
阿里千问团队开源了到端全模态大模型Qwen-2.5-Omini-7B,一时之间,炸燃了AI界。
而这次千问团队开源的Qwen-2.5-Omini-7B,可谓是将看、听、读及写集于一身的全能型的大模型。
- Thinker-Talker双核架构
- Thinker模块:统一处理文本、图像、音频、视频输入,通过多模态编码器提取特征并生成语义理解结果。
- Talker模块:基于双轨Transformer解码器,实时生成文本与自然语音响应,支持4种拟人化音色切换。
- 创新技术:
- TMRoPE时间对齐算法:实现音视频输入的毫秒级同步对齐,视频推理准确率提升3.1%。
- FlashAttention-2加速:降低显存占用并提升推理速度,支持8K分辨率图像输入。
- 全模态统一处理能力
- 支持文本、图像、音频、视频的端到端输入与输出,无需分模块处理。
- 实测性能:
- OmniBench基准测试:综合得分56.13%,超越Gemini 1.5-Pro(42.91%)。
- 语音合成自然度:Seed-tts-eval评分0.88,接近人类水平。
本地部署
虽然官方给出了最小GPU内存需求,但如果我们不是去分析(Analysis)视频的话,还是在8G显存下把玩的,当然咯,也是可以使用量化版本。
| 精度 | 15(s) 音频 | 30(s) 音频 | 60(s) 音频 |
|---|---|---|---|
| FP32 | 93.56 GB | 不推荐 | 不推荐 |
| BF16 | 31.11 GB | 41.85 GB | 60.19 GB |
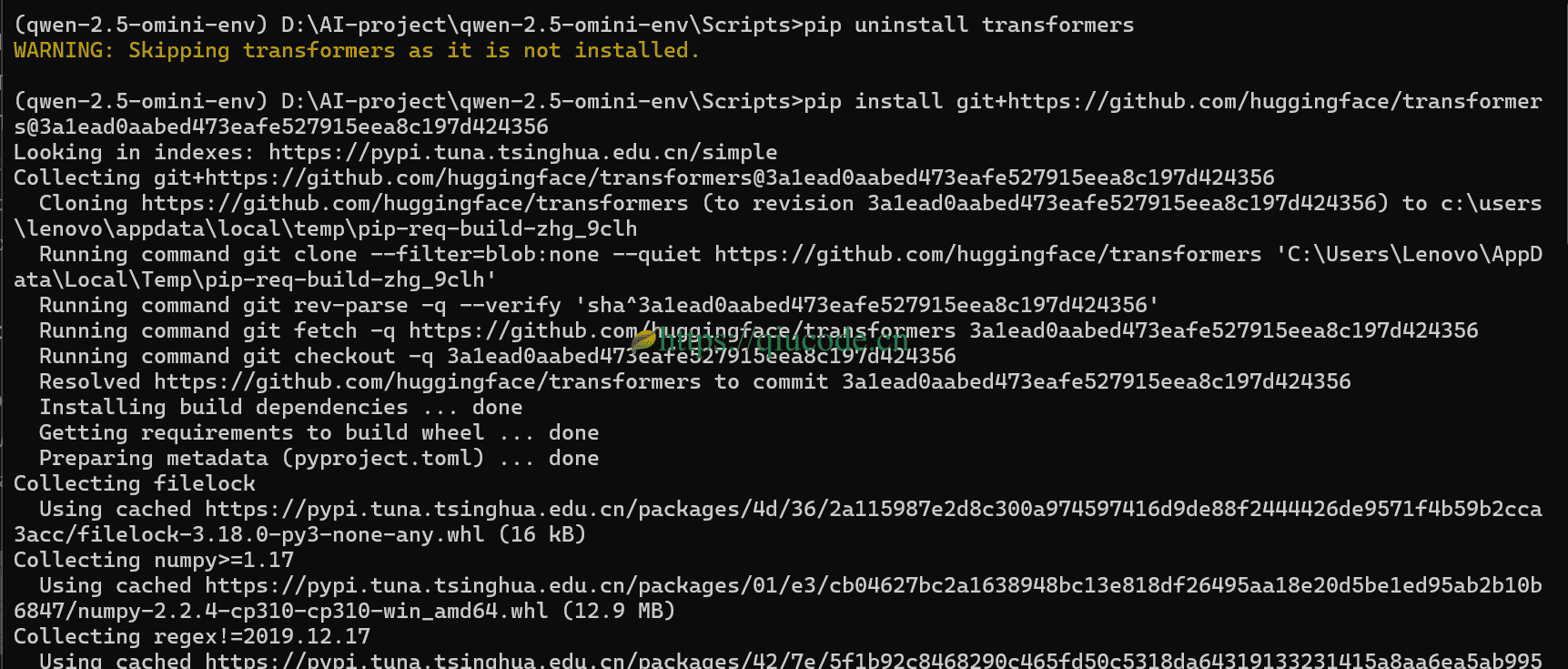
