
在人工智能时代,语音合成(TTS)技术已成为人机交互的核心组件之一。然而,传统TTS系统长期受限于多阶段架构复杂、语音控制能力弱、跨语言表现差等问题。
基于Qwen2.5大模型的**Spark-TTS**横空出世,凭借其创新的BiCodec编码技术、零样本语音克隆能力和细粒度语音控制,迅速成为开源社区的热点。
技术突破:Spark-TTS的三大创新
1、BiCodec:重新定义语音编码 Spark-TTS首创BiCodec单流语音编码器,将语音分解为两类核心编码:
- 语义Tokens:低比特率捕捉语言内容,确保信息的高效传输。
- 全局Tokens:固定长度编码说话人属性(音色、性别、语调等)。 这种设计简化了传统
TTS的多模型协作流程,实现端到端生成,推理速度提升30%以上
2、零样本语音克隆:无需训练,秒级复刻
仅需3秒参考音频,Spark-TTS即可生成高度相似的个性化语音,音色一致性(SIM)指标超越同类模型如LLaMA-TTS。其核心在于结合Qwen2.5的语言理解能力与BiCodec的解码精度,突破了传统TTS依赖大量训练数据的限制。
3、细粒度语音控制:从参数到情感的精准调节
- 粗粒度:性别、情感风格一键切换。
