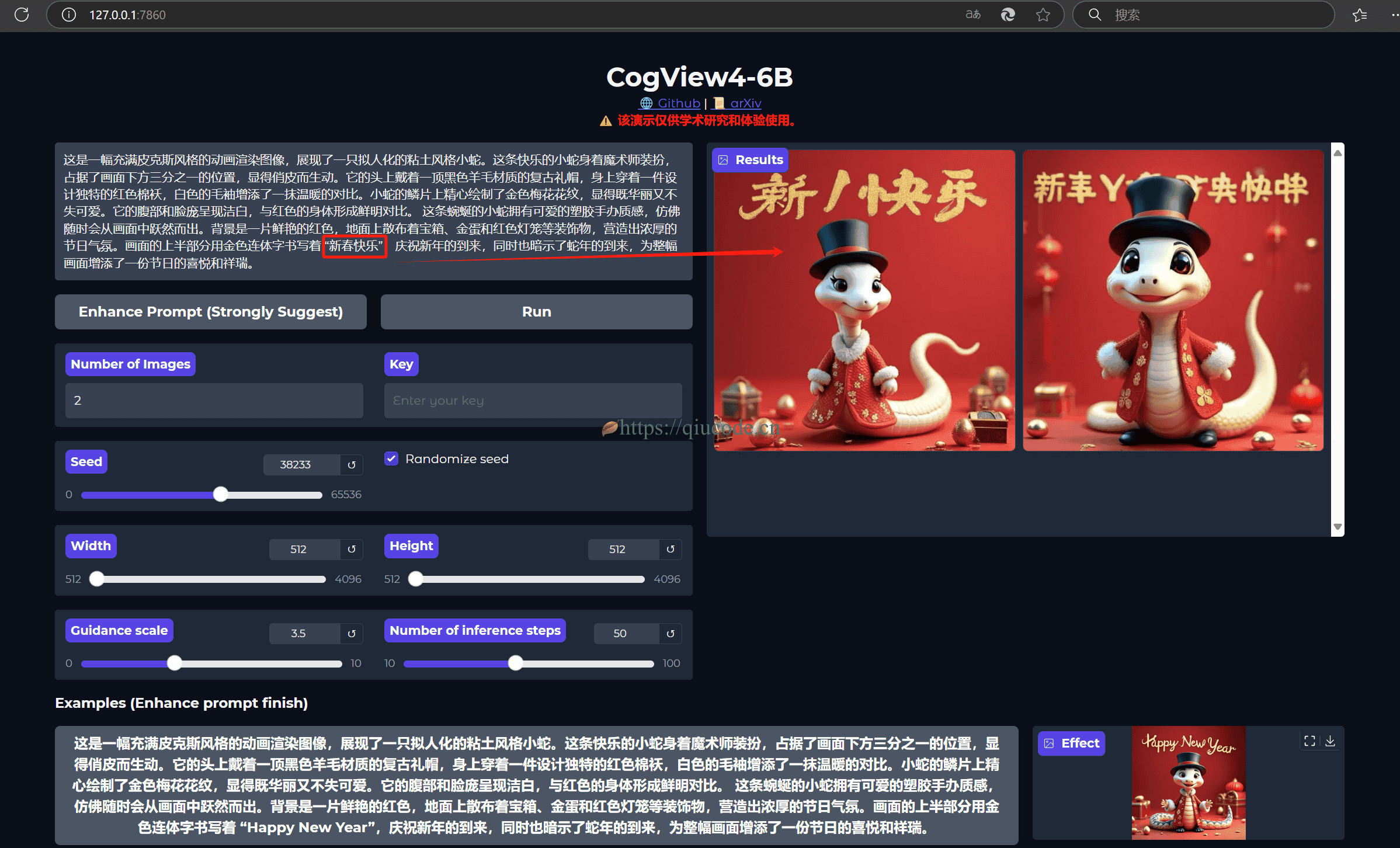
会为我们自动在默认浏览器打开一个页签,如下图。
我这里使用了官方的prompt,只是把Happy New Year改成了新春快乐,看看是不是能真正的写上中文字。
为了出图快点,我只修改了图片的width和height,其他都是默认的,然而,生成的图片,图中的中文文字却崩了。
 2025-02-16 16:26:43 +0800 +0800
2025-02-16 16:26:43 +0800 +0800 2025-03-05 21:26:43 +0800 +0800
2025-03-05 21:26:43 +0800 +0800 2025-03-01 21:26:43 +0800 +0800
2025-03-01 21:26:43 +0800 +0800 2025-02-25 22:26:43 +0800 +0800
2025-02-25 22:26:43 +0800 +0800 2025-02-23 21:26:43 +0800 +0800
2025-02-23 21:26:43 +0800 +0800