pip uninstall transformers
pip install git+https://github.com/huggingface/transformers@3a1ead0aabed473eafe527915eea8c197d424356
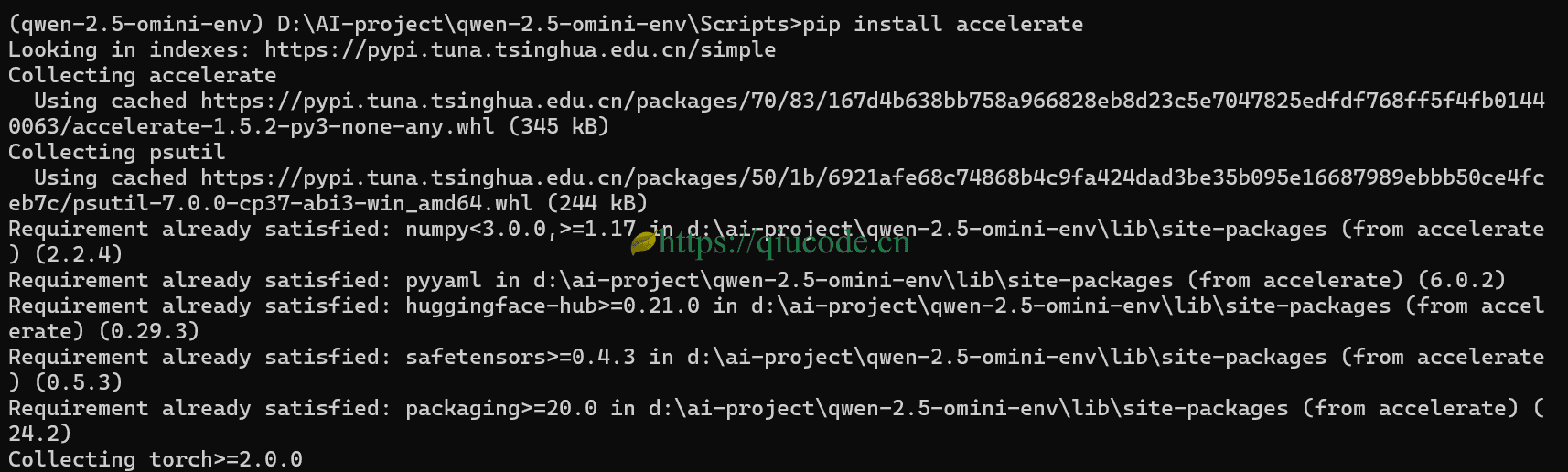
pip install accelerate
你得先创建python虚拟环境,可以使用anaconda或miniconda。而我始终使用的是python3自带的venv模块来构建python虚拟环境。
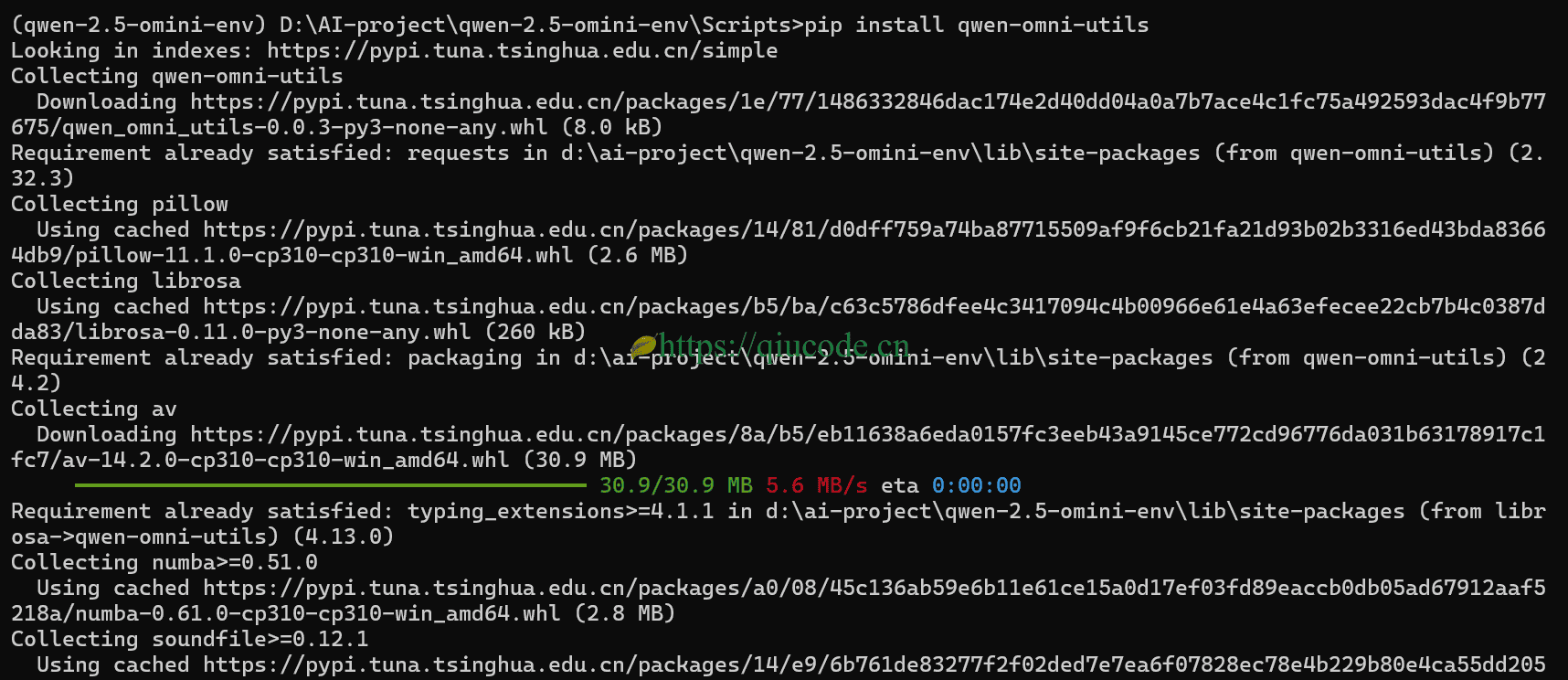
安装qwen-omni-utils这个工具类库。
pip install qwen-omni-utils
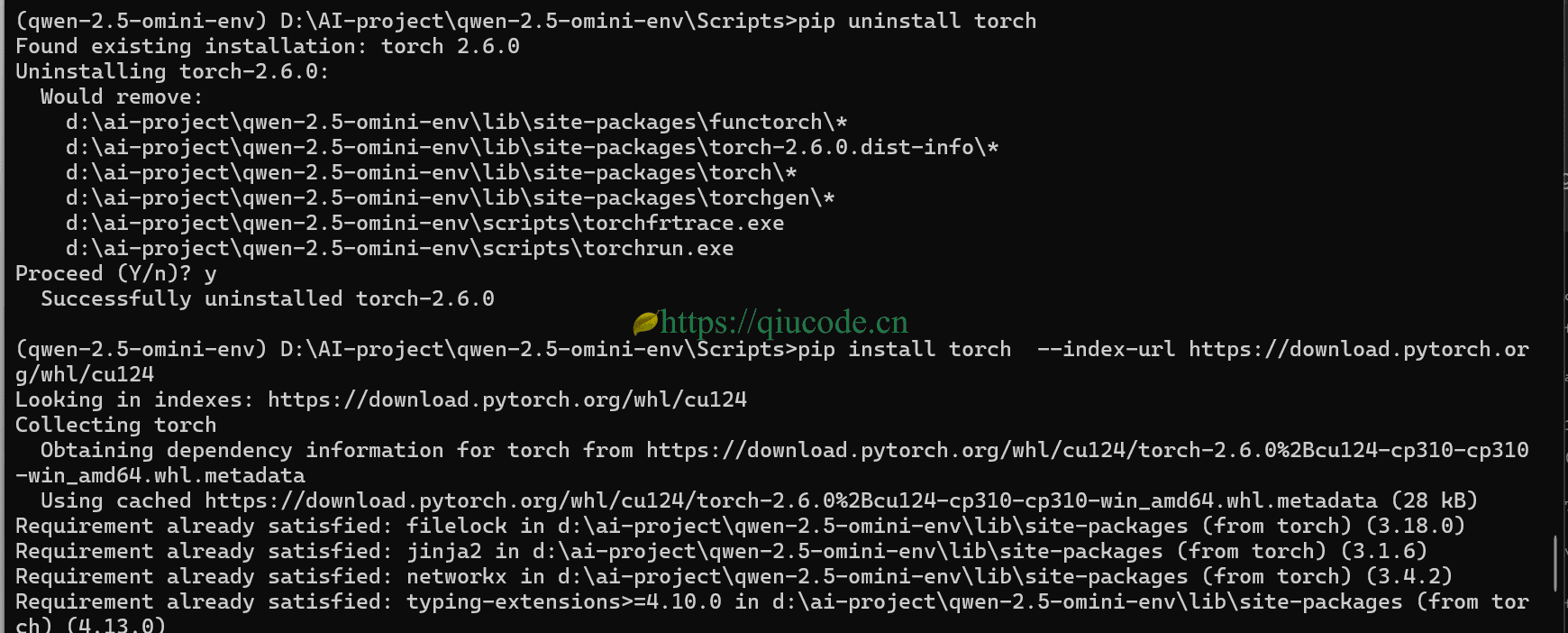
由于这个依赖默认安装的是CPU版的torch,所以,我们得先卸载它,而后安装CUDA版本的torch。
pip uninstall torch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
我们身处国内,使用modelscope来下载模型,故而,需安装它。
pip install modelscope
推理模型
我们新建一个python文件,输入以下脚本,以实现语音识别的功能。
from qwen_omni_utils import process_mm_info
import torch