- 细粒度:音高、语速、停顿时长可逐句微调。 用户甚至可通过文本描述生成虚拟音色(如“沉稳的中年男声,语速加快20%”),远超传统基于参考音频的模拟方式。
功能实测:性能与效果全解析
多语言与跨语种切换
Spark-TTS支持中英文无缝切换,无需单独训练语言模型。例如,输入混合文本“2025年Q1财报增长15%”,合成语音能自然处理数字与语言边界,避免传统TTS的机械断句问题 。语音质量指标
自然度(MOS):评分>4.5(满分5),接近真人水平。
重建质量:在STOI、PESQ等指标上超越
VITS、FastSpeech2等主流模型。实时性(RTF)
:单GPU推理速度达0.15秒/秒,满足实时交互需求。
实战对比:与其他开源TTS的差异 数据来源:公开评测与社区实测
项目 零样本克隆 多语言支持 细粒度控制 推理速度 Spark-TTS ✅ 中英 ✅ 快 CosyVoice2 ✅ 中英 ❌ 中等 Fish-Speech ❌ 中英日 ❌ 慢
本地部署
那么接下来,我们将在本地电脑部署这款开源的文本转语音模型,看看效果是否真如官方所宣传的那般。
我还是一如既往的使用python3自带的venv模块来创建python 虚拟环境,当然,你也是可以使用anaconda或着miniconda等软件来搭建python 虚拟环境。
