
过去一周,AI 生图圈发生了两件颇具戏剧性的事情:
1️⃣ Flux2 开源了,号称第二代旗舰文生图模型。 2️⃣ Z-Image bf16 量化版悄然支持 Windows 本地部署。
结果很明显—— Flux2 开源了,社区反应平淡; Z-Image 本地部署了,几乎全网惊呼:“这是普通人能跑的旗舰模型!”
🧊 一、Flux2:开源了,却离普通用户太远
Flux2 由原 Flux 团队开发,本身技术能力不容置疑,但其开源策略与用户实际能力产生了巨大的落差:
- 显存要求:最低 48GB,旗舰配置 80GB
- 本地部署成本:Linux + 高端 GPU + 一堆依赖
- 出图速度:即使在 48GB 显卡上,单张也可能耗时 10–60 秒
对绝大多数普通创作者来说:
“你开源得再好,我也跑不动。”
社区吐槽如潮:
- “开源个寂寞”
- “我连下载都点了,但我知道我跑不动”
- “这不是给用户开源,这是给科研实验室开源”
一句话总结:Flux2 开源了,但没人能真正用起来。
🔥 二、Z-Image bf16:企业实力 + 技术优化,让本地生图触手可及
与此同时,另一边出现了一个实力派选手:
Z-Image bf16 本地量化版,由 Alibaba.com 集团旗下 Tongyi Labs 开发,依托企业级技术与科研实力,通过 bf16 量化 优化模型大小和显存占用,实现 Windows 本地 16GB 显卡可用。
当我们第一次在 RTX 4060 上部署成功时,显存监控跳出:
12.7GB
单张出图:
2–3 秒
连续生成 300 张图:
稳定无崩溃
