
阿里巴巴 通义千问团队发布并开源了 Qwen-Image-Edit 图像编辑大模型,它是基于 20B 的 Qwen-Image 模型进一步训练,成功将 Qwen-Image 的文本渲染特色能力拓展到编辑任务上,以支持精准的文字编辑。此外,Qwen-Image-Edit 将输入图像同时输入到 Qwen2.5-VL(获取视觉语义控制)和 VAE Encoder(获得视觉外观控制),以同时获得语义/外观双重编辑能力。
- 精准文字编辑:
Qwen-Image-Edit支持中英双语文字编辑,可以在保留文字大小/字体/风格的前提下,直接编辑图片中文字,进行增删改。 - 语义/外观 双重编辑:
Qwen-Image-Edit不仅支持low-level的视觉外观编辑(例如风格迁移,增删改等),也支持high-level的视觉语义编辑(例如 IP 制作,物体旋转等) - 强大的跨基准性能表现: 在多个公开基准测试中的评估表明,
Qwen-Image-Edit在编辑任务中均获得SOTA,是一个强大的图像生成基础模型。
下载模型
对于国内的朋友,可以在国内镜像下载 Qwen-Image-Edit 模型: https://hf-mirror.com/Comfy-Org/Qwen-Image-Edit_ComfyUI/tree/main/split_files/diffusion_models
