
一、核心定位与技术亮点
竞赛级代码推理能力
OlympicCoder-7B针对编程竞赛(如国际信息学奥林匹克竞赛IOI)需求设计,通过 CodeForces-CoTs 数据集(包含 10 万高质量思维链样本)进行训练,覆盖C++和Python语言的算法实现。该模型在IOI挑战赛中表现出色,生成代码的通过率和效率显著优于同规模模型 。真实竞赛场景优化 模型模拟了竞赛中的提交策略优化机制,例如在严格的时限内生成代码并通过测试用例验证,确保生成结果的正确性和效率。其训练数据整合了
CodeForces、DeepMindCodeContests等竞赛平台的问题及官方解题思路,强化了算法逻辑的精准性 。轻量化与高效部署 作为
7B参数量的模型,OlympicCoder-7B在保证性能的同时降低了硬件门槛,可在消费级 GPU 上运行,适合开发者和教育机构本地化部署。量化版本(如 Q4_K_M)内存占用仅约 5GB,生成速度可达 45 tokens/s 。
二、性能对比与实测表现
算法竞赛任务 在 CodeForces 和 IOI 题型测试中,OlympicCoder-7B 的代码生成准确率接近 32B 版本(如 OlympicCoder-32B),且在贪吃蛇游戏等复杂编程任务中生成代码的可执行性显著优于同规模模型 。
跨模型对比 与同属代码生成领域的 aiXcoder-7B(北大开源)相比,OlympicCoder-7B 在竞赛题目上的表现更优,但 aiXcoder 在长上下文补全(支持 32k 上下文)和企业级开发场景中更具优势 。而与 Magicoder-7B(UIUC/清华联合开发)相比,OlympicCoder 更专注于算法优化而非通用代码生成 。
三、应用场景与局限性
- 适用场景
- 算法竞赛训练:为选手提供代码思路和解题参考。
- 编程教育工具:辅助学生理解复杂算法实现逻辑。
- 自动化评测系统:生成测试用例或验证代码正确性。
- 局限性
- 领域专注性:在通用软件开发场景(如 Web 开发)中表现不及专用模型。
- 数据时效性:需定期更新竞赛题库以保持模型对最新题型的适应能力。
四、本地部署
首先,我们使用python3自带的venv模块来搭建python 虚拟环境。当然,你也可以使用anaconda或者miniconda来构建python 虚拟环境。
python -m venv OlympicCoder-env
cd OlympicCoder/Scripts
activate

安装CUDA版本的torch依赖库。
pip install torch --index-url https://download.pytorch.org/whl/cu124

随后,我们安装huggingface开源的transformers。
pip install git+https://github.com/huggingface/transformers