我本地电脑使用python的版本,始终是python 3.10.9,系统则是windows11。
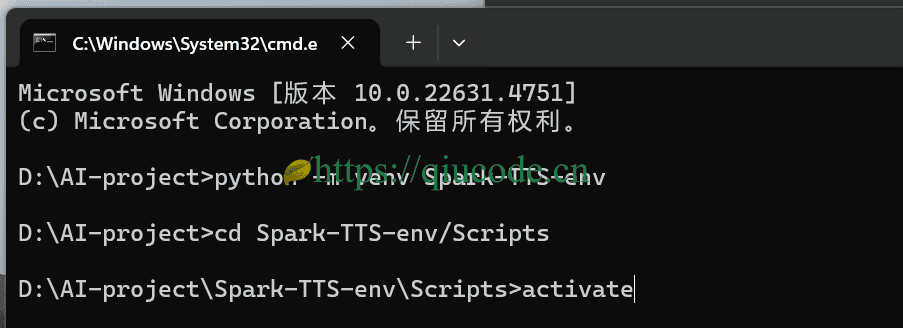
创建python虚拟环境
python -m venv Spark-TTS-env
cd Spark-TTS-env/Scripts
activate
clone推理代码
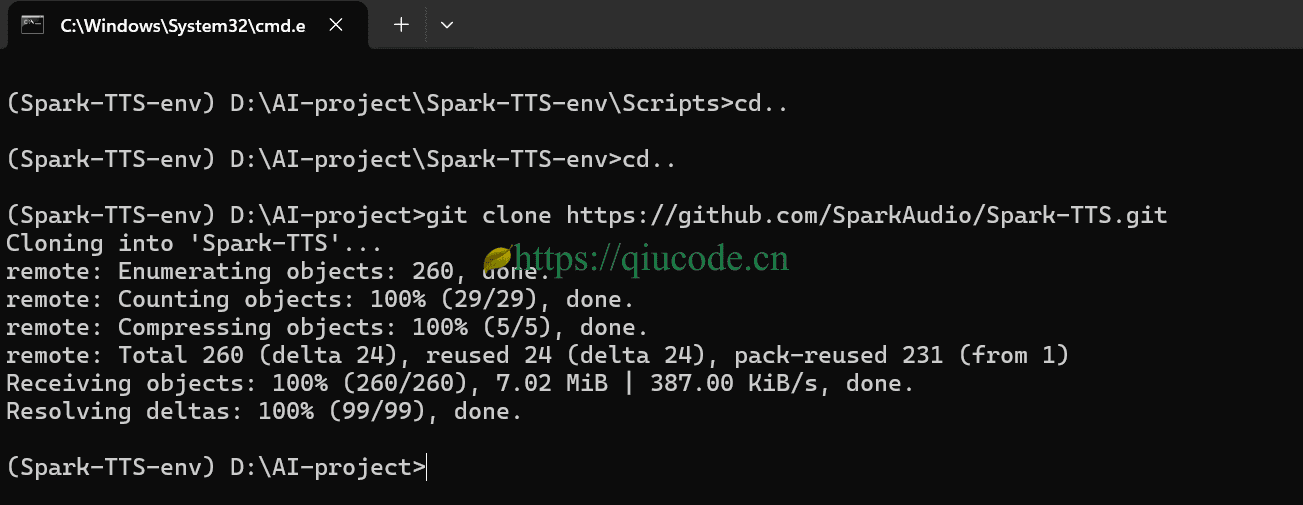
Spark-TTS的推理代码托管于享誉全球的github.com上,倘若你的电脑安装了git,那么直接在Terminal中执行以下命令,便把Spark-TTS推理代码下载到你的电脑硬盘里。
git clone https://github.com/SparkAudio/Spark-TTS.git
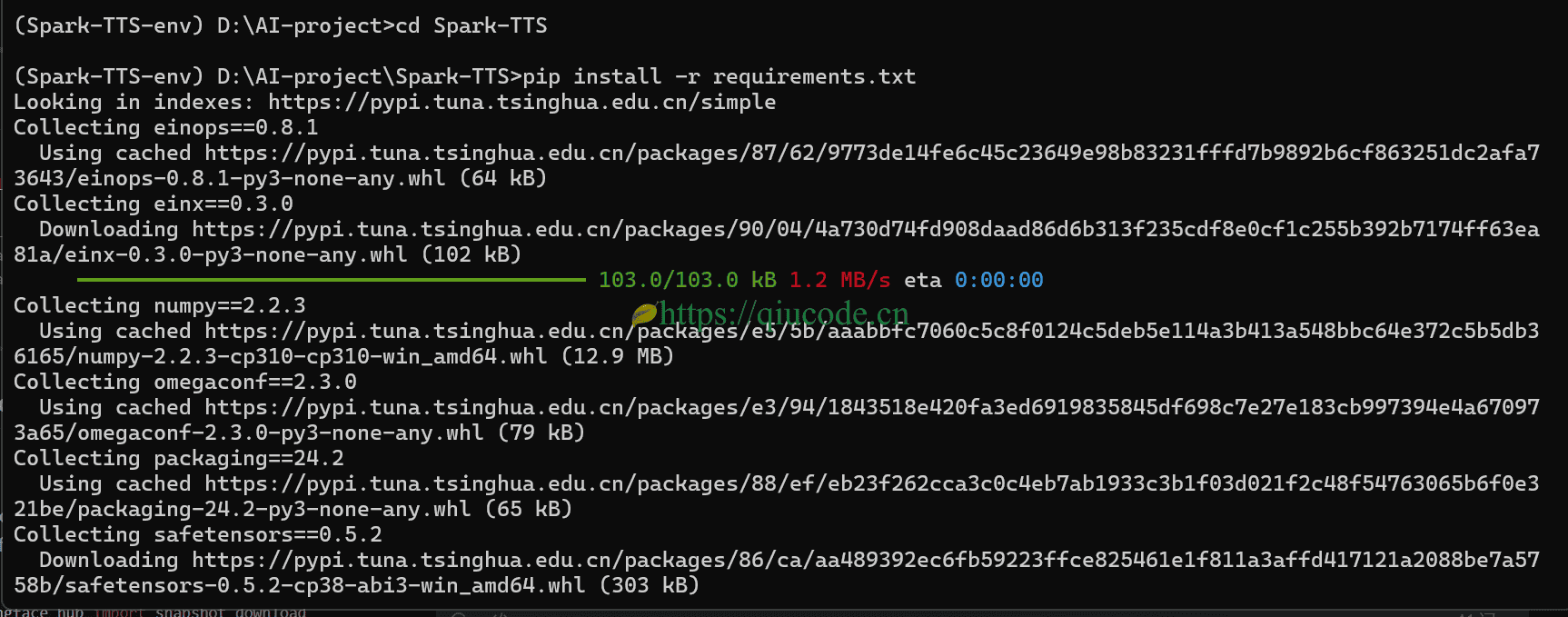
安装项目所需的依赖
pip install -r requirements.txt
安装CUDA版的torch(可选)
这一步是可选的,项目是可以通过CPU来推理的,也就是刚刚安装的torch是CPU版的,如果你想要使用GPU来加速推理,那么,就先卸载CPU版的torch,安装支持GPU的torch。