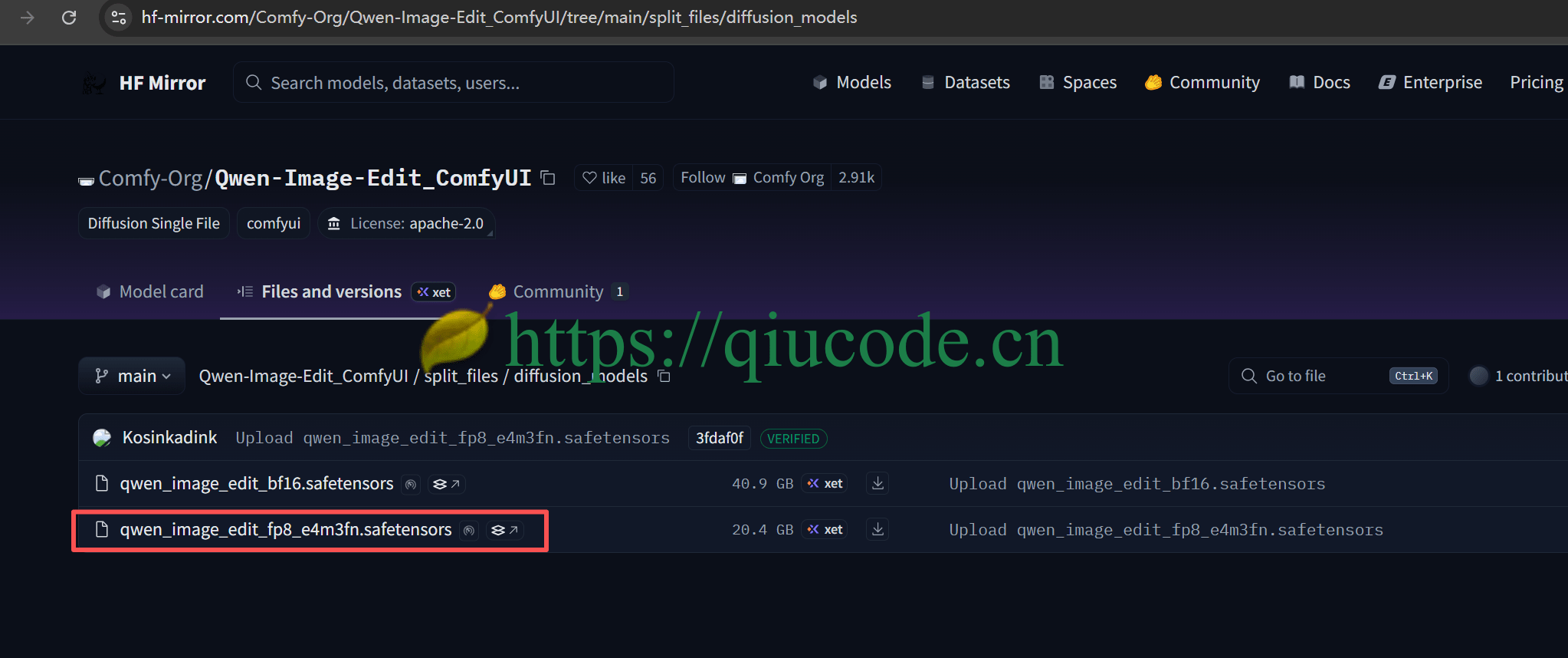
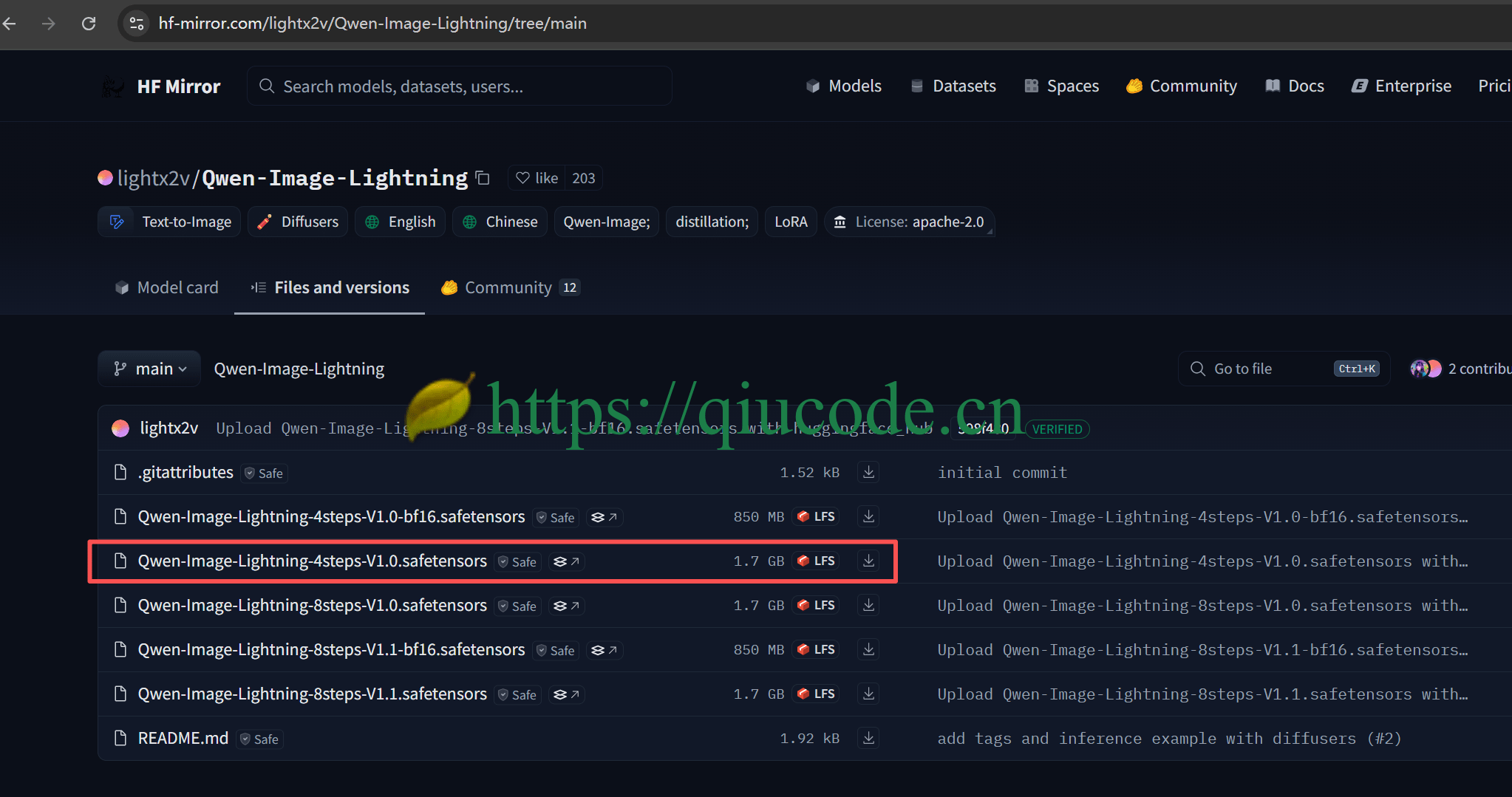
LoRA
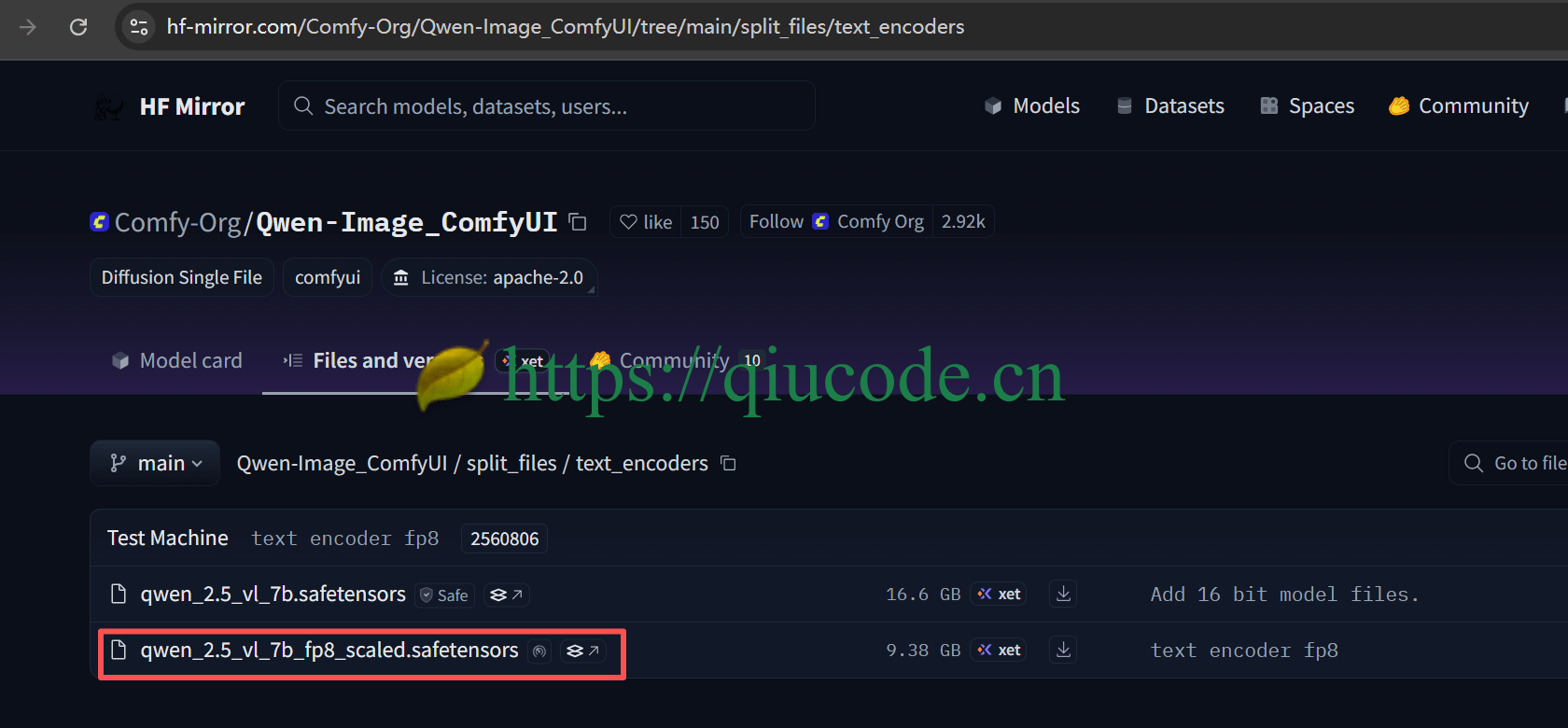
Text encoder
VAE
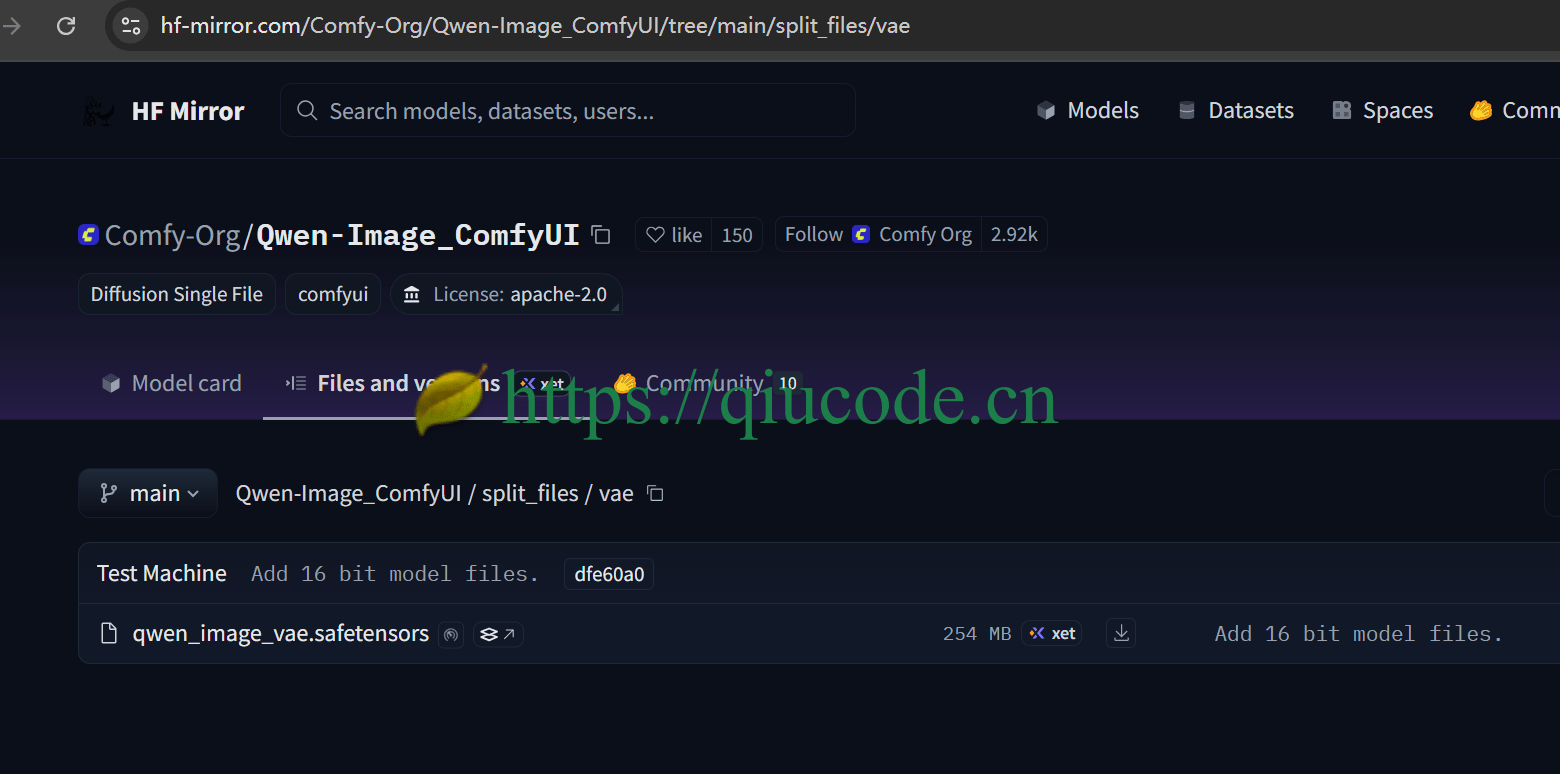
等以上模型都下载完成后,按以下存放路径,拖入到 Comfyui 对应的文件夹内。
