
Whisper是由OpenAI开发的开源语音识别模型,以其多语言支持、高准确率与鲁棒性著称。它通过68万小时的多语言、多任务数据训练,覆盖100+语言,支持语音转录、翻译和语言检测,成为目前最通用的语音识别工具之一。
其核心优势在于:
- 端到端训练:直接处理原始音频输入,无需复杂预处理,输出包含标点符号的完整文本。
- 噪声鲁棒性:在嘈杂环境、方言口音场景下仍能保持高精度。
- 多任务能力:支持语音翻译(如中文转英文)、时间戳标注等复杂任务。
本地安装
我始终使用python3自带的venv来搭建python虚拟环境,当然咯,你也是可以使用anaconda或miniconda来构建python虚拟环境。
python -m venv whisper-env
cd whisper-env/Scripts
activate

随后,我们安装openai-whisper这个依赖库。
pip install -U openai-whisper
或者直接从github.com仓库获取最新的。
# 或从 GitHub 安装最新版本
pip install git+https://github.com/openai/whisper.git
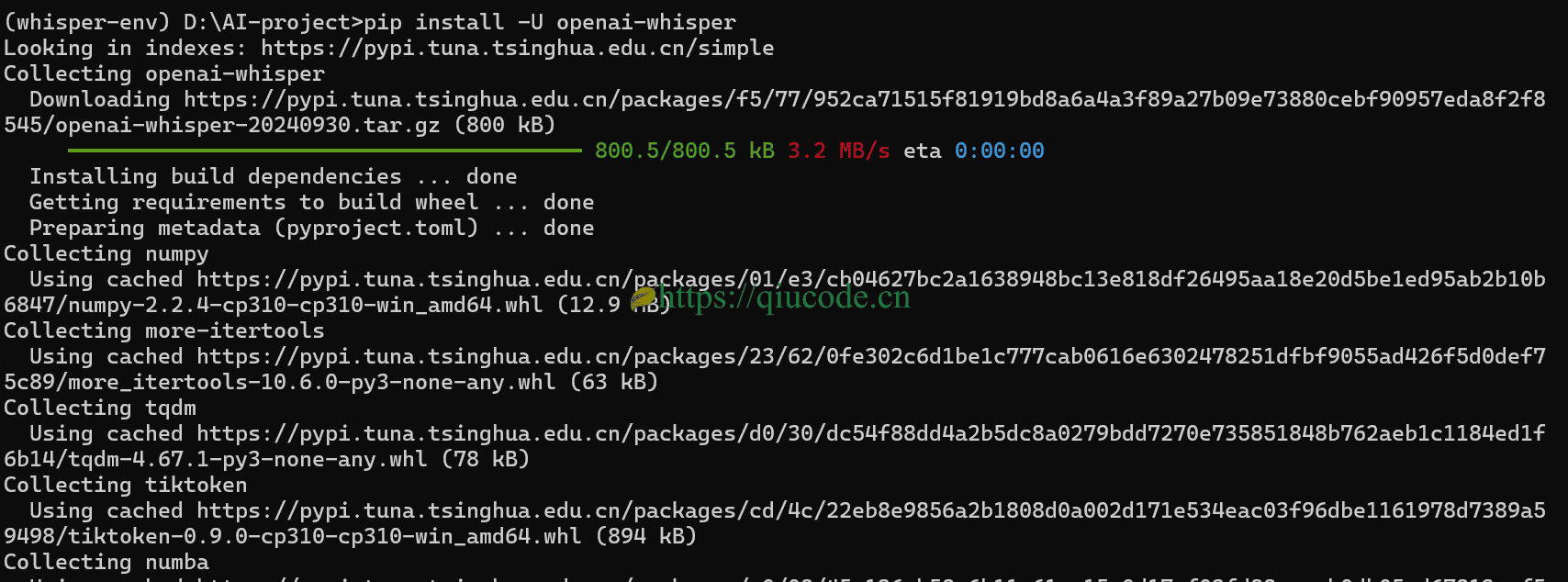
我们可以看到,所安装的依赖库中包含了tiktoken,故而,就不需要在安装了。
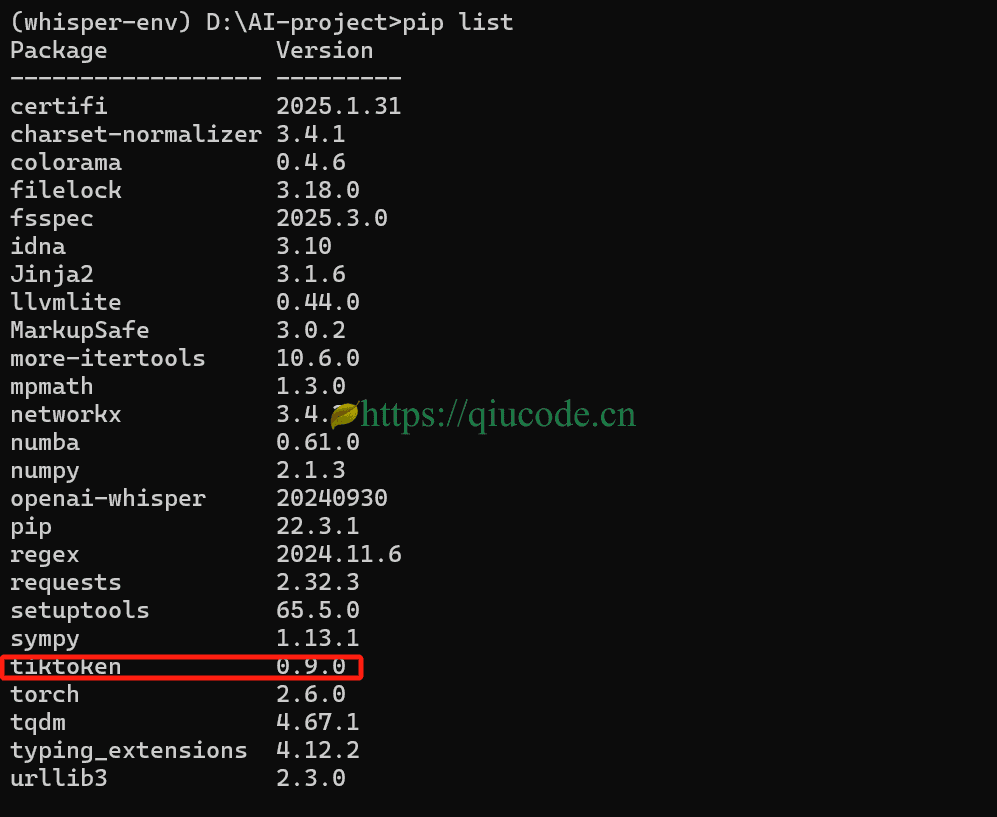
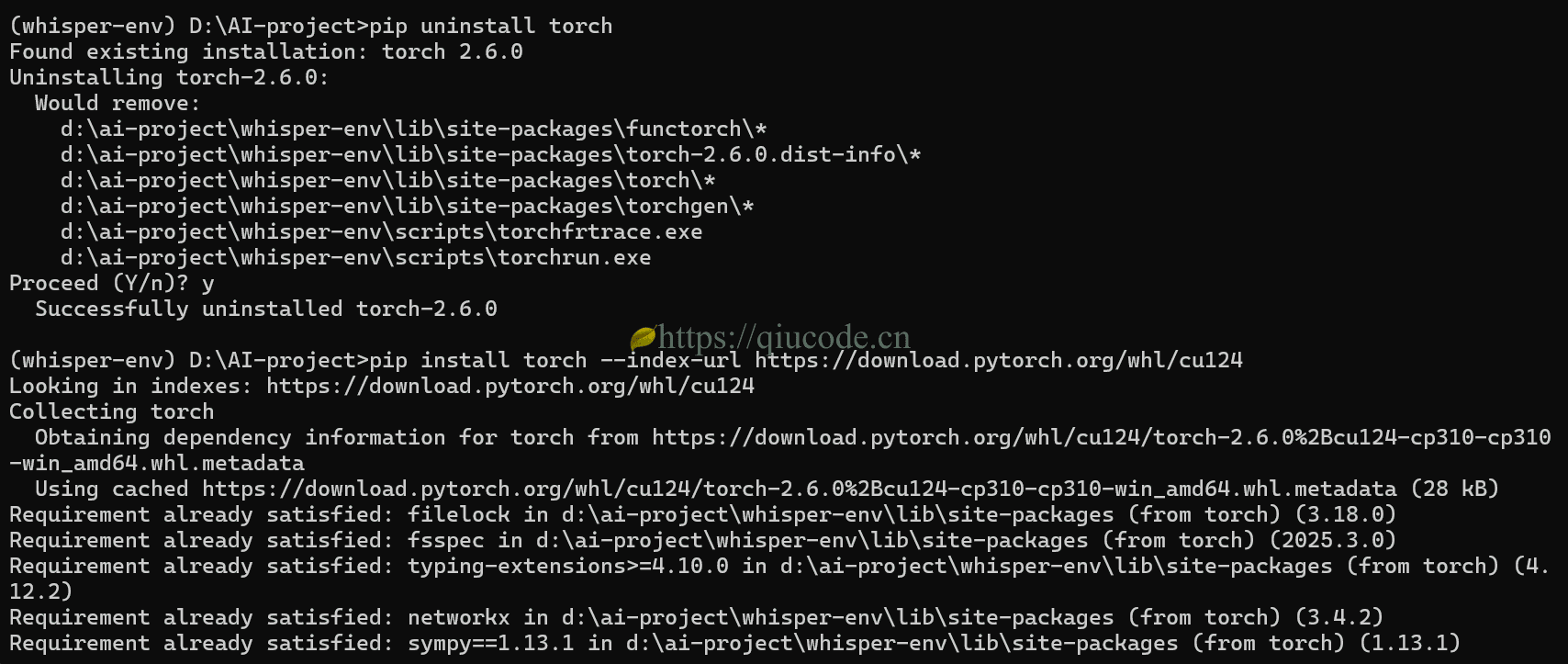
虽然,whisper是可以通过CPU来推理的,但是在电脑设备具有GPU的情况,还是选择torch的CUDA版本。
pip uninstall torch