#from transformers import Qwen2_5OmniModel, Qwen2_5OmniProcessor
from modelscope import Qwen2_5OmniModel, Qwen2_5OmniProcessor
from qwen_omni_utils import process_mm_info
model_path = "Qwen/Qwen2.5-Omni-7B"
model = Qwen2_5OmniModel.from_pretrained("Qwen/Qwen2.5-Omni-7B", torch_dtype="auto", device_map="auto")
# model = Qwen2_5OmniModel.from_pretrained(
# model_path,
# torch_dtype=torch.bfloat16,
# device_map="auto",
# attn_implementation="flash_attention_2",
# )
processor = Qwen2_5OmniProcessor.from_pretrained(model_path)
# @title inference function
def inference(audio_path, prompt, sys_prompt):
messages = [
{"role": "system", "content": sys_prompt},
{"role": "user", "content": [
{"type": "text", "text": prompt},
{"type": "audio", "audio": audio_path},
]
},
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
print("text:", text)
# image_inputs, video_inputs = process_vision_info([messages])
audios, images, videos = process_mm_info(messages, use_audio_in_video=True)
inputs = processor(text=text, audios=audios, images=images, videos=videos, return_tensors="pt", padding=True)
inputs = inputs.to(model.device).to(model.dtype)
output = model.generate(**inputs, use_audio_in_video=True, return_audio=False)
text = processor.batch_decode(output, skip_special_tokens=True, clean_up_tokenization_spaces=False)
return text
audio_path = "D:\\AI-project\\whisper\\audio.wav"
prompt = "Transcribe the Chinese audio into text without any punctuation marks."