📂 ComfyUI/ ├── 📂 models/ │ ├── 📂 diffusion_models/ │ │ └── qwen_image_edit_fp8_e4m3fn.safetensors │ ├── 📂 loras/ │ │ └── Qwen-Image-Lightning-4steps-V1.0.safetensors │ ├── 📂 vae/ │ │ └── qwen_image_vae.safetensors │ └── 📂 text_encoders/ │ └── qwen_2.5_vl_7b_fp8_scaled.safetensors
加载工作流
可以从 Comfyui 文档中获取 Qwen-Image-Edit 工作流。
https://docs.comfy.org/zh-CN/tutorials/image/qwen/qwen-image-edit
将以上的工作流直接拖入 Comfyui 中,或者点击 下载 JSON 格式工作流文件,而后同样的拖入到 Comfyui 界面中。
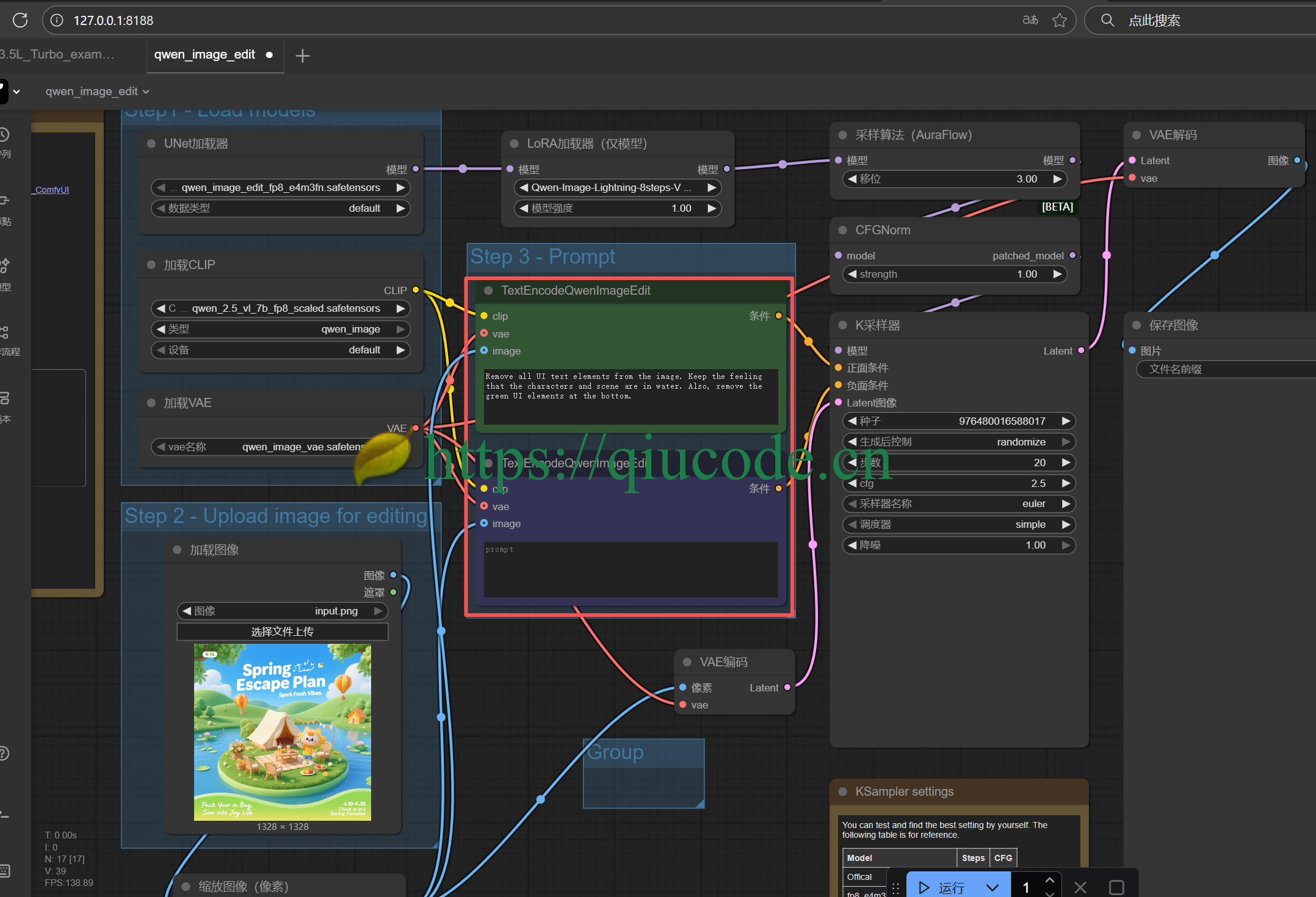
注意:
Comfyui需要更新到最新版本,否则的话,是找不到TextEncodeQwenImageEdit这个节点的!
去除了原图中的文字及按钮,最终结果还是很丝滑啊!
