
引言
曾几何时,当 Stable Diffusion 文生图开源后,输入一段文本便能生成图片,而惊艳之时。能否在图片写入中文,而不再是乱码,苦求各种解决方案,而不得其一二,多半还是那么强差人意。
然而,阿里巴巴千问团队震撼开源的 Qwen-Image ,这款模型不仅精准渲染中文文本,还能智能编辑图像,堪称AI绘画界的"全能选手"!
那么,接下来,就和我一起在 Windows下基于最新版的 ComfyUI ,来部署 Qwen-Image 工作流。
安装 ComfyUI 或更新它
若你还没安装过 ComfyUI,那么你可以先进入 ComfyUI 官网,下载它。
ComfyUI 官网地址:https://www.comfy.org/zh-cn/

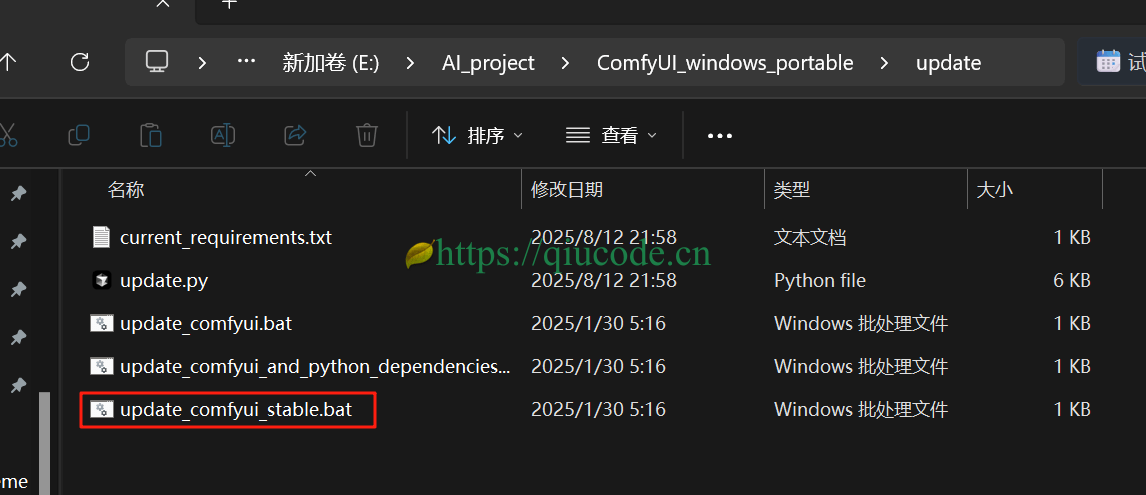
假使你跟我一样,之前在电脑下载过 ComfyUI,那么,只需双击 ComfyUI根路径下的 update 文件夹里的 update_comfyui_stable.bat 即可完成更新。
下载模型
目前,千问团队开放了 40B 和 20B量化版本这两种参数的模型。这里选用了 20B 量化模型。
https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/tree/main/non_official/diffusion_models
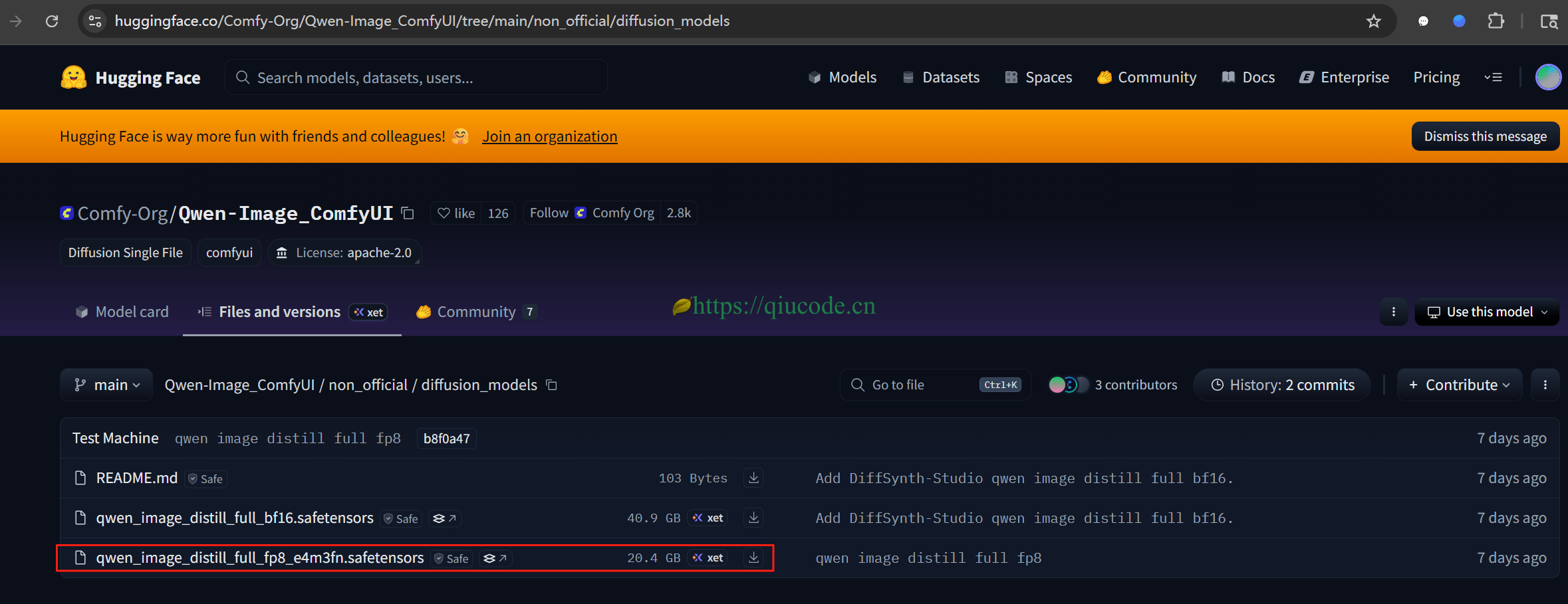
