
在开源 TTS(文本转语音)界,情感控制一直是科研与实际应用追求的目标。然而,当 Resemble AI 提出的 Chatterbox 宣称自己是「第一个支持情感夸张控制的开源 TTS 模型」时,我们该如何审视这项说法的准确性,又该如何展现它真正的创新所在?
一、情感控制:开源 TTS 项目的竞争图谱
实际上,在 Chatterbox 之前,已有多个开源项目在“情感控制”层面做出了重要探索:
EmoSphere-TTS(INTERSPEECH 2024 官方实现)
EmotiVoice(网易有道,2024)
- 提供离线开源引擎,支持中文和英文,可使用情绪标签(如“开心”“激动”“悲伤”“愤怒”)控制语调与情绪表达。GitHub
其他探索类工具和基础组件
- 包含 Coqui TTS、ESPnet TTS、Mozilla TTS 等框架,它们支持通过调节音高、音量、速度等参数来生成情绪化语音。Reddit
最新研究成果
- 包括 EmoVoice(LLM + 自然语言情绪提示控制)、EmoSteer-TTS(训练自由的激活引导方式)、EmoMix(情绪混合与强度调控)、EmoKnob(克隆 + 情绪细致调控)等研究,为开源情感 TTS 系带来更多可能。arXiv+3arXiv+3arXiv+3
结论:Chatterbox 并非历史上第一个拥有情感控制能力的开源 TTS。但它的情绪“夸张度”滑块是一种独特且易用的控制方式。
二、Chatterbox 的真正卖点:更直观、更生产力
1. 「情感夸张度(emotion exaggeration)旋钮」
- Chatterbox 将复杂的情绪表现提取为一个用户可调节的单参数滑块,从「冷静」到「夸张」,让用户更容易定制。(官网与 README 均强调该功能)GitHubchatterbox.run
2. 面向生产的用户体验