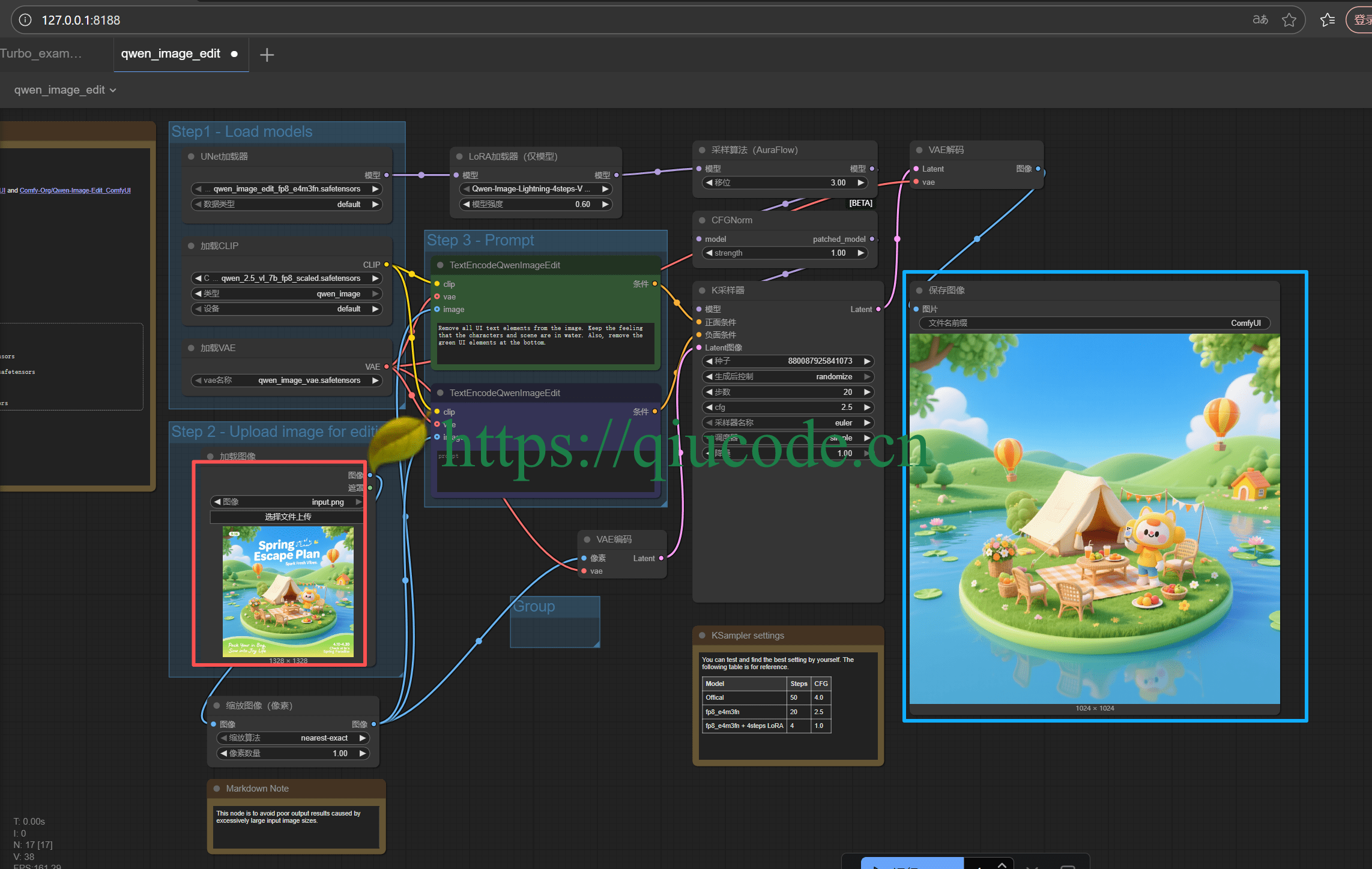
那么,现在该试一下中文提示词是怎么样的效果?