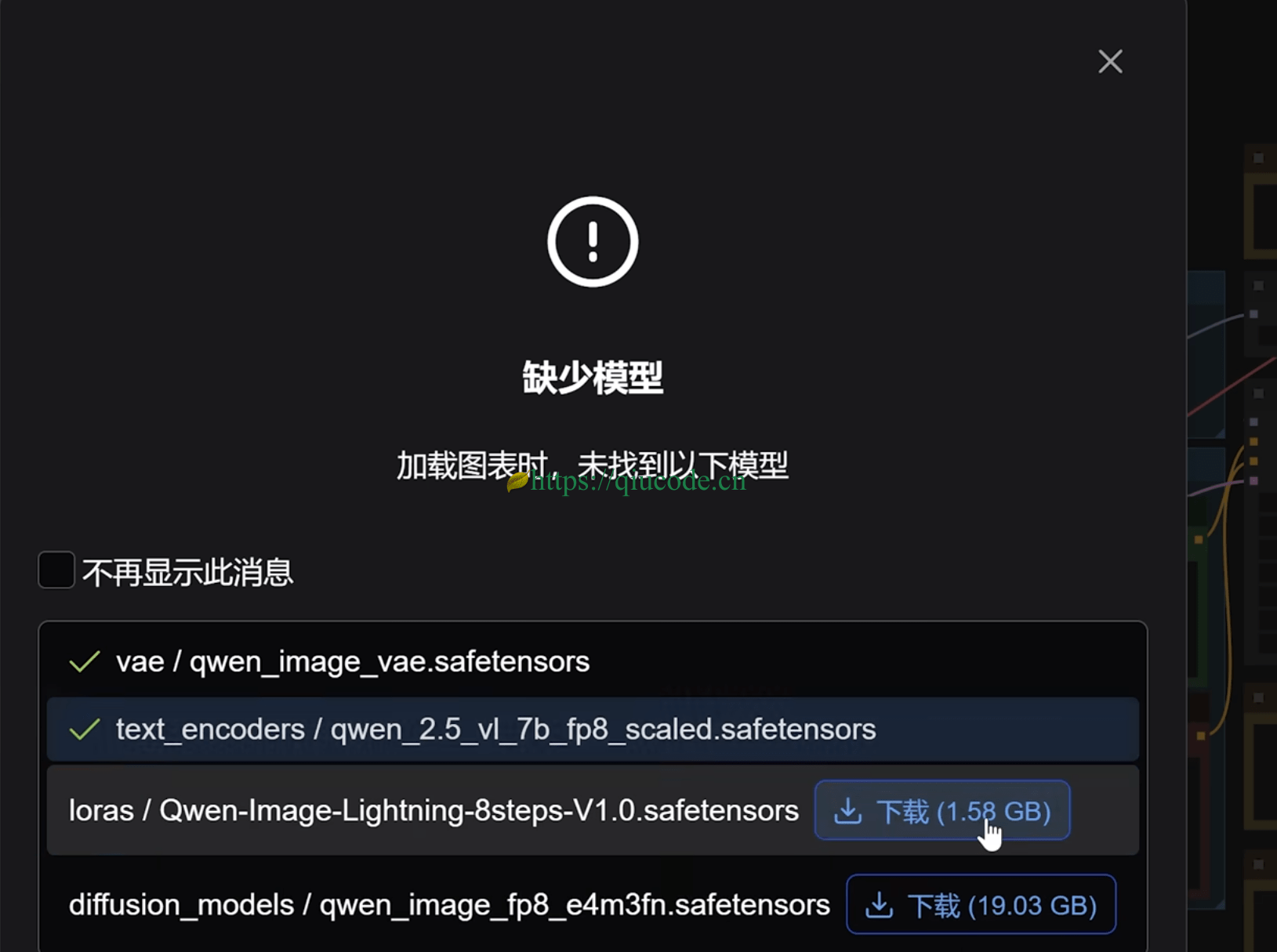
下载好这个量化模型,还需下载编码器和 VAE。
https://comfyanonymous.github.io/ComfyUI_examples/qwen_image/
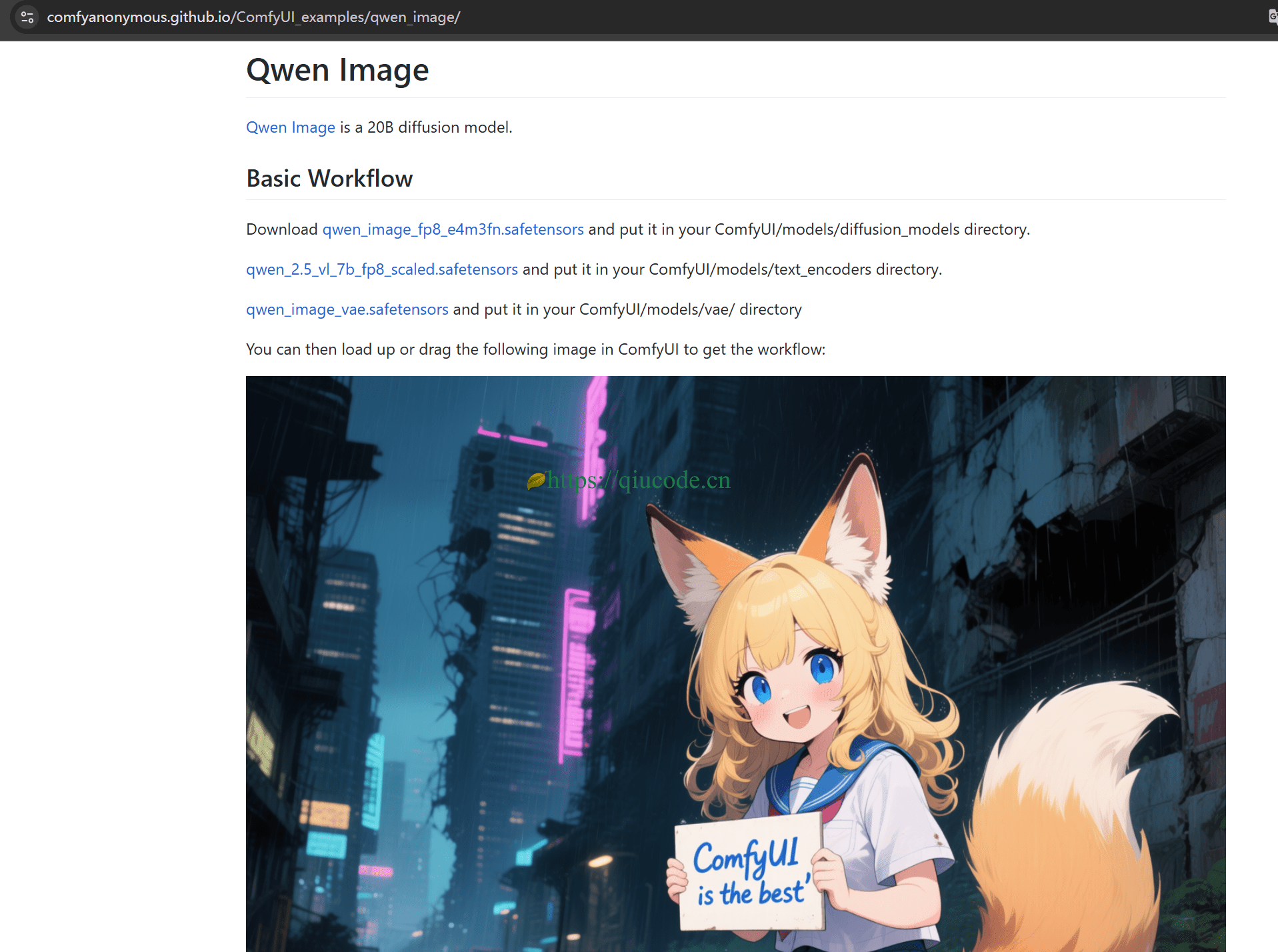
下载好了这些模型,移动到对应的文件夹。
启动 ComfyUI 加载工作流,使用示例提示词生成图片
在 ComfyUI根目录下,双击 run_nvidia_gpu.bat ,随后便会弹出一个黑窗口( Terminal),稍待几秒后,它会自动打开你电脑默认浏览器,在一个新页签下展示 ComfyUI 的界面。