pip install torch --index-url https://download.pytorch.org/whl/cu124
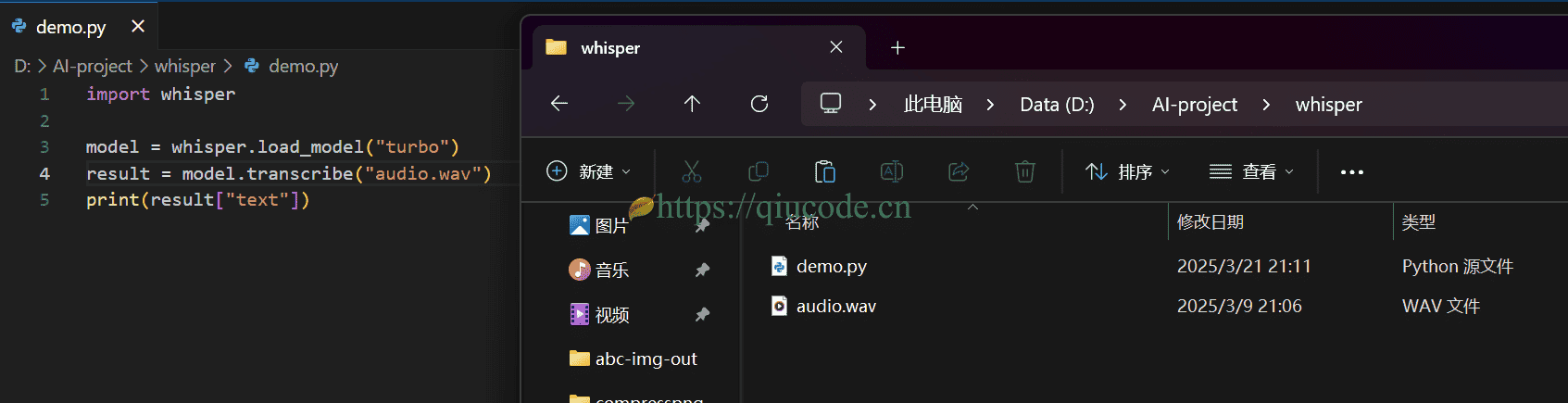
之后,新建一个demo.py文件,写入以下脚本。
import whisper
model = whisper.load_model("turbo")
result = model.transcribe("audio.wav")
print(result["text"])
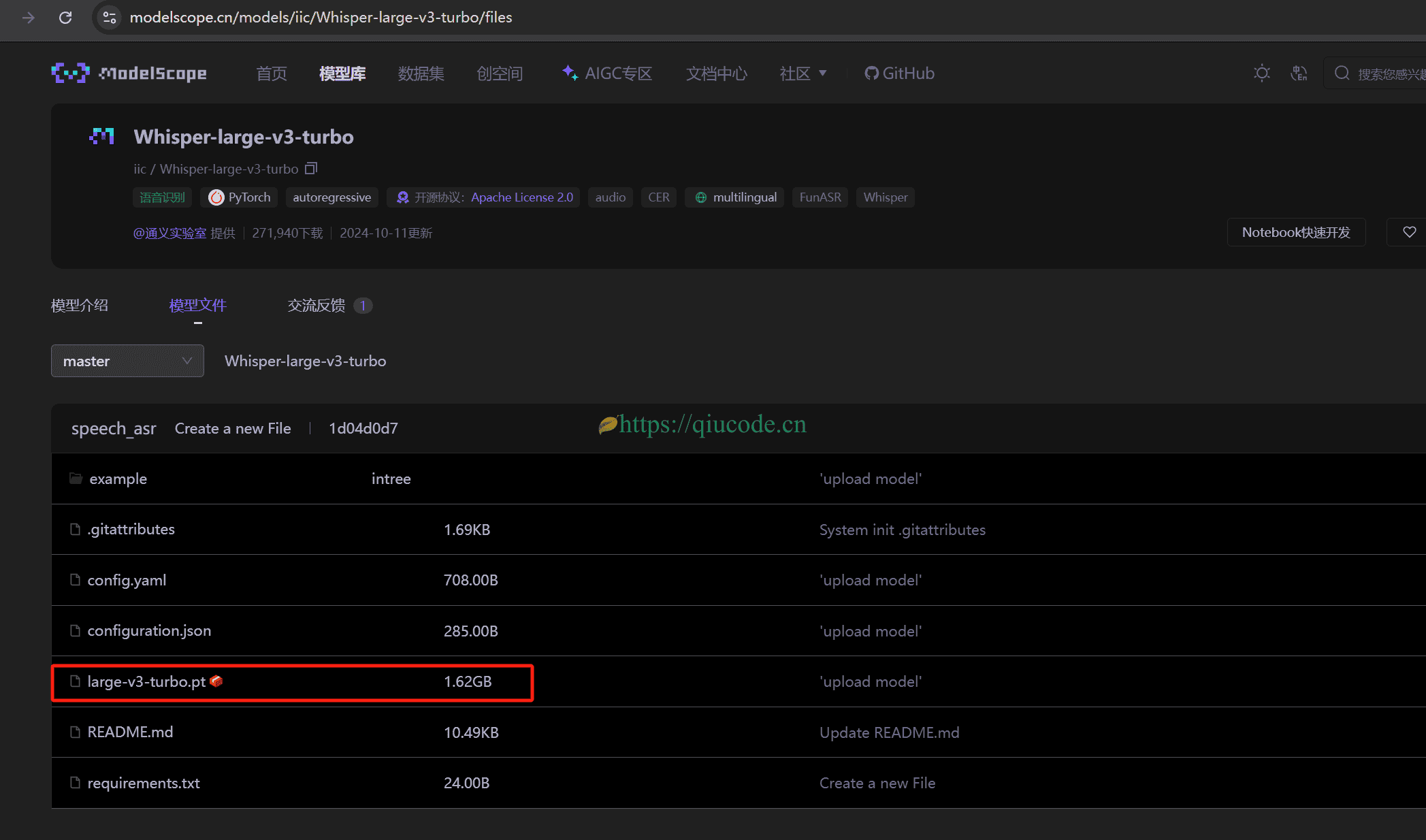
首次运行,会去下载模型,而我使用的是turbo,所以自动下载的便是large-v3-turbo。

如果自动下载失败了,那么就手动下载吧。
模型默认加载路径:C:\Users\你电脑的用户名\.cache\whisper
https://www.modelscope.cn/models/iic/Whisper-large-v3-turbo/files
 2025-03-19 22:06:43 +0800 +0800
2025-03-19 22:06:43 +0800 +0800 2025-03-15 22:06:43 +0800 +0800
2025-03-15 22:06:43 +0800 +0800 2025-03-13 20:26:43 +0800 +0800
2025-03-13 20:26:43 +0800 +0800 2025-03-10 21:26:43 +0800 +0800
2025-03-10 21:26:43 +0800 +0800 2025-03-07 21:26:43 +0800 +0800
2025-03-07 21:26:43 +0800 +0800