团队所有人都愣住了:
“这才是真正把 AI 生图能力带到每个人桌面上的奇迹!”
💻 三、Z-Image 量化版Windows 本地部署步骤
部署 Z-Image bf16 量化版,只需 5 分钟就能完成,真正做到零门槛:
- 1、首先,更新本地
ComfyUI到最新版本。双击运行图中红色框中的文件。

2、下载模型。https://comfyanonymous.github.io/ComfyUI_examples/z_image/

模型下载好了,放置对应的文件夹下面即可。
启动
ComfyUI并加载工作流。
将图片选中拖入到
comfy UI启动好的了的界面中。
整个体验就像雷军第一次演示小米手机:简单、惊艳、人人能用。
🥊 四、Flux2 vs Z-Image:核心指标对比
| 指标 | Flux2 | Z-Image bf16 |
|---|---|---|
| 最低显存 | 48GB | 12–14GB |
| 典型显卡 | A100/H100 | 3060/4060 |
| 出图速度 | 10–60 秒/张 | 2–3 秒/张 |
| 本地部署难度 | 高(Linux + GPU + 依赖) | 低(Windows + ComfyUI) |
| 连续生成稳定性 | 易崩溃 | 300 张以上稳定 |
| 目标用户 | 高端科研/企业 | 普通创作者/设计师/学生 |
总结:
Flux2 是实验室工具 Z-Image 是日常工具
🔥 五、为什么 Z-Image 打了整个行业一个样
- 普惠性:16GB 显卡就能跑,普通用户可用
- 速度快:秒级出图,迭代效率成倍提升