之后,将 https://comfyanonymous.github.io/ComfyUI_examples/qwen_image/ 中的图片拖入到这个页面里,即可展现在你面前的便是 Qwen-Image 工作流了。
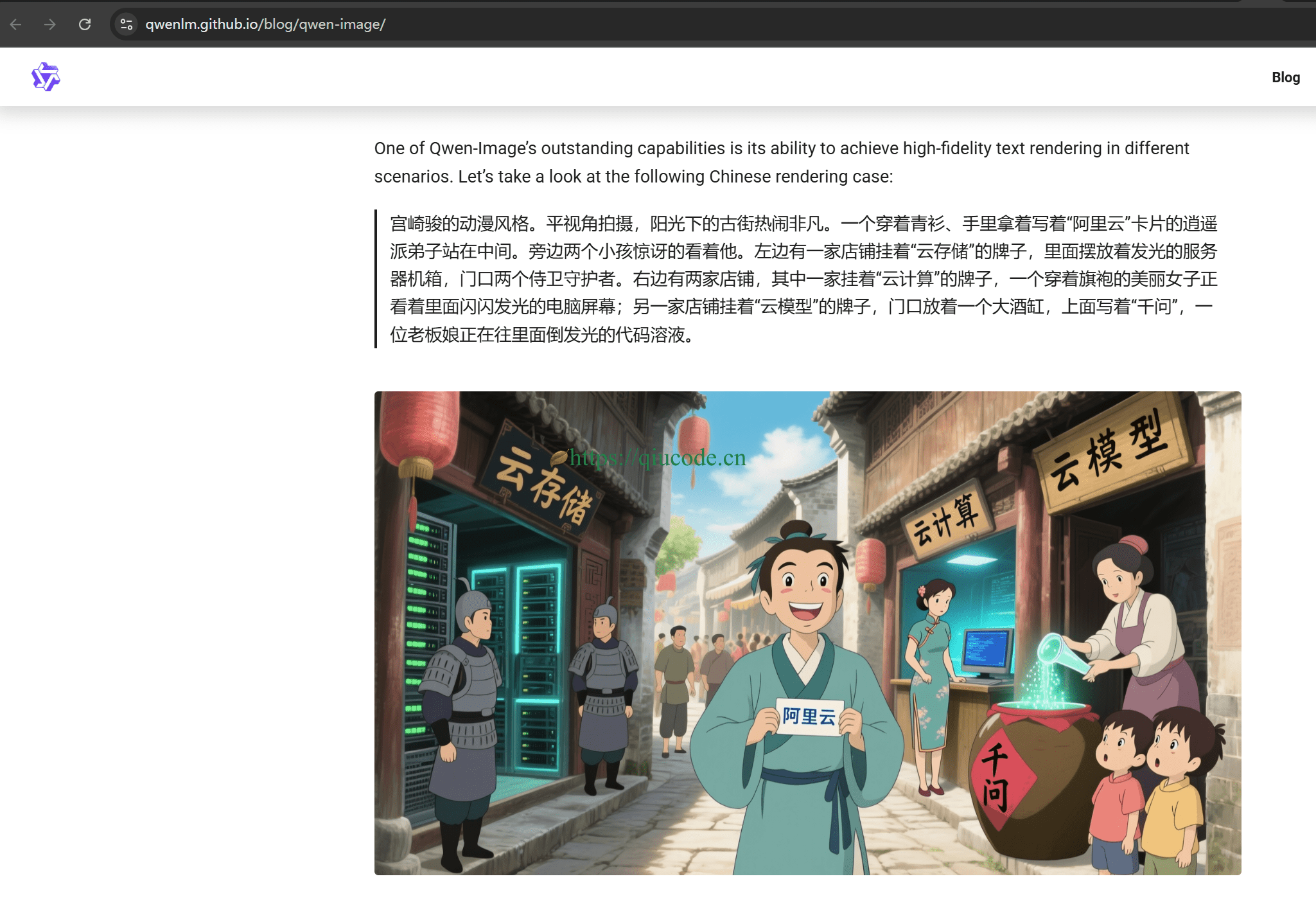
写入 Qwen-Image 官方提示词。
宫崎骏的动漫风格。平视角拍摄,阳光下的古街热闹非凡。一个穿着青衫、手里拿着写着“阿里云”卡片的逍遥派弟子站在中间。旁边两个小孩惊讶的看着他。左边有一家店铺挂着“云存储”的牌子,里面摆放着发光的服务器机箱,门口两个侍卫守护者。右边有两家店铺,其中一家挂着“云计算”的牌子,一个穿着旗袍的美丽女子正看着里面闪闪发光的电脑屏幕;另一家店铺挂着“云模型”的牌子,门口放着一个大酒缸,上面写着“千问”,一位老板娘正在往里面倒发光的代码溶液。