- 安装简便:支持 pip,一行代码启动。
- 实时化:延迟低于 200ms,适合在线服务、互动式应用。Resemble AIchatterbox.run
3. 零样本语音克隆 + 多语言支持
- 支持仅用少量参考音进行克隆,无需训练即可生成个性化声音。
- 官方页面提及支持“23+”语言,让它更适配全球多语内容生成。Resemble AI
4. 水印保障:PerTh 隐形音频水印
- 嵌入人耳不易察觉但可精确检测的水印,支持追责与内容溯源,即使经过压缩剪辑也能识别。chatterbox.run
5. 质量方面
- 宣称优于 ElevenLabs,在盲测中获得更高偏好率(约 63.75% 的听众更喜欢 Chatterbox 输出)。chatterbox.run
三、本地部署(基于 windows 系统下)
虽然官方是在 Debain 11系统下进行测试,但 windows系统下也是可以把玩的,唯一不足的便是,目前 chatterbox 只支持 英语。
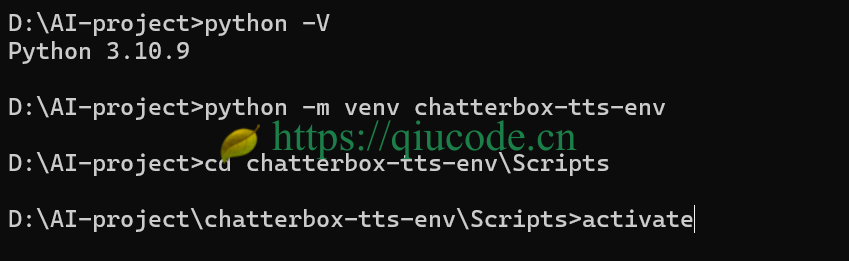
按官方的要求,python 版本得在 3.11 及以上,然而我的电脑已经装有 python3.10.9 了,故而,索性就选用它了。
我使用的是 python 3自带的虚拟模块,来搭建 python 的虚拟环境。
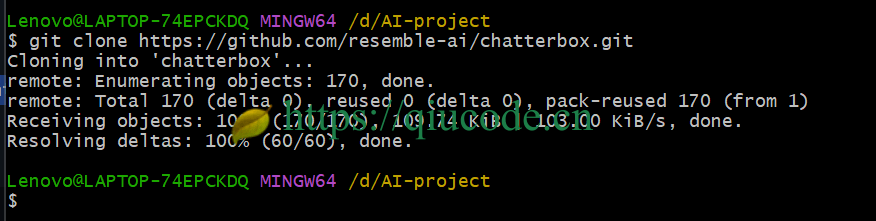
随后,将 chatterbox 推理代码 clone 下来。
git clone https://github.com/resemble-ai/chatterbox.git
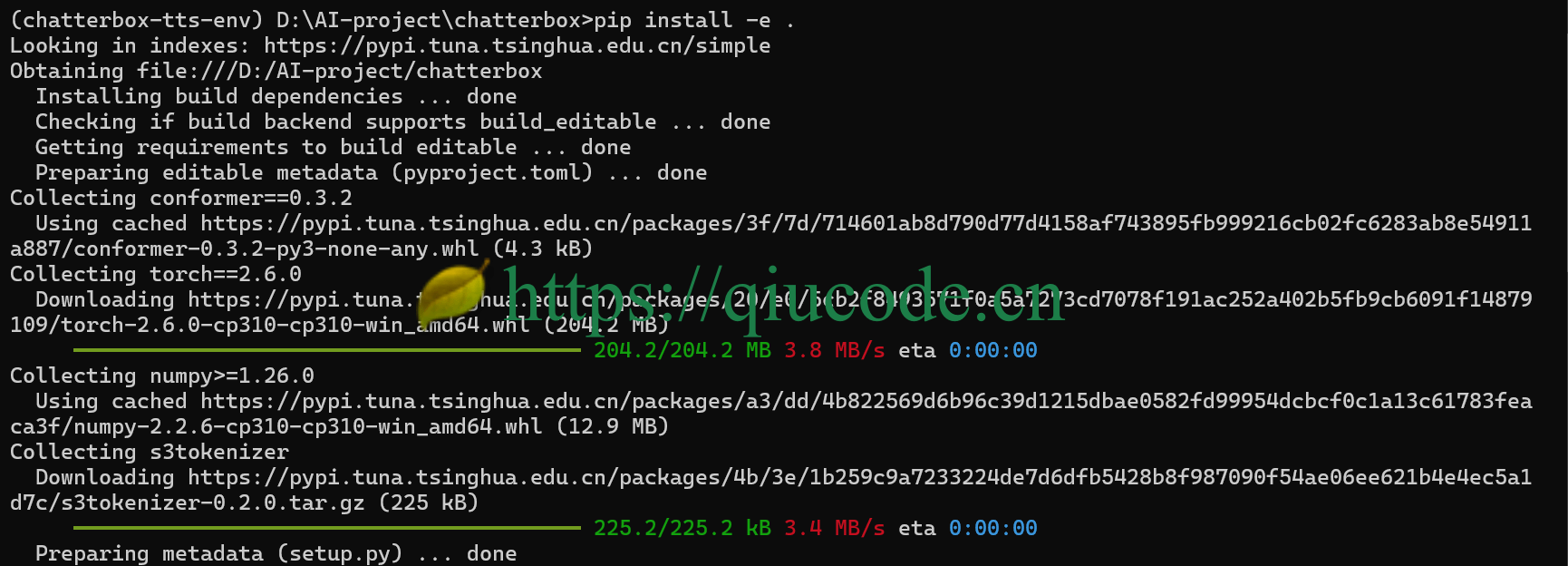
之后,使用以下命令安装项目的所需依赖。
pip install -e .