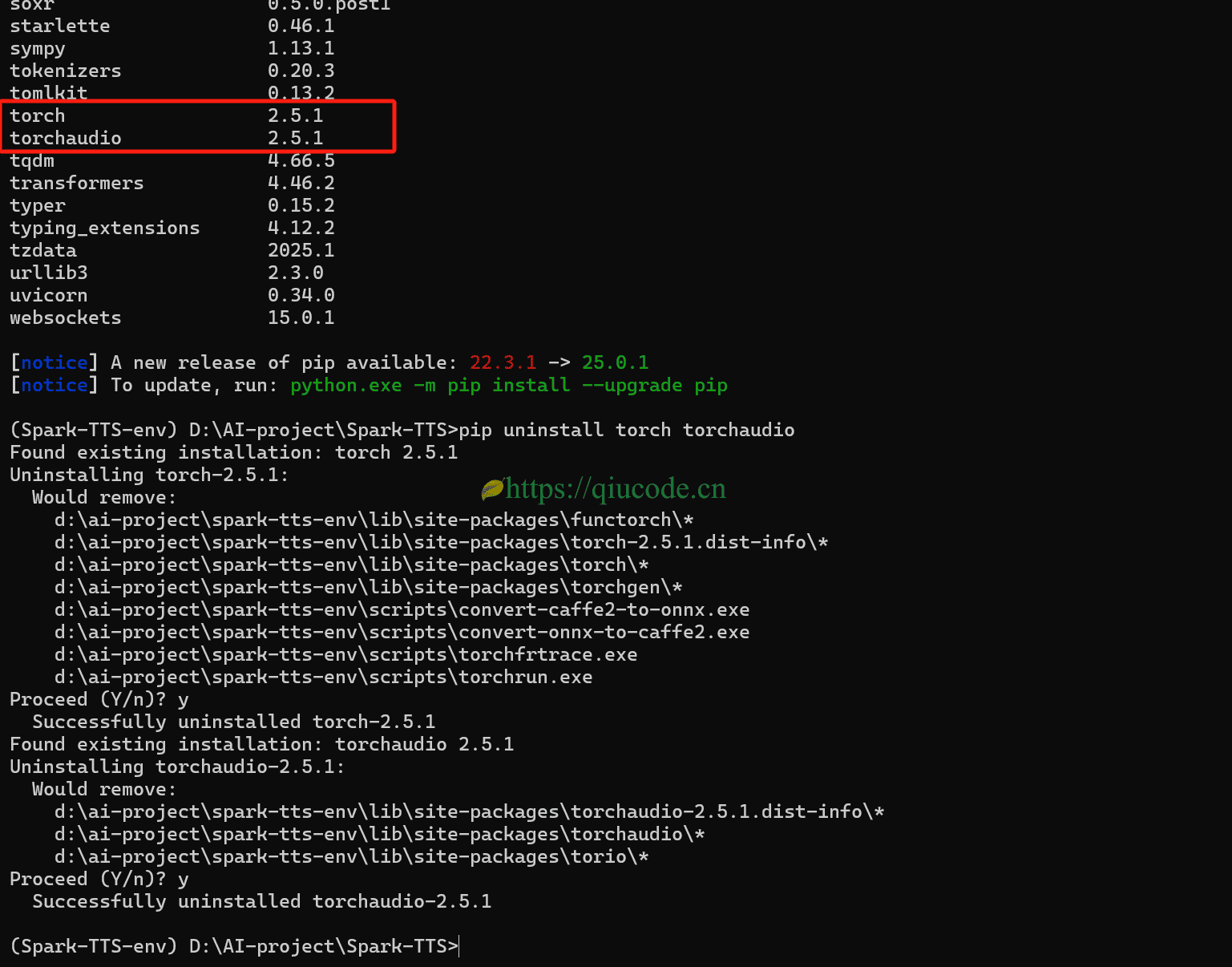
我们在安装CUDA版torch,其版本尽量于requirements.txt文件中的torch版本一样。
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124

下载模型
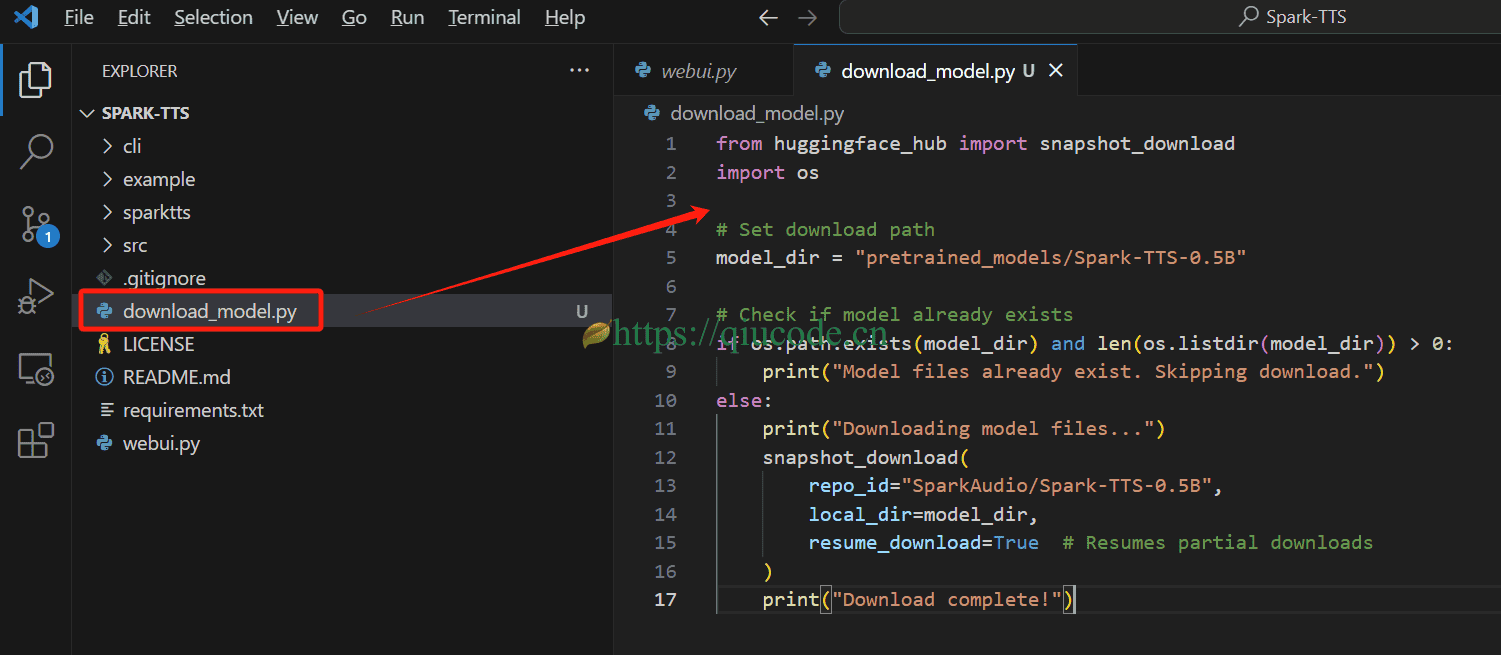
1、我们在项目根路径下创建一个名为download_model.py文件,输入以下内容。
from huggingface_hub import snapshot_download
import os
# Set download path
model_dir = "pretrained_models/Spark-TTS-0.5B"
# Check if model already exists
if os.path.exists(model_dir) and len(os.listdir(model_dir)) > 0:
print("Model files already exist. Skipping download.")