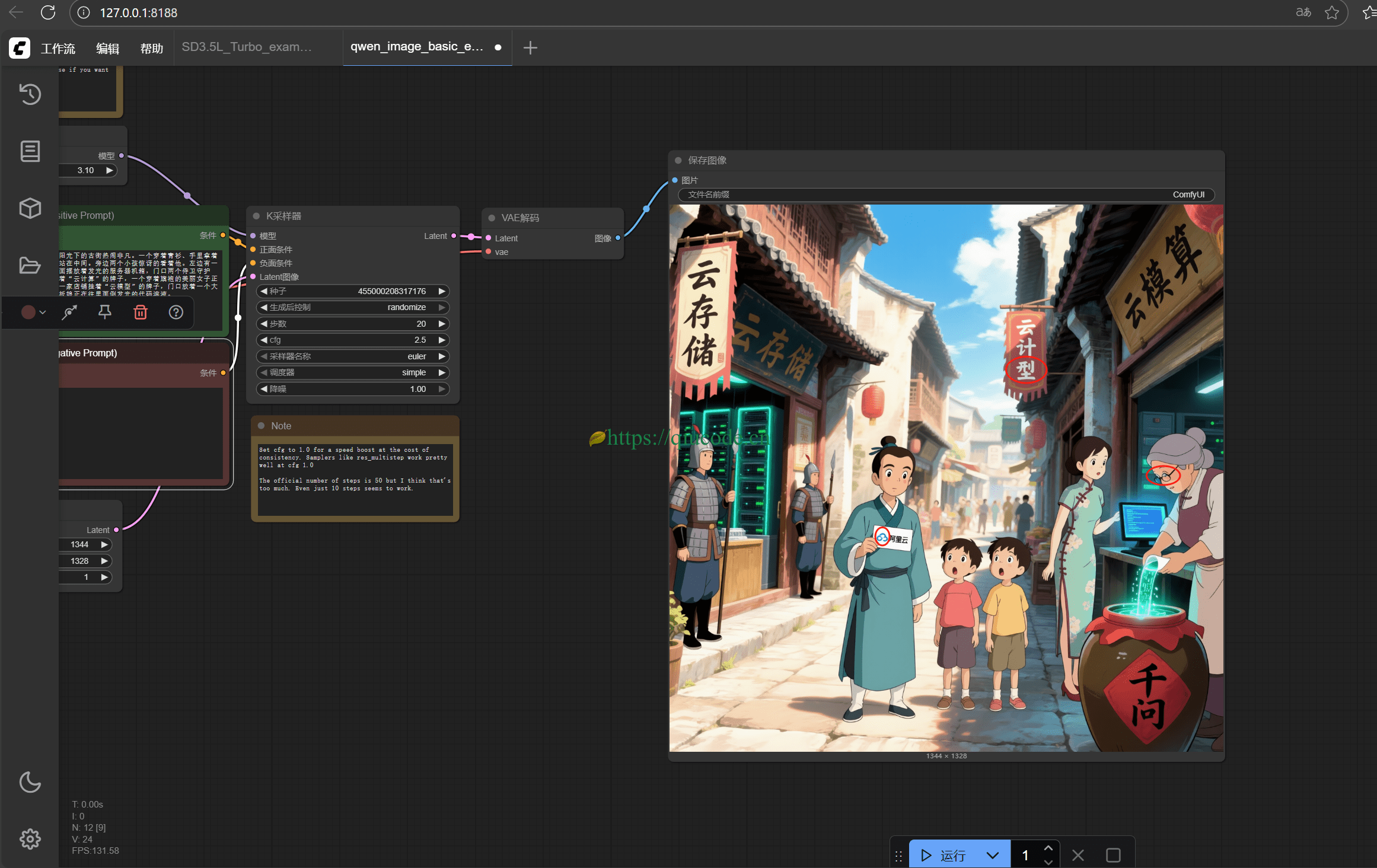
虽然与官方给出的图片有些许出入,但这已经很不错了,至少在中文渲染上面,没有出现所谓的乱码。毕竟这是量化版本。
Qwen-Image官方示例提示词:https://qwenlm.github.io/blog/qwen-image/
Lora 模型加持
若你想要生成 Lora 写实风格的图片,那么只需加载 Lora 模型即可。
首先下载 Comfyui支持 Lora模型的工作流。
直接另存为本地文件,之后再拖入 Comfyui 界面。
由于上面刚刚下载过模型,所以这里只需下载 Lora 模型即可。