## Use a local HuggingFace model to inference.
response = inference(audio_path, prompt=prompt, sys_prompt="You are a speech recognition model.")
print(response[0])
首次运行文件,会去modelscope下载模型,下载速度取决于你的宽带,这里你可以起来喝杯茶,顺便去阳台,点上你那想戒掉又戒不掉烟瘾的低价烟。
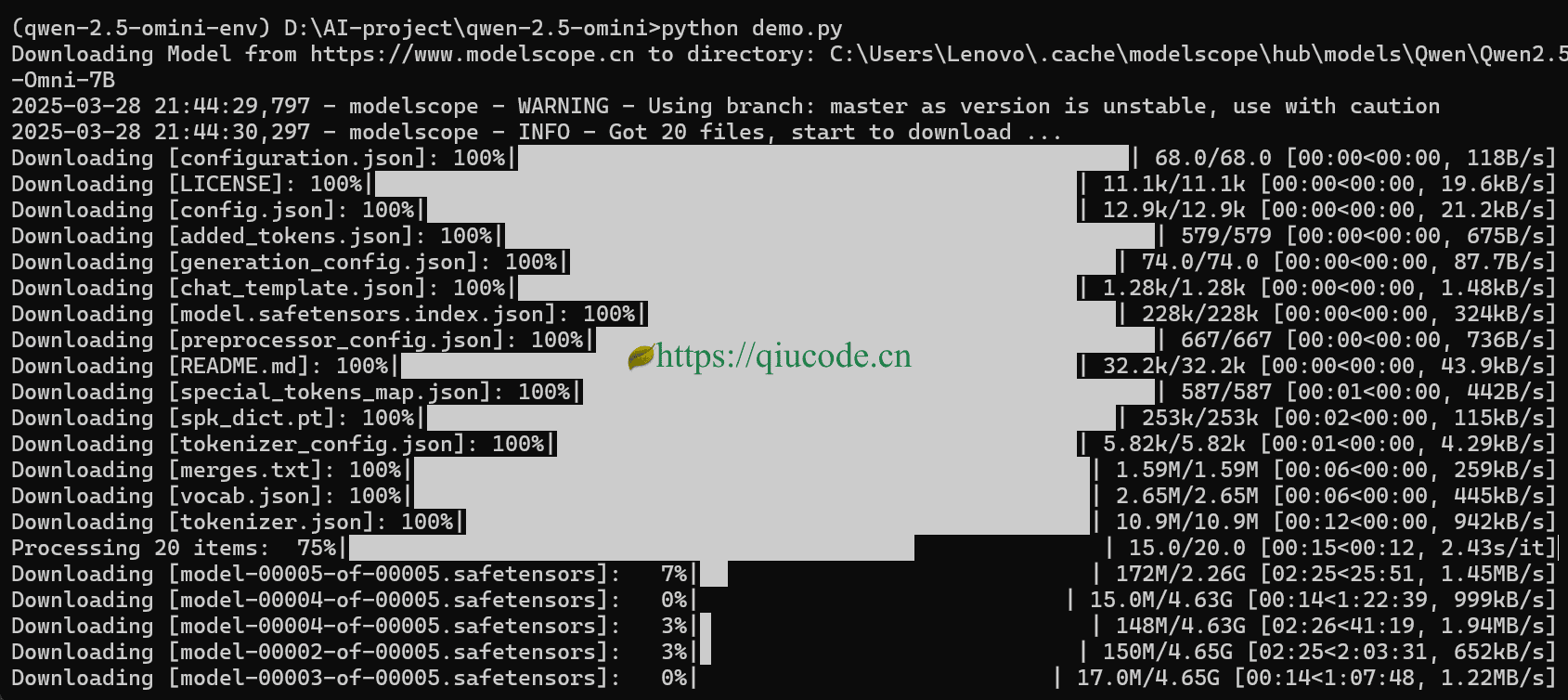
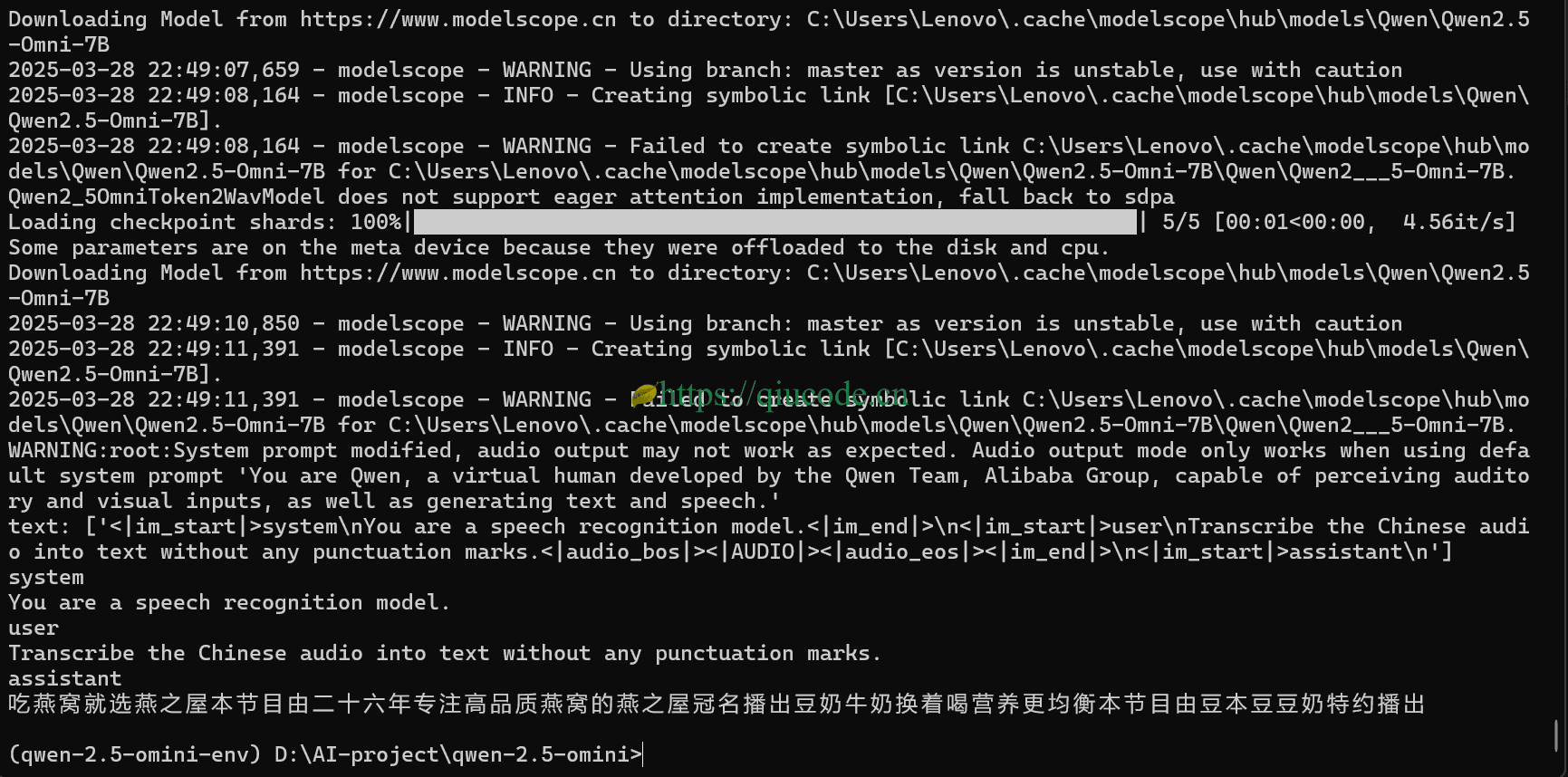
当你从阳台回来的时候,或者说你的茶喝完了,再看Terminal,它已经把音频给识别出来了。
 2025-03-25 22:02:43 +0800 +0800
2025-03-25 22:02:43 +0800 +0800 2025-03-19 22:06:43 +0800 +0800
2025-03-19 22:06:43 +0800 +0800 2025-03-15 22:06:43 +0800 +0800
2025-03-15 22:06:43 +0800 +0800 2025-03-13 20:26:43 +0800 +0800
2025-03-13 20:26:43 +0800 +0800 2025-03-10 21:26:43 +0800 +0800
2025-03-10 21:26:43 +0800 +0800