else:
print("Downloading model files...")
snapshot_download(
repo_id="SparkAudio/Spark-TTS-0.5B",
local_dir=model_dir,
resume_download=True # Resumes partial downloads
)
print("Download complete!")
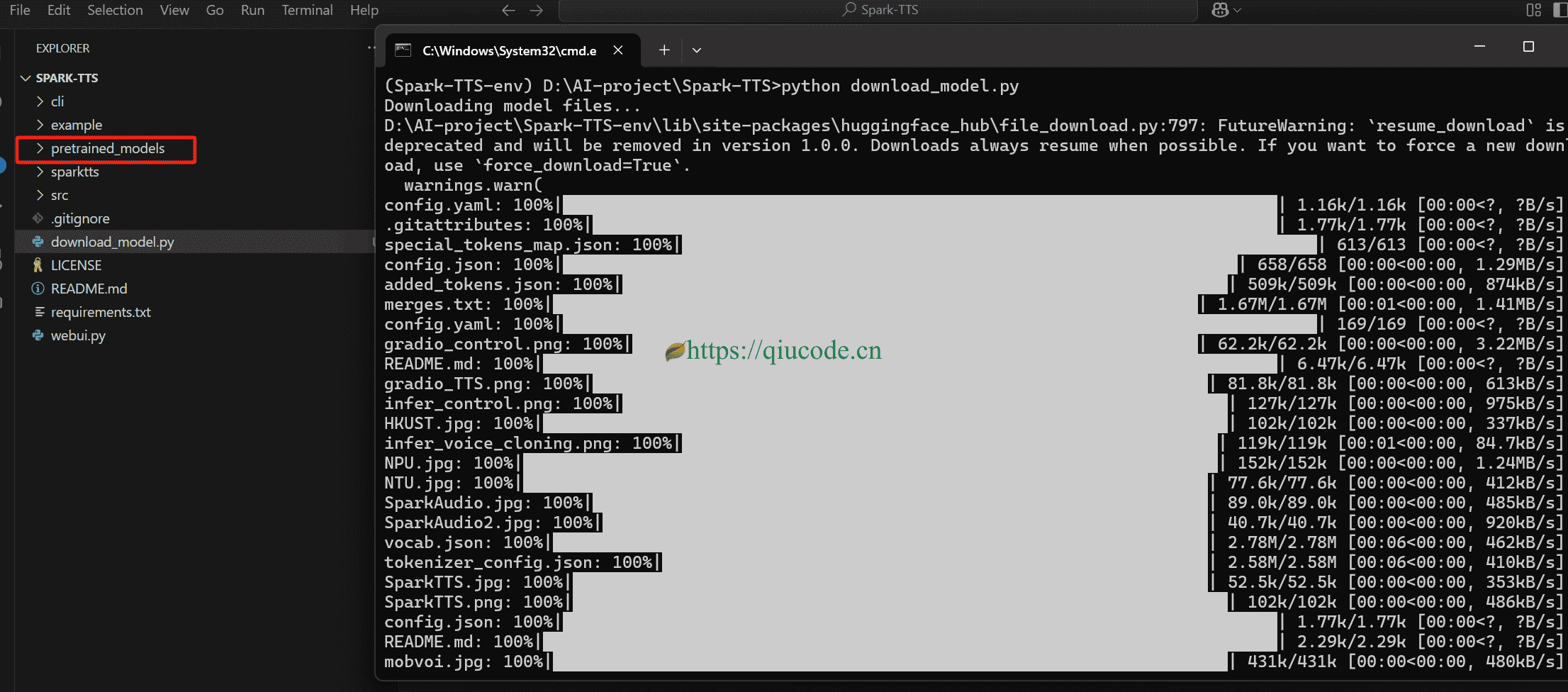
在执行python download_model.py命令之前,你得在Terminal(黑窗口)设置好网络,否则是下载不了模型的。
2、对于国内网友,长期遭受网络限制,可以在hf-mirror.com上下载模型。