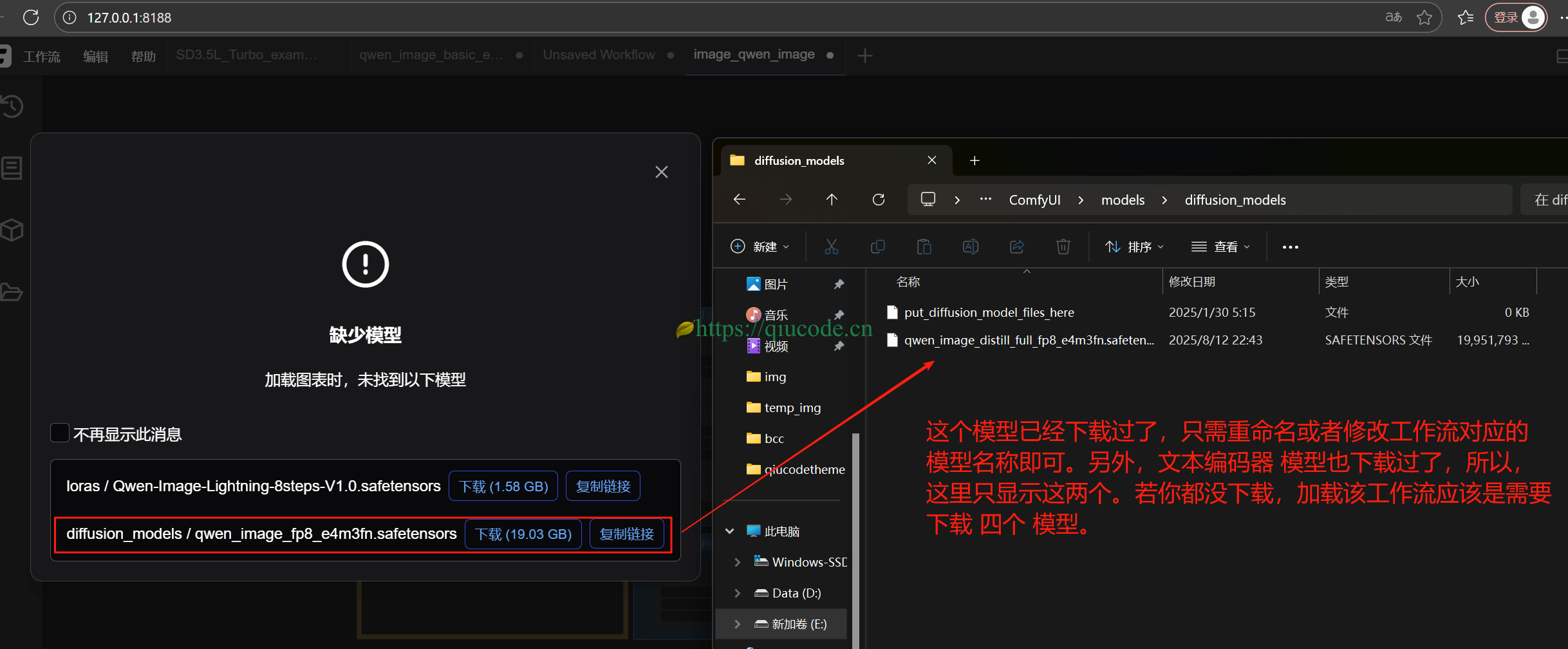
若你是跳过上面,而直接来到这里,你是想要 Lora 写实风格的,那么当你拖入工作流时,应当呈现如下图所示。
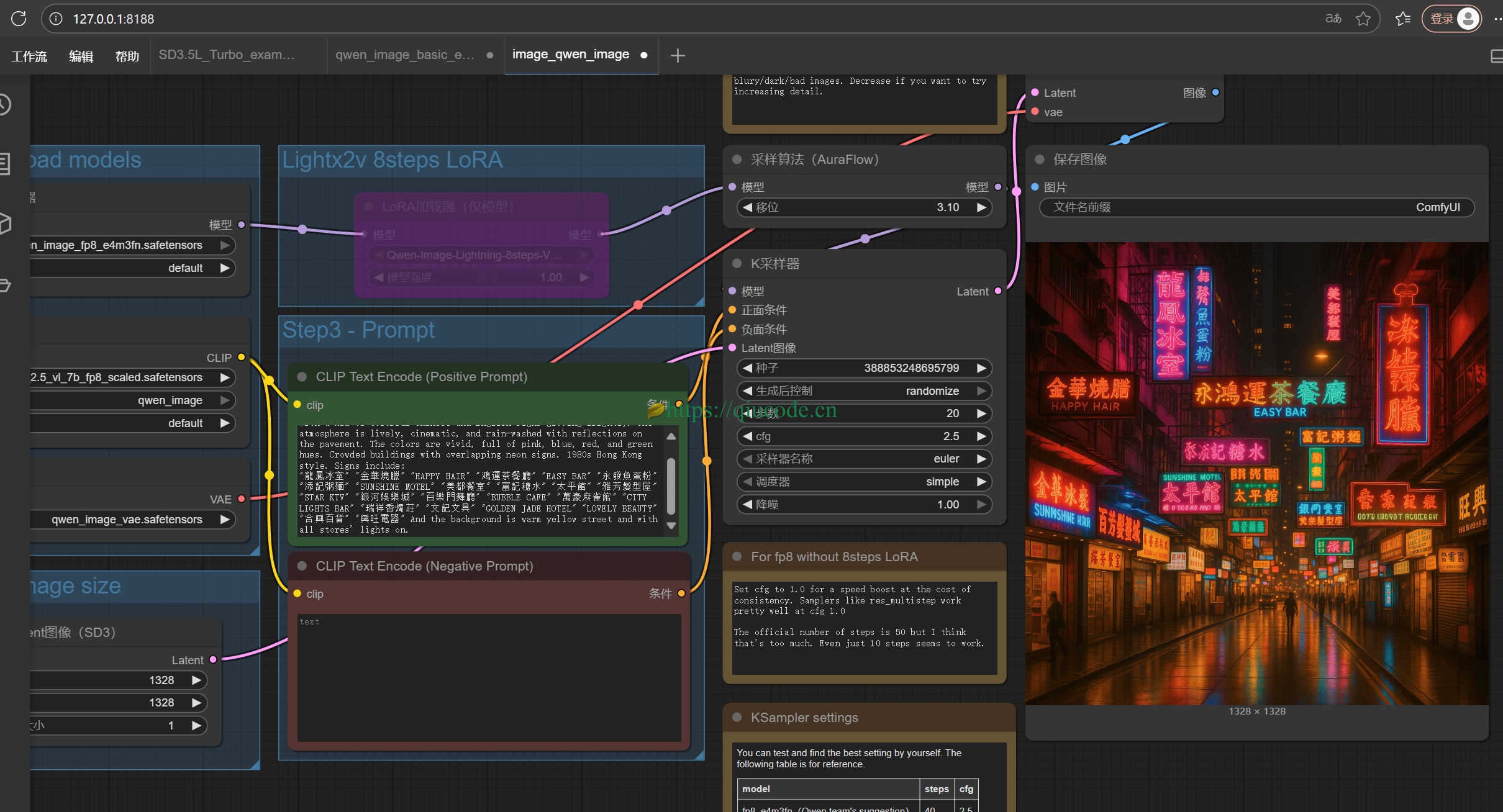
工作流中默认有一个提示词,直接生成它,先看看效果如何再说。
说到 Lora 写实风格模型,总是逃不开老朋友 civitai.com 。
https://civitai.com/models/1111989/majicflus-beauty
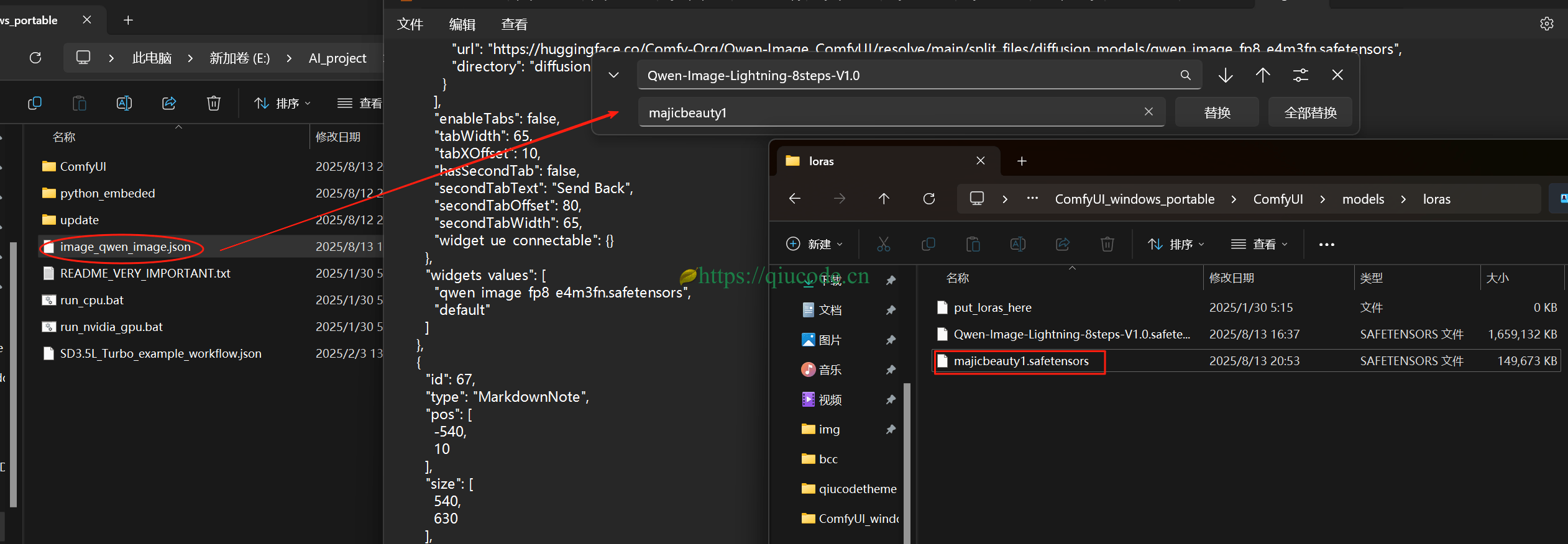
模型下载下来之后,修改工作流,替换模型名称为你下载下来的新模型。当然咯,存放位置也要放对哦!