先是上传一张带有 https://qiucode.cn 以及暗绿色的树叶小图标的水印图,目标是去除该 水印。
Prompt(提示词)
移除图中的“https://qiucode.cn" 文字,以及那个树叶的小图标,不要改变原图的整体UI。
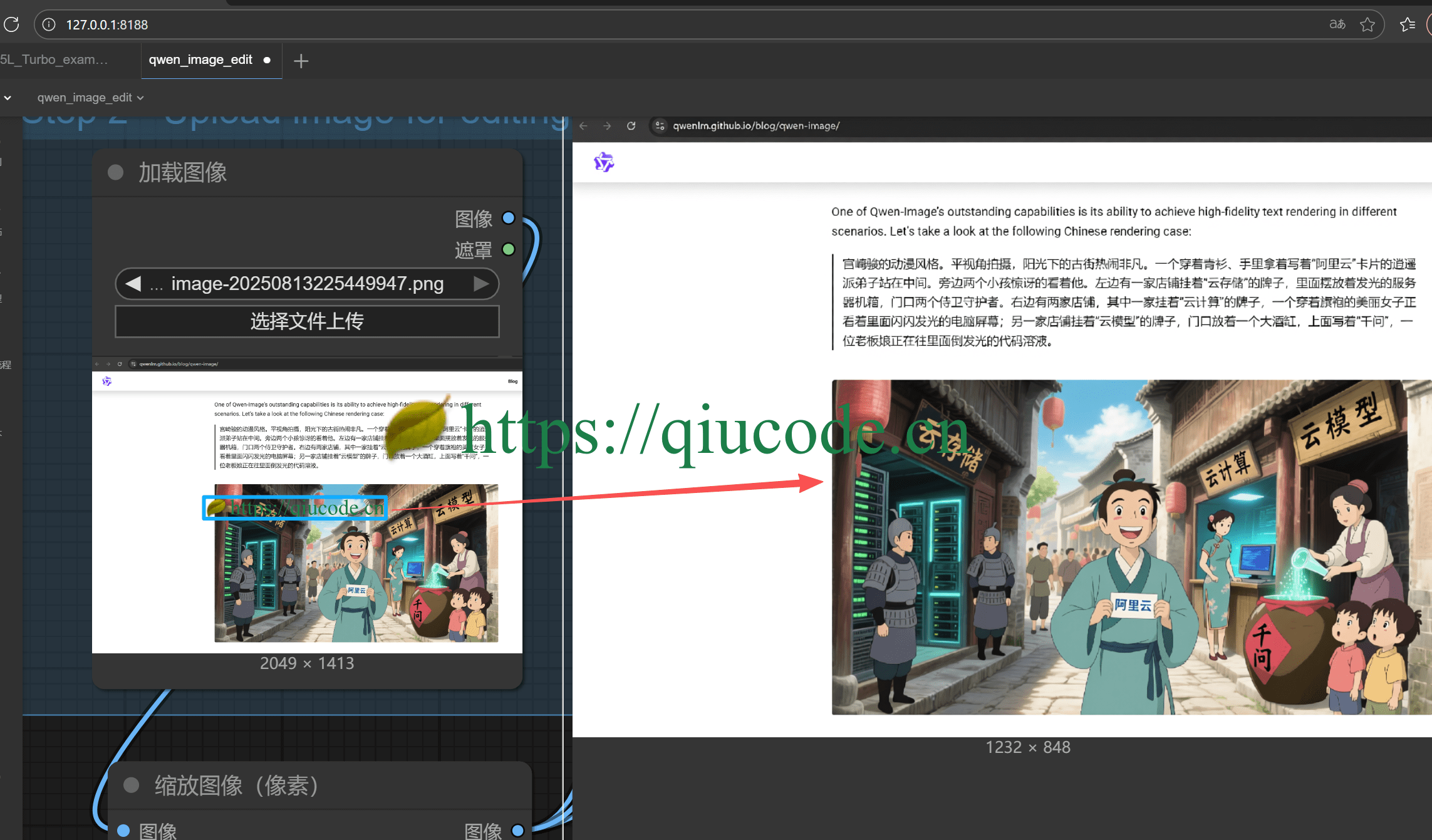
哇塞,最终按我的意愿,去除了 https://qiucode.cn 以及那个树叶小图标的水印。
 2025-08-14 19:42:43 +0800 +0800
2025-08-14 19:42:43 +0800 +0800 2025-02-25 22:26:43 +0800 +0800
2025-02-25 22:26:43 +0800 +0800 2025-04-18 22:42:43 +0800 +0800
2025-04-18 22:42:43 +0800 +0800 2025-04-10 23:02:43 +0800 +0800
2025-04-10 23:02:43 +0800 +0800 2025-04-01 23:02:43 +0800 +0800
2025-04-01 23:02:43 +0800 +0800