再者,安装依旧来自huggingface开源的用于加速推理的accelerate依赖库。
pip install git+https://github.com/huggingface/accelerate
接着,安装huggingface_hub是用于下载模型的。
pip install huggingface_hub
至于notebook这个依赖库是可选的。
pip install notebook
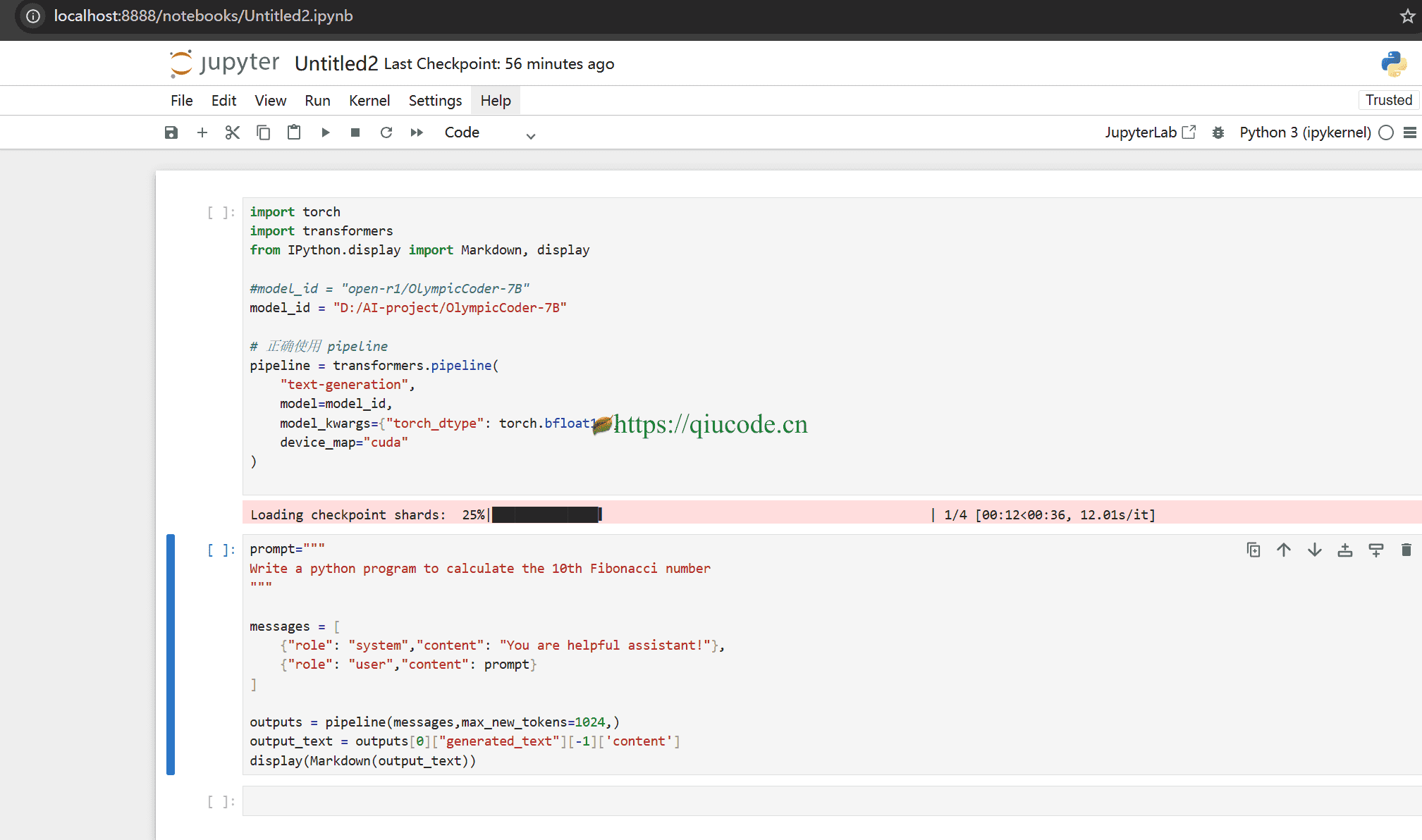
使用以下命令,为我们在浏览器中打开一个标签页,供我们编写ipynb文件。
jupyter notebook
import torch
import transformers
from IPython.display import Markdown, display
model_id = "open-r1/OlympicCoder-7B"
# 正确使用 pipeline
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto"
)
prompt="""
Write a python program to calculate the 10th Fibonacci number
"""
messages = [
{"role": "system","content": "You are helpful assistant!"},
{"role": "user","content": prompt}
]
outputs = pipeline(messages,max_new_tokens=1024,)
output_text = outputs[0]["generated_text"][-1]['content']
display(Markdown(output_text))
 2025-03-28 22:02:43 +0800 +0800
2025-03-28 22:02:43 +0800 +0800 2025-03-25 22:02:43 +0800 +0800
2025-03-25 22:02:43 +0800 +0800 2025-03-19 22:06:43 +0800 +0800
2025-03-19 22:06:43 +0800 +0800 2025-03-15 22:06:43 +0800 +0800
2025-03-15 22:06:43 +0800 +0800 2025-03-13 20:26:43 +0800 +0800
2025-03-13 20:26:43 +0800 +0800