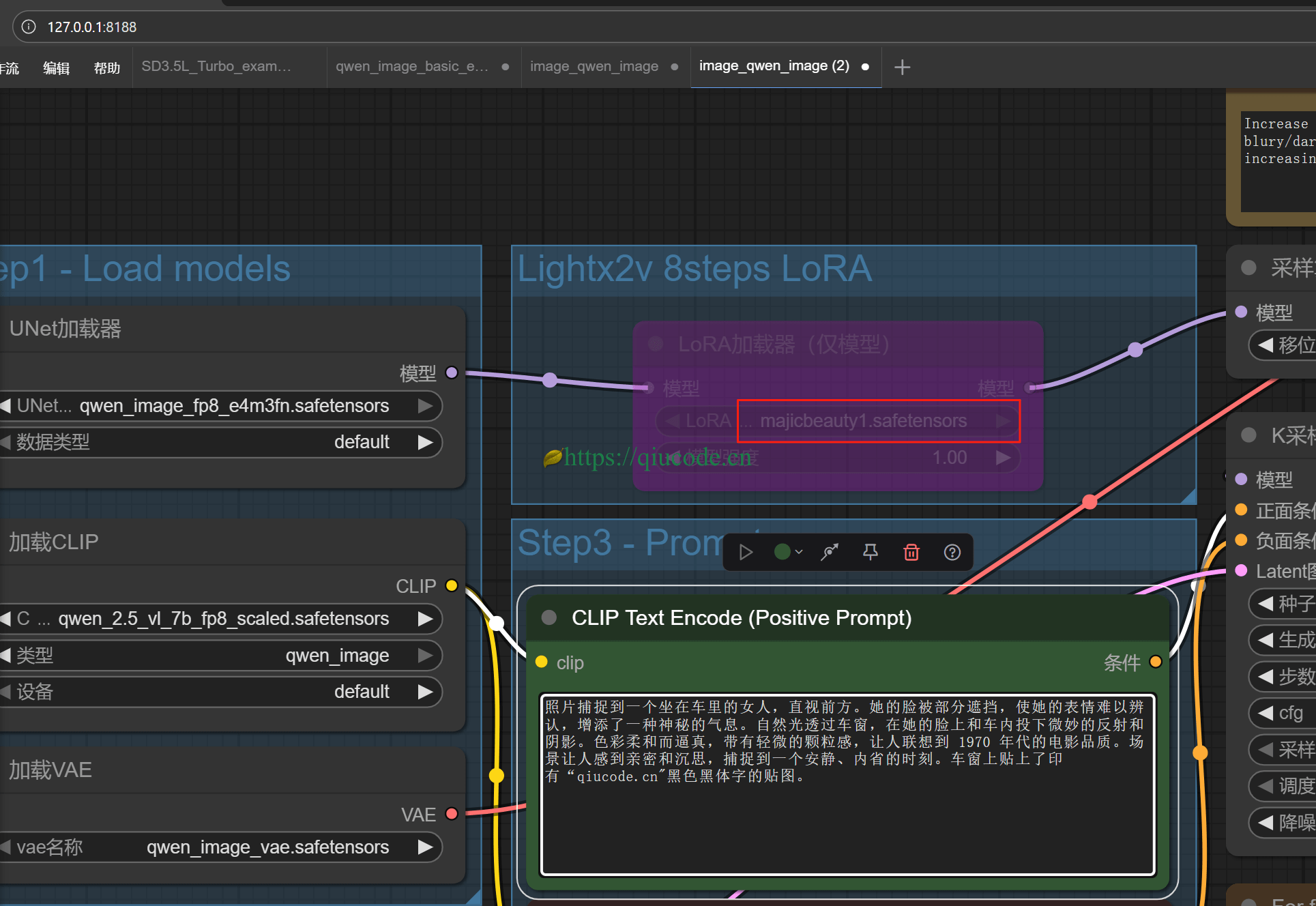
写入提示词:
照片捕捉到一个坐在车里的女人,直视前方。她的脸被部分遮挡,使她的表情难以辨认,增添了一种神秘的气息。自然光透过车窗,在她的脸上和车内投下微妙的反射和阴影。色彩柔和而逼真,带有轻微的颗粒感,让人联想到 1970 年代的电影品质。场景让人感到亲密和沉思,捕捉到一个安静、内省的时刻。车窗上贴上了印有黑色黑体字的贴图,上方字体稍大些写着“qiucode.cn",下面则是字体小些写着“秋码记录”。
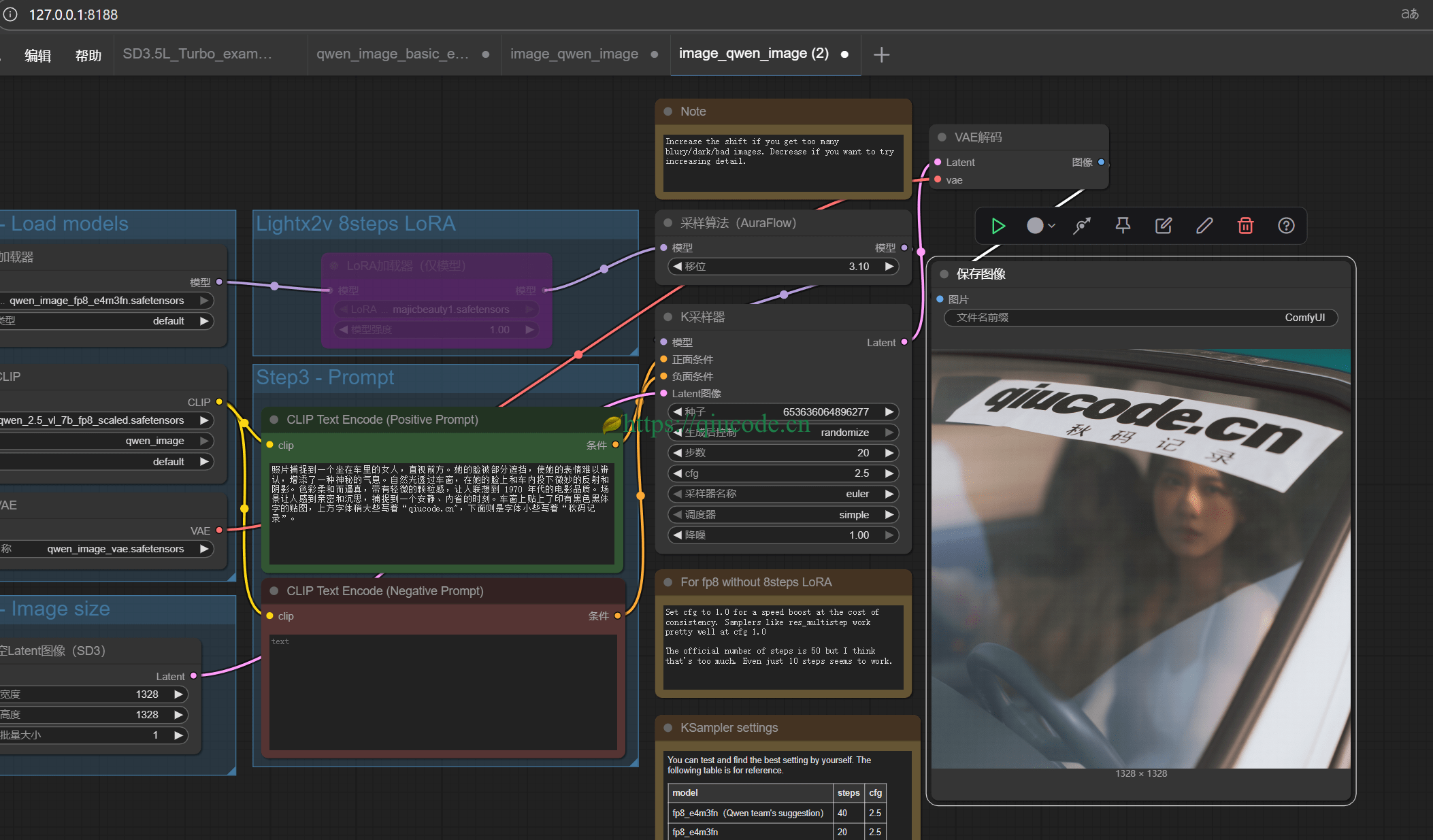
总体效果还是不错的,若想生成的更好,可以把 步数 加大些。以上生成的图片都是在 20步。
 2025-03-07 21:26:43 +0800 +0800
2025-03-07 21:26:43 +0800 +0800 2025-02-16 16:26:43 +0800 +0800
2025-02-16 16:26:43 +0800 +0800 2025-02-03 20:26:43 +0800 +0800
2025-02-03 20:26:43 +0800 +0800 2025-04-18 22:42:43 +0800 +0800
2025-04-18 22:42:43 +0800 +0800 2025-04-10 23:02:43 +0800 +0800
2025-04-10 23:02:43 +0800 +0800