mkdir pretrained_models
git clone https://hf-mirror.com/SparkAudio/Spark-TTS-0.5B pretrained_models/Spark-TTS-0.5B
运行 webui.py

等加载好模型后,会在我们电脑默认浏览器中的自动打开一页签。
我们先来使用模型自带的声音,来合成声音。
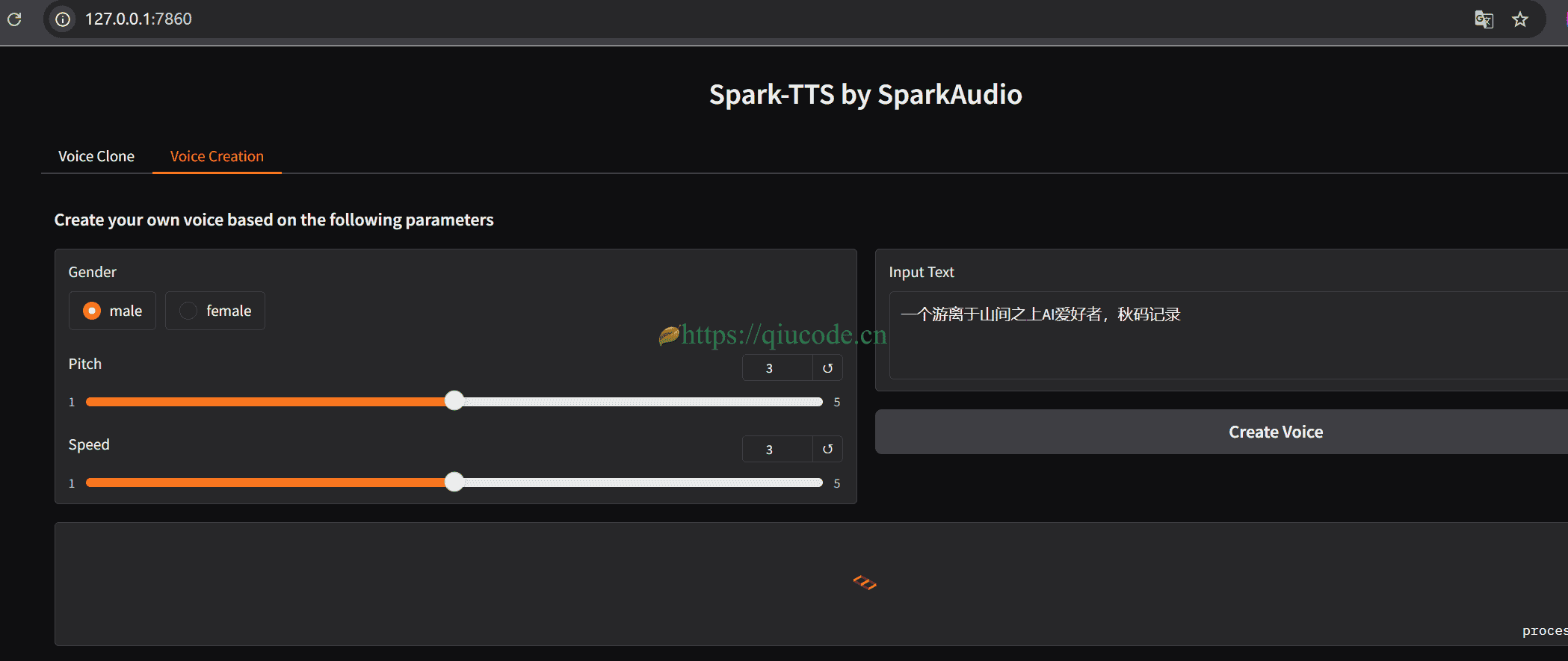
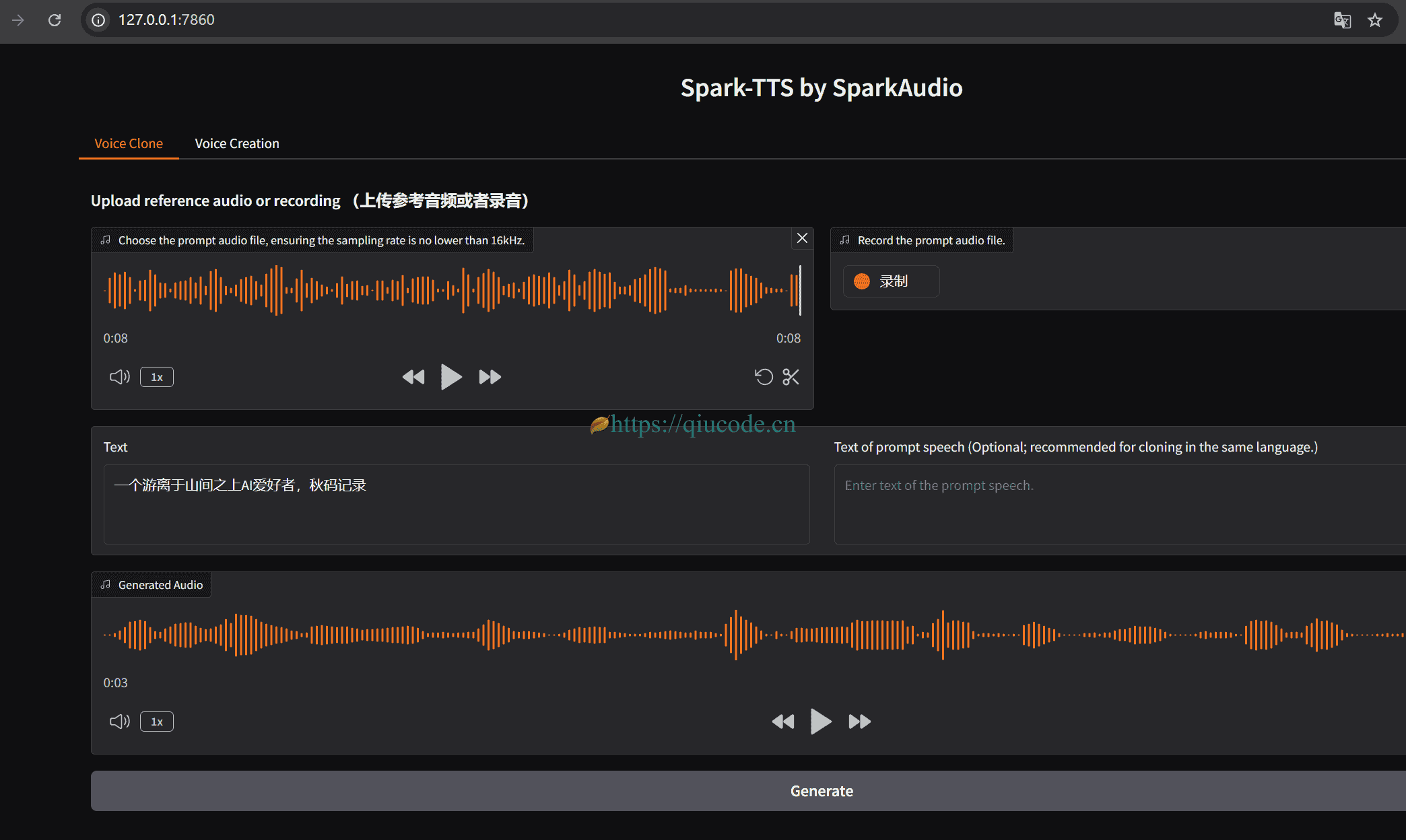
接下来,我们选择voice clone功能,来克隆音色,最终合成声音。
我这里使用的是伊万卡-特朗普一段在综艺频道的声音,当然,你也可以使用其他人的声音,前提是得得到别人授权的,否则的话……。
还有,待克隆的声音的采样率得是16KHZ,wav格式最佳。
 2025-03-07 21:26:43 +0800 +0800
2025-03-07 21:26:43 +0800 +0800 2025-03-05 21:26:43 +0800 +0800
2025-03-05 21:26:43 +0800 +0800 2025-03-01 21:26:43 +0800 +0800
2025-03-01 21:26:43 +0800 +0800 2025-02-25 22:26:43 +0800 +0800
2025-02-25 22:26:43 +0800 +0800 2025-02-23 21:26:43 +0800 +0800
2025-02-23 21:26:43 +0800 +0800