- 稳定性强:长时间批量生成无崩溃
- 部署成本低:Windows + ComfyUI + 5 分钟上手
- 安全性高:数据 100% 本地,不上传、不泄露
一句话总结:Z-Image 把旗舰级 AI 生图能力,真正交到了普通用户手里。
Flux2 开源了,却远离用户; Z-Image 不吵不闹,却狠狠打了一个样。
提示词:
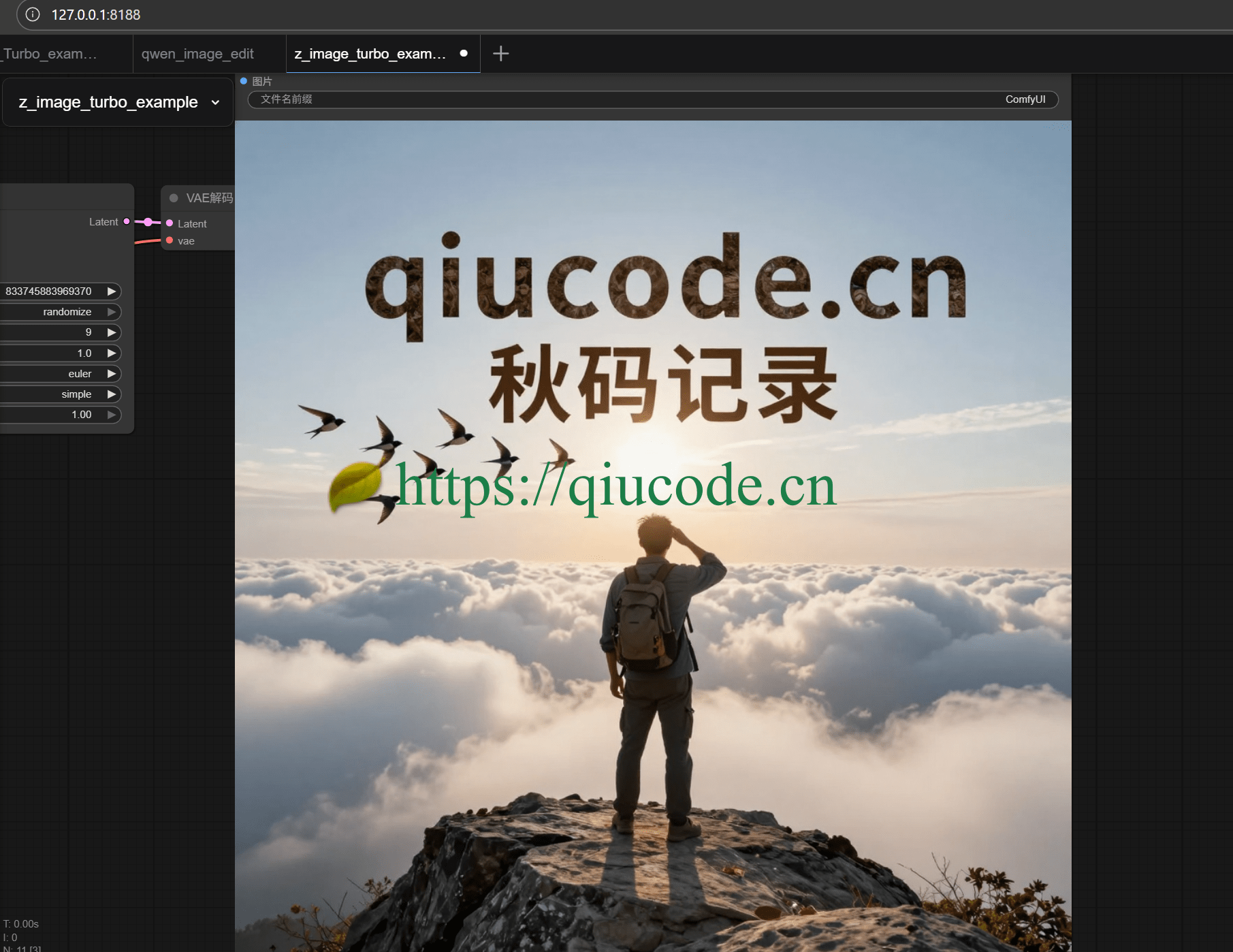
一个男子背着双肩包,站在山巅崖上一块巨大的石头上,右手搭在前额,因为此时的太阳正处于他的正前方,以此才能看清远处一朵云彩,正被飞往南方的燕子遮隐了,然而那些向南飞的燕子,似乎以云彩为背景,排列出上行为“qiucode.cn",下方则是”秋码记录“的字样。
 2025-08-14 19:42:43 +0800 +0800
2025-08-14 19:42:43 +0800 +0800 2025-03-07 21:26:43 +0800 +0800
2025-03-07 21:26:43 +0800 +0800 2025-02-16 16:26:43 +0800 +0800
2025-02-16 16:26:43 +0800 +0800 2025-09-04 20:37:43 +0800 +0800
2025-09-04 20:37:43 +0800 +0800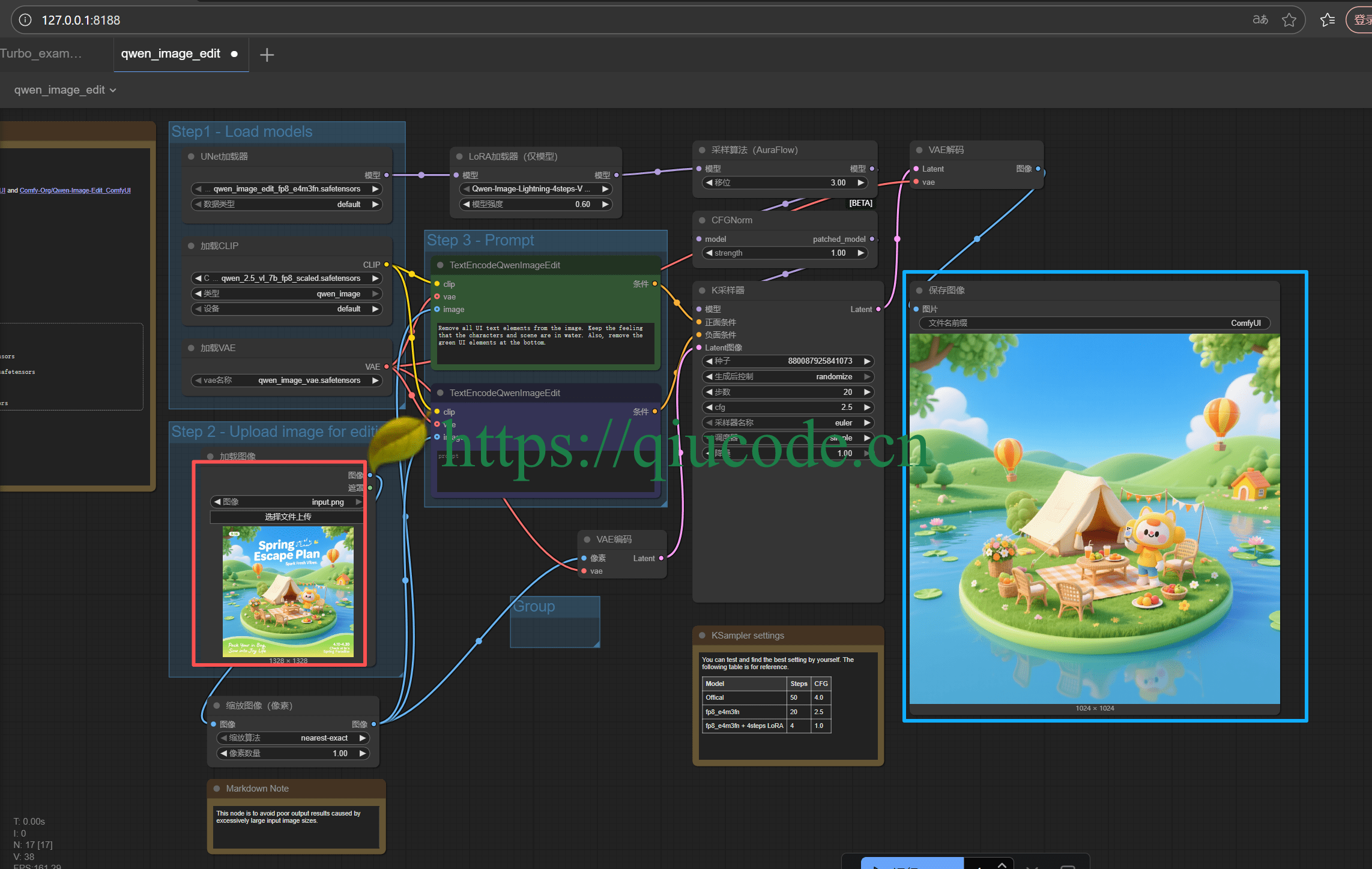 2025-08-20 18:37:43 +0800 +0800
2025-08-20 18:37:43 +0800 +0800