当依赖安装完成后,运行项目根路径下的 example_tts.py 文件。
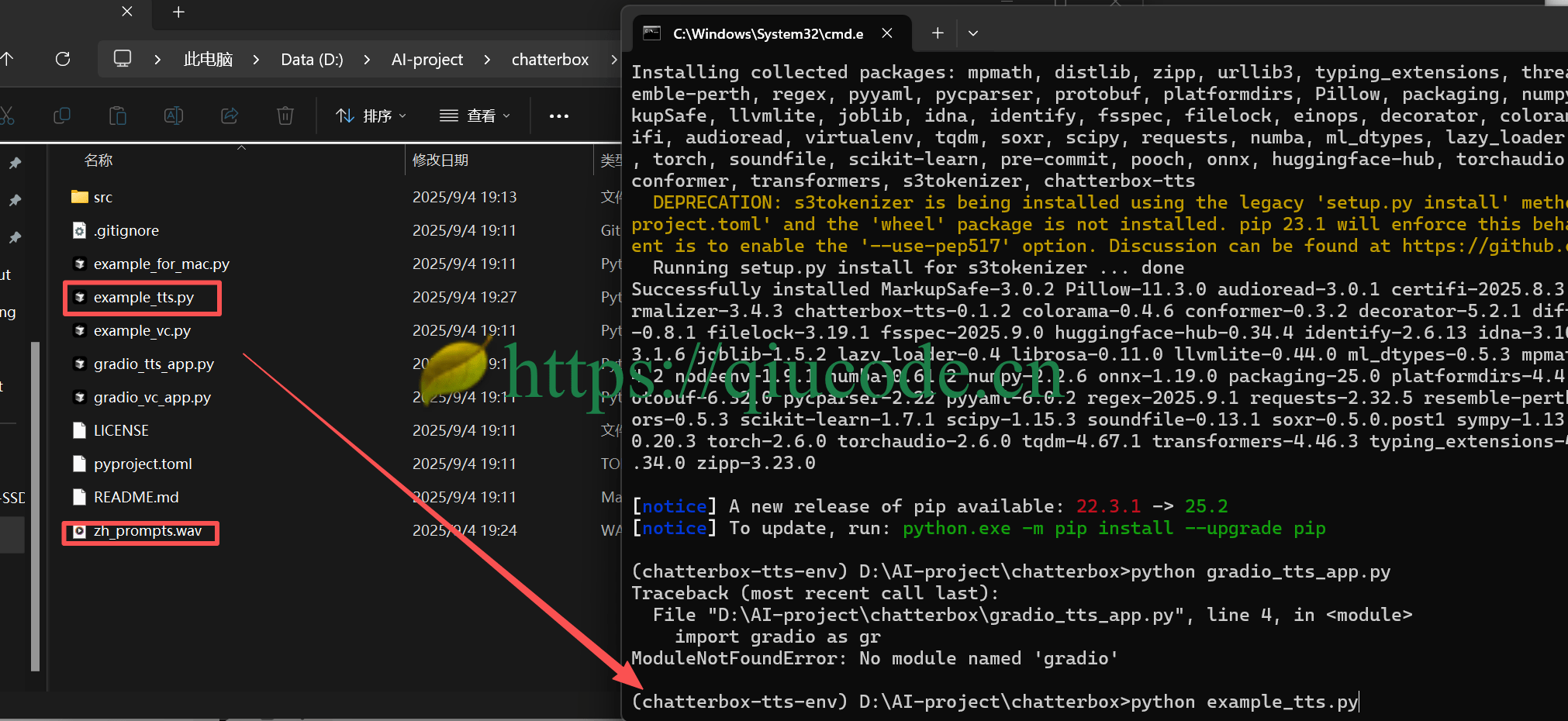
首次,会先下载模型。(会从 hugging face 网站上下载,所以得确保网络)
前面安装的依赖环境是 cpu,也就是说 chatterbox可以在 CPU环境下运行。
 2025-04-10 23:02:43 +0800 +0800
2025-04-10 23:02:43 +0800 +0800 2025-08-20 18:37:43 +0800 +0800
2025-08-20 18:37:43 +0800 +0800 2025-08-14 19:42:43 +0800 +0800
2025-08-14 19:42:43 +0800 +0800 2025-04-18 22:42:43 +0800 +0800
2025-04-18 22:42:43 +0800 +0800 2025-04-01 23:02:43 +0800 +0800
2025-04-01 23:02:43 +0800 +0800